Encoding Brain Networks through Geodesic Clustering of Functional Connectivity for Multiple Sclerosis Classification
Muhammad Abubakar Yamin,
Valsasina Paola,
Michael Dayan,
Sebastiano Vascon,
Tessadori Jacopo,
Filippi Massimo,
Vittorio Murino,
A Rocca Maria,
Diego Sona

Auto-TLDR; Geodesic Clustering of Connectivity Matrices for Multiple Sclerosis Classification
Similar papers
Tensor Factorization of Brain Structural Graph for Unsupervised Classification in Multiple Sclerosis
Berardino Barile, Marzullo Aldo, Claudio Stamile, Françoise Durand-Dubief, Dominique Sappey-Marinier

Auto-TLDR; A Fully Automated Tensor-based Algorithm for Multiple Sclerosis Classification based on Structural Connectivity Graph of the White Matter Network
Abstract Slides Poster Similar
A Riemannian Framework for Detecting Stimulus-Relevant Fiber Pathways
Jingyong Su, Linlin Tang, Zhipeng Yang, Mengmeng Guo

Auto-TLDR; Clustering Task-Specific Fiber Pathways in Functional MRI using BOLD Signals
FMRI Brain Networks As Statistical Mechanical Ensembles
Jianjia Wang, Hui Wu, Edwin Hancock

Auto-TLDR; Microcanonical Ensemble Methods for FMRI Brain Networks for Alzheimer's Disease
Abstract Slides Poster Similar
Nonlinear Ranking Loss on Riemannian Potato Embedding
Byung Hyung Kim, Yoonje Suh, Honggu Lee, Sungho Jo

Auto-TLDR; Riemannian Potato for Rank-based Metric Learning
Abstract Slides Poster Similar
Sketch-Based Community Detection Via Representative Node Sampling
Mahlagha Sedghi, Andre Beckus, George Atia

Auto-TLDR; Sketch-based Clustering of Community Detection Using a Small Sketch
Abstract Slides Poster Similar
Estimating Static and Dynamic Brain Networks by Kulback-Leibler Divergence from fMRI Data
Gonul Degirmendereli, Fatos Yarman Vural

Auto-TLDR; A Novel method to estimate static and dynamic brain networks using Kulback- Leibler divergence using fMRI data
Improved Time-Series Clustering with UMAP Dimension Reduction Method
Clément Pealat, Vincent Cheutet, Guillaume Bouleux

Auto-TLDR; Time Series Clustering with UMAP as a Pre-processing Step
Abstract Slides Poster Similar
A Novel Computer-Aided Diagnostic System for Early Assessment of Hepatocellular Carcinoma
Ahmed Alksas, Mohamed Shehata, Gehad Saleh, Ahmed Shaffie, Ahmed Soliman, Mohammed Ghazal, Hadil Abukhalifeh, Abdel Razek Ahmed, Ayman El-Baz

Auto-TLDR; Classification of Liver Tumor Lesions from CE-MRI Using Structured Structural Features and Functional Features
Abstract Slides Poster Similar
Temporal Pattern Detection in Time-Varying Graphical Models
Federico Tomasi, Veronica Tozzo, Annalisa Barla

Auto-TLDR; A dynamical network inference model that leverages on kernels to consider general temporal patterns
Abstract Slides Poster Similar
Longitudinal Feature Selection and Feature Learning for Parkinson’s Disease Diagnosis and Prediction
Haijun Lei, Zhongwei Huang, Xiaohua Xiao, Yi Lei, En-Leng Tan, Baiying Lei, Shiqi Li

Auto-TLDR; Joint Learning from Multiple Modalities and Relations for Joint Disease Diagnosis and Prediction in Parkinson's Disease
Abstract Slides Poster Similar
A New Geodesic-Based Feature for Characterization of 3D Shapes: Application to Soft Tissue Organ Temporal Deformations
Karim Makki, Amine Bohi, Augustin Ogier, Marc-Emmanuel Bellemare

Auto-TLDR; Spatio-Temporal Feature Descriptors for 3D Shape Characterization from Point Clouds
Abstract Slides Poster Similar
N2D: (Not Too) Deep Clustering Via Clustering the Local Manifold of an Autoencoded Embedding
Ryan Mcconville, Raul Santos-Rodriguez, Robert Piechocki, Ian Craddock

Auto-TLDR; Local Manifold Learning for Deep Clustering on Autoencoded Embeddings
Automatic Estimation of Self-Reported Pain by Interpretable Representations of Motion Dynamics
Benjamin Szczapa, Mohammed Daoudi, Stefano Berretti, Pietro Pala, Zakia Hammal, Alberto Del Bimbo

