Probabilistic Word Embeddings in Kinematic Space
Adarsh Jamadandi,
Rishabh Tigadoli,
Ramesh Ashok Tabib,
Uma Mudenagudi

Auto-TLDR; Kinematic Space for Hierarchical Representation Learning
Similar papers
Improved Time-Series Clustering with UMAP Dimension Reduction Method
Clément Pealat, Vincent Cheutet, Guillaume Bouleux

Auto-TLDR; Time Series Clustering with UMAP as a Pre-processing Step
Abstract Slides Poster Similar
N2D: (Not Too) Deep Clustering Via Clustering the Local Manifold of an Autoencoded Embedding
Ryan Mcconville, Raul Santos-Rodriguez, Robert Piechocki, Ian Craddock

Auto-TLDR; Local Manifold Learning for Deep Clustering on Autoencoded Embeddings
Graph Approximations to Geodesics on Metric Graphs
Robin Vandaele, Yvan Saeys, Tijl De Bie

Auto-TLDR; Topological Pattern Recognition of Metric Graphs Using Proximity Graphs
Abstract Slides Poster Similar
Auto Encoding Explanatory Examples with Stochastic Paths
Cesar Ali Ojeda Marin, Ramses J. Sanchez, Kostadin Cvejoski, Bogdan Georgiev

Auto-TLDR; Semantic Stochastic Path: Explaining a Classifier's Decision Making Process using latent codes
Abstract Slides Poster Similar
Interpolation in Auto Encoders with Bridge Processes
Carl Ringqvist, Henrik Hult, Judith Butepage, Hedvig Kjellstrom

Auto-TLDR; Stochastic interpolations from auto encoders trained on flattened sequences
Abstract Slides Poster Similar
Equation Attention Relationship Network (EARN) : A Geometric Deep Metric Framework for Learning Similar Math Expression Embedding
Saleem Ahmed, Kenny Davila, Srirangaraj Setlur, Venu Govindaraju

Auto-TLDR; Representational Learning for Similarity Based Retrieval of Mathematical Expressions
Abstract Slides Poster Similar
Nonlinear Ranking Loss on Riemannian Potato Embedding
Byung Hyung Kim, Yoonje Suh, Honggu Lee, Sungho Jo

Auto-TLDR; Riemannian Potato for Rank-based Metric Learning
Abstract Slides Poster Similar
3CS Algorithm for Efficient Gaussian Process Model Retrieval
Fabian Berns, Kjeld Schmidt, Ingolf Bracht, Christian Beecks

Auto-TLDR; Efficient retrieval of Gaussian Process Models for large-scale data using divide-&-conquer-based approach
Abstract Slides Poster Similar
3D Facial Matching by Spiral Convolutional Metric Learning and a Biometric Fusion-Net of Demographic Properties
Soha Sadat Mahdi, Nele Nauwelaers, Philip Joris, Giorgos Bouritsas, Imperial London, Sergiy Bokhnyak, Susan Walsh, Mark Shriver, Michael Bronstein, Peter Claes

Auto-TLDR; Multi-biometric Fusion for Biometric Verification using 3D Facial Mesures
Region and Relations Based Multi Attention Network for Graph Classification
Manasvi Aggarwal, M. Narasimha Murty

Auto-TLDR; R2POOL: A Graph Pooling Layer for Non-euclidean Structures
Abstract Slides Poster Similar
Deep Transformation Models: Tackling Complex Regression Problems with Neural Network Based Transformation Models
Beate Sick, Torsten Hothorn, Oliver Dürr

Auto-TLDR; A Deep Transformation Model for Probabilistic Regression
Abstract Slides Poster Similar
Epitomic Variational Graph Autoencoder
Rayyan Ahmad Khan, Muhammad Umer Anwaar, Martin Kleinsteuber

Auto-TLDR; EVGAE: A Generative Variational Autoencoder for Graph Data
Abstract Slides Poster Similar
Low Rank Representation on Product Grassmann Manifolds for Multi-viewSubspace Clustering
Jipeng Guo, Yanfeng Sun, Junbin Gao, Yongli Hu, Baocai Yin

Auto-TLDR; Low Rank Representation on Product Grassmann Manifold for Multi-View Data Clustering
Abstract Slides Poster Similar
Encoding Brain Networks through Geodesic Clustering of Functional Connectivity for Multiple Sclerosis Classification
Muhammad Abubakar Yamin, Valsasina Paola, Michael Dayan, Sebastiano Vascon, Tessadori Jacopo, Filippi Massimo, Vittorio Murino, A Rocca Maria, Diego Sona

Auto-TLDR; Geodesic Clustering of Connectivity Matrices for Multiple Sclerosis Classification
Abstract Slides Poster Similar
Comparison of Stacking-Based Classifier Ensembles Using Euclidean and Riemannian Geometries
Vitaliy Tayanov, Adam Krzyzak, Ching Y Suen

