Comparison of Stacking-Based Classifier Ensembles Using Euclidean and Riemannian Geometries
Vitaliy Tayanov,
Adam Krzyzak,
Ching Y Suen

Auto-TLDR; Classifier Stacking in Riemannian Geometries using Cascades of Random Forest and Extra Trees
Similar papers
Decision Snippet Features
Pascal Welke, Fouad Alkhoury, Christian Bauckhage, Stefan Wrobel

Auto-TLDR; Decision Snippet Features for Interpretability
Abstract Slides Poster Similar
Nonlinear Ranking Loss on Riemannian Potato Embedding
Byung Hyung Kim, Yoonje Suh, Honggu Lee, Sungho Jo

Auto-TLDR; Riemannian Potato for Rank-based Metric Learning
Abstract Slides Poster Similar
A Novel Random Forest Dissimilarity Measure for Multi-View Learning
Hongliu Cao, Simon Bernard, Robert Sabourin, Laurent Heutte

Auto-TLDR; Multi-view Learning with Random Forest Relation Measure and Instance Hardness
Abstract Slides Poster Similar
MD-kNN: An Instance-Based Approach for Multi-Dimensional Classification

Auto-TLDR; MD-kNN: Adapting Instance-based Techniques for Multi-dimensional Classification
Abstract Slides Poster Similar
Classifier Pool Generation Based on a Two-Level Diversity Approach
Marcos Monteiro, Alceu Britto, Jean Paul Barddal, Luiz Oliveira, Robert Sabourin

Auto-TLDR; Diversity-Based Pool Generation with Dynamic Classifier Selection and Dynamic Ensemble Selection
Abstract Slides Poster Similar
Learning Recurrent High-Order Statistics for Skeleton-Based Hand Gesture Recognition
Xuan Son Nguyen, Luc Brun, Olivier Lezoray, Sébastien Bougleux
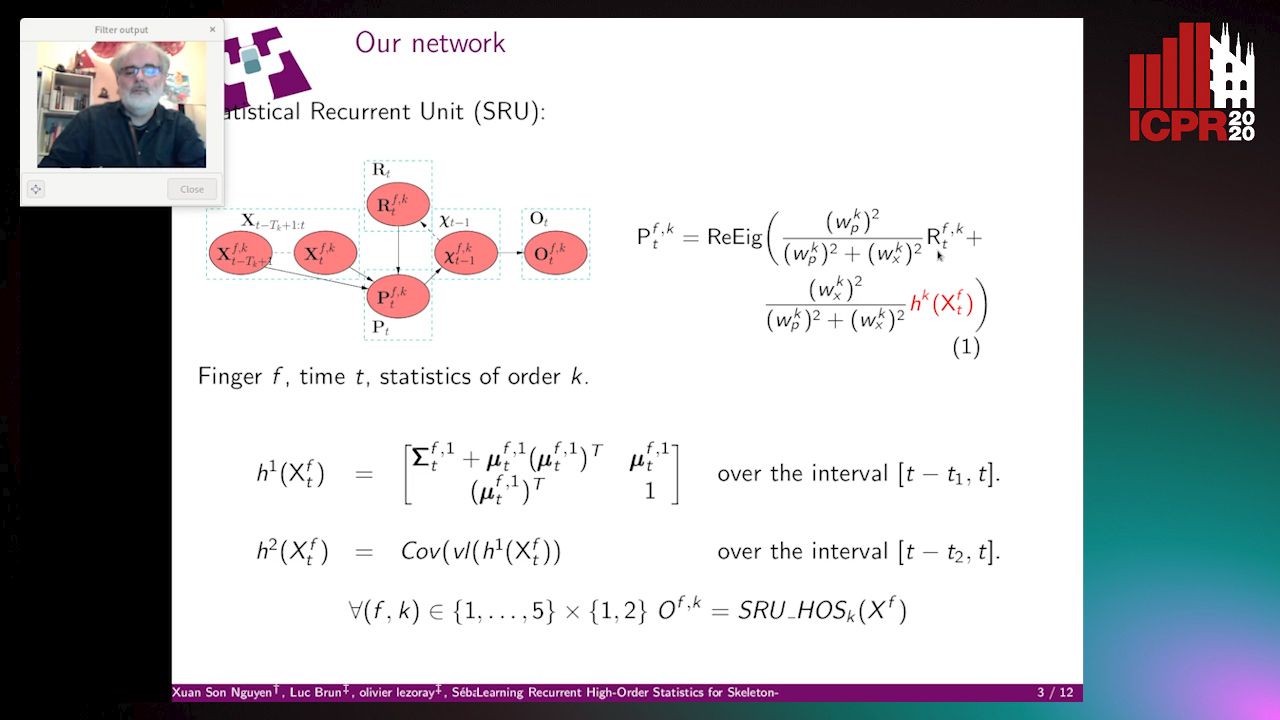
Auto-TLDR; Exploiting High-Order Statistics in Recurrent Neural Networks for Hand Gesture Recog-nition
On Learning Random Forests for Random Forest Clustering
Manuele Bicego, Francisco Escolano