Auto-TLDR; Automatic Pain Intensity Measurement from Facial Points Using Gram Matrices
Abstract Slides Poster Similar
Wasserstein k-Means with Sparse Simplex Projection
Takumi Fukunaga, Hiroyuki Kasai

Auto-TLDR; SSPW $k$-means: Sparse Simplex Projection-based Wasserstein $ k$-Means Algorithm
Abstract Slides Poster Similar
PowerHC: Non Linear Normalization of Distances for Advanced Nearest Neighbor Classification
Manuele Bicego, Mauricio Orozco-Alzate
Auto-TLDR; Non linear scaling of distances for advanced nearest neighbor classification
Abstract Slides Poster Similar
Thermal Characterisation of Unweighted and Weighted Networks
Jianjia Wang, Hui Wu, Edwin Hancock

Auto-TLDR; Thermodynamic Characterisation of Networks as Particles of the Thermal System
Abstract Slides Poster Similar
Subspace Clustering for Action Recognition with Covariance Representations and Temporal Pruning
Giancarlo Paoletti, Jacopo Cavazza, Cigdem Beyan, Alessio Del Bue

Auto-TLDR; Unsupervised Learning for Human Action Recognition from Skeletal Data
On Learning Random Forests for Random Forest Clustering
Manuele Bicego, Francisco Escolano

Auto-TLDR; Learning Random Forests for Clustering
Abstract Slides Poster Similar
A Bayesian Deep CNN Framework for Reconstructing K-T-Undersampled Resting-fMRI
Karan Taneja, Prachi Kulkarni, Shabbir Merchant, Suyash Awate

Auto-TLDR; K-t undersampled R-fMRI Reconstruction using Deep Convolutional Neural Networks
Abstract Slides Poster Similar
Learning Dictionaries of Kinematic Primitives for Action Classification
Alessia Vignolo, Nicoletta Noceti, Alessandra Sciutti, Francesca Odone, Giulio Sandini

Auto-TLDR; Action Understanding using Visual Motion Primitives
Abstract Slides Poster Similar
3D Facial Matching by Spiral Convolutional Metric Learning and a Biometric Fusion-Net of Demographic Properties
Soha Sadat Mahdi, Nele Nauwelaers, Philip Joris, Giorgos Bouritsas, Imperial London, Sergiy Bokhnyak, Susan Walsh, Mark Shriver, Michael Bronstein, Peter Claes

Auto-TLDR; Multi-biometric Fusion for Biometric Verification using 3D Facial Mesures
Deep Convolutional Embedding for Digitized Painting Clustering
Giovanna Castellano, Gennaro Vessio

Auto-TLDR; A Deep Convolutional Embedding Model for Clustering Artworks
Abstract Slides Poster Similar
One Step Clustering Based on A-Contrario Framework for Detection of Alterations in Historical Violins
Alireza Rezaei, Sylvie Le Hégarat-Mascle, Emanuel Aldea, Piercarlo Dondi, Marco Malagodi

Auto-TLDR; A-Contrario Clustering for the Detection of Altered Violins using UVIFL Images
Abstract Slides Poster Similar
A Novel Adaptive Minority Oversampling Technique for Improved Classification in Data Imbalanced Scenarios
Ayush Tripathi, Rupayan Chakraborty, Sunil Kumar Kopparapu

Auto-TLDR; Synthetic Minority OverSampling Technique for Imbalanced Data
Abstract Slides Poster Similar
Probabilistic Word Embeddings in Kinematic Space
Adarsh Jamadandi, Rishabh Tigadoli, Ramesh Ashok Tabib, Uma Mudenagudi

Auto-TLDR; Kinematic Space for Hierarchical Representation Learning
Abstract Slides Poster Similar
Weakly Supervised Geodesic Segmentation of Egyptian Mummy CT Scans
Avik Hati, Matteo Bustreo, Diego Sona, Vittorio Murino, Alessio Del Bue

Auto-TLDR; A Weakly Supervised and Efficient Interactive Segmentation of Ancient Egyptian Mummies CT Scans Using Geodesic Distance Measure and GrabCut
Abstract Slides Poster Similar
Learning Embeddings for Image Clustering: An Empirical Study of Triplet Loss Approaches
Kalun Ho, Janis Keuper, Franz-Josef Pfreundt, Margret Keuper

Auto-TLDR; Clustering Objectives for K-means and Correlation Clustering Using Triplet Loss
Abstract Slides Poster Similar
An Invariance-Guided Stability Criterion for Time Series Clustering Validation
Florent Forest, Alex Mourer, Mustapha Lebbah, Hanane Azzag, Jérôme Lacaille