Auto-TLDR; Learning Random Forests for Clustering
Abstract Slides Poster Similar
Mean Decision Rules Method with Smart Sampling for Fast Large-Scale Binary SVM Classification
Alexandra Makarova, Mikhail Kurbakov, Valentina Sulimova

Auto-TLDR; Improving Mean Decision Rule for Large-Scale Binary SVM Problems
Abstract Slides Poster Similar
Explainable Online Validation of Machine Learning Models for Practical Applications
Wolfgang Fuhl, Yao Rong, Thomas Motz, Michael Scheidt, Andreas Markus Hartel, Andreas Koch, Enkelejda Kasneci

Auto-TLDR; A Reformulation of Regression and Classification for Machine Learning Algorithm Validation
Abstract Slides Poster Similar
Algorithm Recommendation for Data Streams
Jáder Martins Camboim De Sá, Andre Luis Debiaso Rossi, Gustavo Enrique De Almeida Prado Alves Batista, Luís Paulo Faina Garcia

Auto-TLDR; Meta-Learning for Algorithm Selection in Time-Changing Data Streams
Abstract Slides Poster Similar
Using Meta Labels for the Training of Weighting Models in a Sample-Specific Late Fusion Classification Architecture
Peter Bellmann, Patrick Thiam, Friedhelm Schwenker

Auto-TLDR; A Late Fusion Architecture for Multiple Classifier Systems
Abstract Slides Poster Similar
Categorizing the Feature Space for Two-Class Imbalance Learning
Rosa Sicilia, Ermanno Cordelli, Paolo Soda

Auto-TLDR; Efficient Ensemble of Classifiers for Minority Class Inference
Abstract Slides Poster Similar
Hierarchical Routing Mixture of Experts
Wenbo Zhao, Yang Gao, Shahan Ali Memon, Bhiksha Raj, Rita Singh

Auto-TLDR; A Binary Tree-structured Hierarchical Routing Mixture of Experts for Regression
Abstract Slides Poster Similar
Boundary Bagging to Address Training Data Issues in Ensemble Classification
Auto-TLDR; Bagging Ensemble Learning for Multi-Class Imbalanced Classification
Memetic Evolution of Training Sets with Adaptive Radial Basis Kernels for Support Vector Machines
Jakub Nalepa, Wojciech Dudzik, Michal Kawulok

Auto-TLDR; Memetic Algorithm for Evolving Support Vector Machines with Adaptive Kernels
Abstract Slides Poster Similar
Improved Time-Series Clustering with UMAP Dimension Reduction Method
Clément Pealat, Vincent Cheutet, Guillaume Bouleux

Auto-TLDR; Time Series Clustering with UMAP as a Pre-processing Step
Abstract Slides Poster Similar
Proximity Isolation Forests
Antonella Mensi, Manuele Bicego, David Tax

Auto-TLDR; Proximity Isolation Forests for Non-vectorial Data
Abstract Slides Poster Similar
Supervised Classification Using Graph-Based Space Partitioning for Multiclass Problems
Nicola Yanev, Ventzeslav Valev, Adam Krzyzak, Karima Ben Suliman

Auto-TLDR; Box Classifier for Multiclass Classification
Abstract Slides Poster Similar
Probabilistic Word Embeddings in Kinematic Space
Adarsh Jamadandi, Rishabh Tigadoli, Ramesh Ashok Tabib, Uma Mudenagudi

Auto-TLDR; Kinematic Space for Hierarchical Representation Learning
Abstract Slides Poster Similar
Space-Time Domain Tensor Neural Networks: An Application on Human Pose Classification
Konstantinos Makantasis, Athanasios Voulodimos, Anastasios Doulamis, Nikolaos Doulamis, Nikolaos Bakalos