Auto-TLDR; An invariance-guided method for clustering model selection in time series data
Abstract Slides Poster Similar
Exploring Spatial-Temporal Representations for fNIRS-based Intimacy Detection via an Attention-enhanced Cascade Convolutional Recurrent Neural Network
Chao Li, Qian Zhang, Ziping Zhao

Auto-TLDR; Intimate Relationship Prediction by Attention-enhanced Cascade Convolutional Recurrent Neural Network Using Functional Near-Infrared Spectroscopy
Abstract Slides Poster Similar
Deep Transfer Learning for Alzheimer’s Disease Detection
Nicole Cilia, Claudio De Stefano, Francesco Fontanella, Claudio Marrocco, Mario Molinara, Alessandra Scotto Di Freca

Auto-TLDR; Automatic Detection of Handwriting Alterations for Alzheimer's Disease Diagnosis using Dynamic Features
Abstract Slides Poster Similar
Local Binary Quaternion Rotation Pattern for Colour Texture Retrieval
Hela Jebali, Noel Richard, Mohamed Naouai
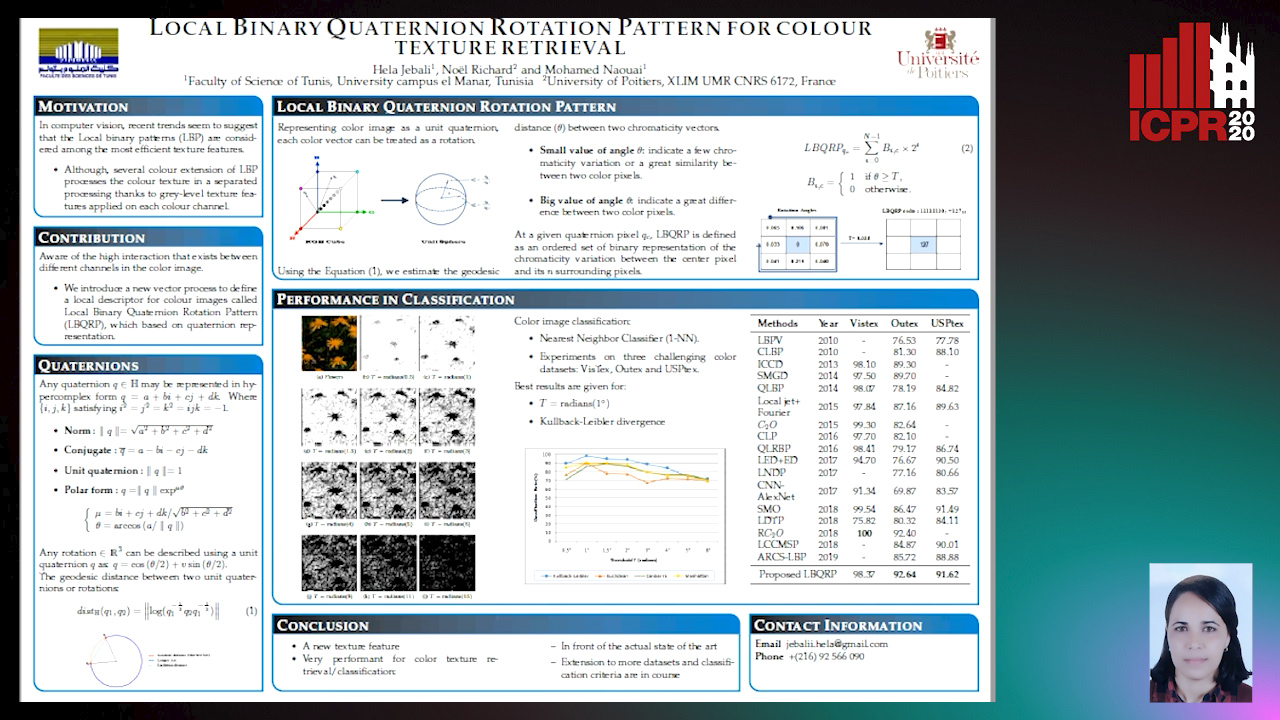
Auto-TLDR; Local Binary Quaternion Rotation Pattern for Color Texture Classification
A Multi-Task Multi-View Based Multi-Objective Clustering Algorithm

Auto-TLDR; MTMV-MO: Multi-task multi-view multi-objective optimization for multi-task clustering
Abstract Slides Poster Similar
Comparison of Stacking-Based Classifier Ensembles Using Euclidean and Riemannian Geometries
Vitaliy Tayanov, Adam Krzyzak, Ching Y Suen