Auto-TLDR; Tensor-Based Neural Network for Spatiotemporal Pose Classifiaction using Three-Dimensional Skeleton Data
Abstract Slides Poster Similar
Automatic Estimation of Self-Reported Pain by Interpretable Representations of Motion Dynamics
Benjamin Szczapa, Mohammed Daoudi, Stefano Berretti, Pietro Pala, Zakia Hammal, Alberto Del Bimbo

Auto-TLDR; Automatic Pain Intensity Measurement from Facial Points Using Gram Matrices
Abstract Slides Poster Similar
Creating Classifier Ensembles through Meta-Heuristic Algorithms for Aerial Scene Classification
Álvaro Roberto Ferreira Jr., Gustavo Gustavo Henrique De Rosa, Joao Paulo Papa, Gustavo Carneiro, Fabio Augusto Faria

Auto-TLDR; Univariate Marginal Distribution Algorithm for Aerial Scene Classification Using Meta-Heuristic Optimization
Abstract Slides Poster Similar
Kernel-based Graph Convolutional Networks

Auto-TLDR; Spatial Graph Convolutional Networks in Recurrent Kernel Hilbert Space
Abstract Slides Poster Similar
Encoding Brain Networks through Geodesic Clustering of Functional Connectivity for Multiple Sclerosis Classification
Muhammad Abubakar Yamin, Valsasina Paola, Michael Dayan, Sebastiano Vascon, Tessadori Jacopo, Filippi Massimo, Vittorio Murino, A Rocca Maria, Diego Sona

Auto-TLDR; Geodesic Clustering of Connectivity Matrices for Multiple Sclerosis Classification
Abstract Slides Poster Similar
Aggregating Dependent Gaussian Experts in Local Approximation

Auto-TLDR; A novel approach for aggregating the Gaussian experts by detecting strong violations of conditional independence
Abstract Slides Poster Similar
Deep Transfer Learning for Alzheimer’s Disease Detection
Nicole Cilia, Claudio De Stefano, Francesco Fontanella, Claudio Marrocco, Mario Molinara, Alessandra Scotto Di Freca

Auto-TLDR; Automatic Detection of Handwriting Alterations for Alzheimer's Disease Diagnosis using Dynamic Features
Abstract Slides Poster Similar
3D Facial Matching by Spiral Convolutional Metric Learning and a Biometric Fusion-Net of Demographic Properties
Soha Sadat Mahdi, Nele Nauwelaers, Philip Joris, Giorgos Bouritsas, Imperial London, Sergiy Bokhnyak, Susan Walsh, Mark Shriver, Michael Bronstein, Peter Claes

Auto-TLDR; Multi-biometric Fusion for Biometric Verification using 3D Facial Mesures
Low Rank Representation on Product Grassmann Manifolds for Multi-viewSubspace Clustering
Jipeng Guo, Yanfeng Sun, Junbin Gao, Yongli Hu, Baocai Yin

Auto-TLDR; Low Rank Representation on Product Grassmann Manifold for Multi-View Data Clustering
Abstract Slides Poster Similar
Exploring Seismocardiogram Biometrics with Wavelet Transform
Po-Ya Hsu, Po-Han Hsu, Hsin-Li Liu

Auto-TLDR; Seismocardiogram Biometric Matching Using Wavelet Transform and Deep Learning Models
Abstract Slides Poster Similar
Automatic Tuberculosis Detection Using Chest X-Ray Analysis with Position Enhanced Structural Information
Hermann Jepdjio Nkouanga, Szilard Vajda

Auto-TLDR; Automatic Chest X-ray Screening for Tuberculosis in Rural Population using Localized Region on Interest
Abstract Slides Poster Similar
Supervised Feature Embedding for Classification by Learning Rank-Based Neighborhoods
Ghazaal Sheikhi, Hakan Altincay

Auto-TLDR; Supervised Feature Embedding with Representation Learning of Rank-based Neighborhoods
Killing Four Birds with One Gaussian Process: The Relation between Different Test-Time Attacks
Kathrin Grosse, Michael Thomas Smith, Michael Backes

Auto-TLDR; Security of Gaussian Process Classifiers against Attack Algorithms
Abstract Slides Poster Similar
Watermelon: A Novel Feature Selection Method Based on Bayes Error Rate Estimation and a New Interpretation of Feature Relevance and Redundancy