Auto-TLDR; Classifier Stacking in Riemannian Geometries using Cascades of Random Forest and Extra Trees
Abstract Slides Poster Similar
Motion Segmentation with Pairwise Matches and Unknown Number of Motions
Federica Arrigoni, Tomas Pajdla, Luca Magri

Auto-TLDR; Motion Segmentation using Multi-Modelfitting andpermutation synchronization
Abstract Slides Poster Similar
Penalized K-Means Algorithms for Finding the Number of Clusters
Behzad Kamgar-Parsi, Behrooz Kamgar-Parsi

Auto-TLDR; Exploring the coefficient of additive penalty in k-means for ideal clusters
Abstract Slides Poster Similar
A Novel Random Forest Dissimilarity Measure for Multi-View Learning
Hongliu Cao, Simon Bernard, Robert Sabourin, Laurent Heutte

Auto-TLDR; Multi-view Learning with Random Forest Relation Measure and Instance Hardness
Abstract Slides Poster Similar
Detecting Rare Cell Populations in Flow Cytometry Data Using UMAP
Lisa Weijler, Markus Diem, Michael Reiter

Auto-TLDR; Unsupervised Manifold Approximation and Projection for Small Cell Population Detection in Flow cytometry Data
Abstract Slides Poster Similar
A General End-To-End Method for Characterizing Neuropsychiatric Disorders Using Free-Viewing Visual Scanning Tasks
Hong Yue Sean Liu, Jonathan Chung, Moshe Eizenman

Auto-TLDR; A general, data-driven, end-to-end framework that extracts relevant features of attentional bias from visual scanning behaviour and uses these features
Abstract Slides Poster Similar
A Deep Learning Approach for the Segmentation of Myocardial Diseases
Khawala Brahim, Abdull Qayyum, Alain Lalande, Arnaud Boucher, Anis Sakly, Fabrice Meriaudeau

Auto-TLDR; Segmentation of Myocardium Infarction Using Late GADEMRI and SegU-Net
Abstract Slides Poster Similar
Graph Signal Active Contours

Auto-TLDR; Adaptation of Active Contour Without Edges for Graph Signal Processing
Electroencephalography Signal Processing Based on Textural Features for Monitoring the Driver’s State by a Brain-Computer Interface
Giulia Orrù, Marco Micheletto, Fabio Terranova, Gian Luca Marcialis

Auto-TLDR; One-dimensional Local Binary Pattern Algorithm for Estimating Driver Vigilance in a Brain-Computer Interface System
Abstract Slides Poster Similar
Transfer Learning with Graph Neural Networks for Short-Term Highway Traffic Forecasting
Tanwi Mallick, Prasanna Balaprakash, Eric Rask, Jane Macfarlane

Auto-TLDR; Transfer Learning for Highway Traffic Forecasting on Unseen Traffic Networks
Abstract Slides Poster Similar
Unconstrained Vision Guided UAV Based Safe Helicopter Landing
Arindam Sikdar, Abhimanyu Sahu, Debajit Sen, Rohit Mahajan, Ananda Chowdhury

Auto-TLDR; Autonomous Helicopter Landing in Hazardous Environments from Unmanned Aerial Images Using Constrained Graph Clustering
Abstract Slides Poster Similar
Supervised Feature Embedding for Classification by Learning Rank-Based Neighborhoods
Ghazaal Sheikhi, Hakan Altincay

Auto-TLDR; Supervised Feature Embedding with Representation Learning of Rank-based Neighborhoods
One-Shot Learning for Acoustic Identification of Bird Species in Non-Stationary Environments
Michelangelo Acconcjaioco, Stavros Ntalampiras

Auto-TLDR; One-shot Learning in the Bioacoustics Domain using Siamese Neural Networks
Abstract Slides Poster Similar
Automatic Tuberculosis Detection Using Chest X-Ray Analysis with Position Enhanced Structural Information
Hermann Jepdjio Nkouanga, Szilard Vajda

Auto-TLDR; Automatic Chest X-ray Screening for Tuberculosis in Rural Population using Localized Region on Interest
Abstract Slides Poster Similar
Classification and Feature Selection Using a Primal-Dual Method and Projections on Structured Constraints
Michel Barlaud, Antonin Chambolle, Jean_Baptiste Caillau

Auto-TLDR; A Constrained Primal-dual Method for Structured Feature Selection on High Dimensional Data
Abstract Slides Poster Similar
Weakly Supervised Learning through Rank-Based Contextual Measures
João Gabriel Camacho Presotto, Lucas Pascotti Valem, Nikolas Gomes De Sá, Daniel Carlos Guimaraes Pedronette, Joao Paulo Papa

Auto-TLDR; Exploiting Unlabeled Data for Weakly Supervised Classification of Multimedia Data
Abstract Slides Poster Similar