Auto-TLDR; Feature Selection Using Bayes Error Rate Estimation for Dynamic Feature Selection
Abstract Slides Poster Similar
Automatic Classification of Human Granulosa Cells in Assisted Reproductive Technology Using Vibrational Spectroscopy Imaging
Marina Paolanti, Emanuele Frontoni, Giorgia Gioacchini, Giorgini Elisabetta, Notarstefano Valentina, Zacà Carlotta, Carnevali Oliana, Andrea Borini, Marco Mameli

Auto-TLDR; Predicting Oocyte Quality in Assisted Reproductive Technology Using Machine Learning Techniques
Abstract Slides Poster Similar
An Adaptive Video-To-Video Face Identification System Based on Self-Training
Eric Lopez-Lopez, Carlos V. Regueiro, Xosé M. Pardo

Auto-TLDR; Adaptive Video-to-Video Face Recognition using Dynamic Ensembles of SVM's
Abstract Slides Poster Similar
Learning Connectivity with Graph Convolutional Networks

Auto-TLDR; Learning Graph Convolutional Networks Using Topological Properties of Graphs
Abstract Slides Poster Similar
Local Propagation for Few-Shot Learning
Yann Lifchitz, Yannis Avrithis, Sylvaine Picard

Auto-TLDR; Local Propagation for Few-Shot Inference
Abstract Slides Poster Similar
A Spectral Clustering on Grassmann Manifold Via Double Low Rank Constraint
Xinglin Piao, Yongli Hu, Junbin Gao, Yanfeng Sun, Xin Yang, Baocai Yin

Auto-TLDR; Double Low Rank Representation for High-Dimensional Data Clustering on Grassmann Manifold
N2D: (Not Too) Deep Clustering Via Clustering the Local Manifold of an Autoencoded Embedding
Ryan Mcconville, Raul Santos-Rodriguez, Robert Piechocki, Ian Craddock

Auto-TLDR; Local Manifold Learning for Deep Clustering on Autoencoded Embeddings
The eXPose Approach to Crosslier Detection
Antonio Barata, Frank Takes, Hendrik Van Den Herik, Cor Veenman

Auto-TLDR; EXPose: Crosslier Detection Based on Supervised Category Modeling
Abstract Slides Poster Similar
A Distinct Discriminant Canonical Correlation Analysis Network Based Deep Information Quality Representation for Image Classification
Lei Gao, Zheng Guo, Ling Guan Ling Guan

Auto-TLDR; DDCCANet: Deep Information Quality Representation for Image Classification
Abstract Slides Poster Similar
Tensorized Feature Spaces for Feature Explosion
Ravdeep Pasricha, Pravallika Devineni, Evangelos Papalexakis, Ramakrishnan Kannan

Auto-TLDR; Tensor Rank Decomposition for Hyperspectral Image Classification
Abstract Slides Poster Similar
2D Deep Video Capsule Network with Temporal Shift for Action Recognition
Théo Voillemin, Hazem Wannous, Jean-Philippe Vandeborre

Auto-TLDR; Temporal Shift Module over Capsule Network for Action Recognition in Continuous Videos
Temporal Binary Representation for Event-Based Action Recognition
Simone Undri Innocenti, Federico Becattini, Federico Pernici, Alberto Del Bimbo

Auto-TLDR; Temporal Binary Representation for Gesture Recognition
Abstract Slides Poster Similar
Comparison of Deep Learning and Hand Crafted Features for Mining Simulation Data
Theodoros Georgiou, Sebastian Schmitt, Thomas Baeck, Nan Pu, Wei Chen, Michael Lew

Auto-TLDR; Automated Data Analysis of Flow Fields in Computational Fluid Dynamics Simulations
Abstract Slides Poster Similar
PowerHC: Non Linear Normalization of Distances for Advanced Nearest Neighbor Classification
Manuele Bicego, Mauricio Orozco-Alzate
Auto-TLDR; Non linear scaling of distances for advanced nearest neighbor classification
Abstract Slides Poster Similar
A Close Look at Deep Learning with Small Data

Auto-TLDR; Low-Complex Neural Networks for Small Data Conditions
Abstract Slides Poster Similar
Attribute-Based Quality Assessment for Demographic Estimation in Face Videos
Fabiola Becerra-Riera, Annette Morales-González, Heydi Mendez-Vazquez, Jean-Luc Dugelay

Auto-TLDR; Facial Demographic Estimation in Video Scenarios Using Quality Assessment