Auto-TLDR; Classifier Stacking in Riemannian Geometries using Cascades of Random Forest and Extra Trees
Abstract Slides Poster Similar
Adaptive Sampling of Pareto Frontiers with Binary Constraints Using Regression and Classification

Auto-TLDR; Adaptive Optimization for Black-Box Multi-Objective Optimizing Problems with Binary Constraints
Sketch-Based Community Detection Via Representative Node Sampling
Mahlagha Sedghi, Andre Beckus, George Atia

Auto-TLDR; Sketch-based Clustering of Community Detection Using a Small Sketch
Abstract Slides Poster Similar
A Joint Representation Learning and Feature Modeling Approach for One-Class Recognition
Pramuditha Perera, Vishal Patel

Auto-TLDR; Combining Generative Features and One-Class Classification for Effective One-class Recognition
Abstract Slides Poster Similar
Revisiting Graph Neural Networks: Graph Filtering Perspective
Hoang Nguyen-Thai, Takanori Maehara, Tsuyoshi Murata

Auto-TLDR; Two-Layers Graph Convolutional Network with Graph Filters Neural Network
Abstract Slides Poster Similar
MEG: Multi-Evidence GNN for Multimodal Semantic Forensics
Ekraam Sabir, Ayush Jaiswal, Wael Abdalmageed, Prem Natarajan

Auto-TLDR; Scalable Image Repurposing Detection with Graph Neural Network Based Model
Abstract Slides Poster Similar
AVAE: Adversarial Variational Auto Encoder
Antoine Plumerault, Hervé Le Borgne, Celine Hudelot

Auto-TLDR; Combining VAE and GAN for Realistic Image Generation
Abstract Slides Poster Similar
RNN Training along Locally Optimal Trajectories via Frank-Wolfe Algorithm
Yun Yue, Ming Li, Venkatesh Saligrama, Ziming Zhang

Auto-TLDR; Frank-Wolfe Algorithm for Efficient Training of RNNs
Abstract Slides Poster Similar
A General Model for Learning Node and Graph Representations Jointly

Auto-TLDR; Joint Community Detection/Dynamic Routing for Graph Classification
Abstract Slides Poster Similar
Probabilistic Latent Factor Model for Collaborative Filtering with Bayesian Inference
Jiansheng Fang, Xiaoqing Zhang, Yan Hu, Yanwu Xu, Ming Yang, Jiang Liu

Auto-TLDR; Bayesian Latent Factor Model for Collaborative Filtering
Feature-Aware Unsupervised Learning with Joint Variational Attention and Automatic Clustering
Wang Ru, Lin Li, Peipei Wang, Liu Peiyu

Auto-TLDR; Deep Variational Attention Encoder-Decoder for Clustering
Abstract Slides Poster Similar
Efficient Sentence Embedding Via Semantic Subspace Analysis
Bin Wang, Fenxiao Chen, Yun Cheng Wang, C.-C. Jay Kuo

Auto-TLDR; S3E: Semantic Subspace Sentence Embedding
Abstract Slides Poster Similar
Social Network Analysis Using Knowledge-Graph Embeddings and Convolution Operations
Bonaventure Chidube Molokwu, Shaon Bhatta Shuvo, Ziad Kobti, Narayan C. Kar

Auto-TLDR; RLVECO: Representation Learning via Knowledge- Graph Embeddings and Convolution Operations for Social Network Analysis
Abstract Slides Poster Similar
A New Geodesic-Based Feature for Characterization of 3D Shapes: Application to Soft Tissue Organ Temporal Deformations
Karim Makki, Amine Bohi, Augustin Ogier, Marc-Emmanuel Bellemare

Auto-TLDR; Spatio-Temporal Feature Descriptors for 3D Shape Characterization from Point Clouds
Abstract Slides Poster Similar
Variational Deep Embedding Clustering by Augmented Mutual Information Maximization
Qiang Ji, Yanfeng Sun, Yongli Hu, Baocai Yin

Auto-TLDR; Clustering by Augmented Mutual Information maximization for Deep Embedding
Abstract Slides Poster Similar
Stochastic Runge-Kutta Methods and Adaptive SGD-G2 Stochastic Gradient Descent

Auto-TLDR; Adaptive Stochastic Runge Kutta for the Minimization of the Loss Function
Abstract Slides Poster Similar
A Hybrid Metric Based on Persistent Homology and Its Application to Signal Classification
Austin Lawson, Yu-Min Chung, William Cruse

Auto-TLDR; Topological Data Analysis with Persistence Curves
Graph Signal Active Contours

Auto-TLDR; Adaptation of Active Contour Without Edges for Graph Signal Processing
Local Binary Quaternion Rotation Pattern for Colour Texture Retrieval
Hela Jebali, Noel Richard, Mohamed Naouai
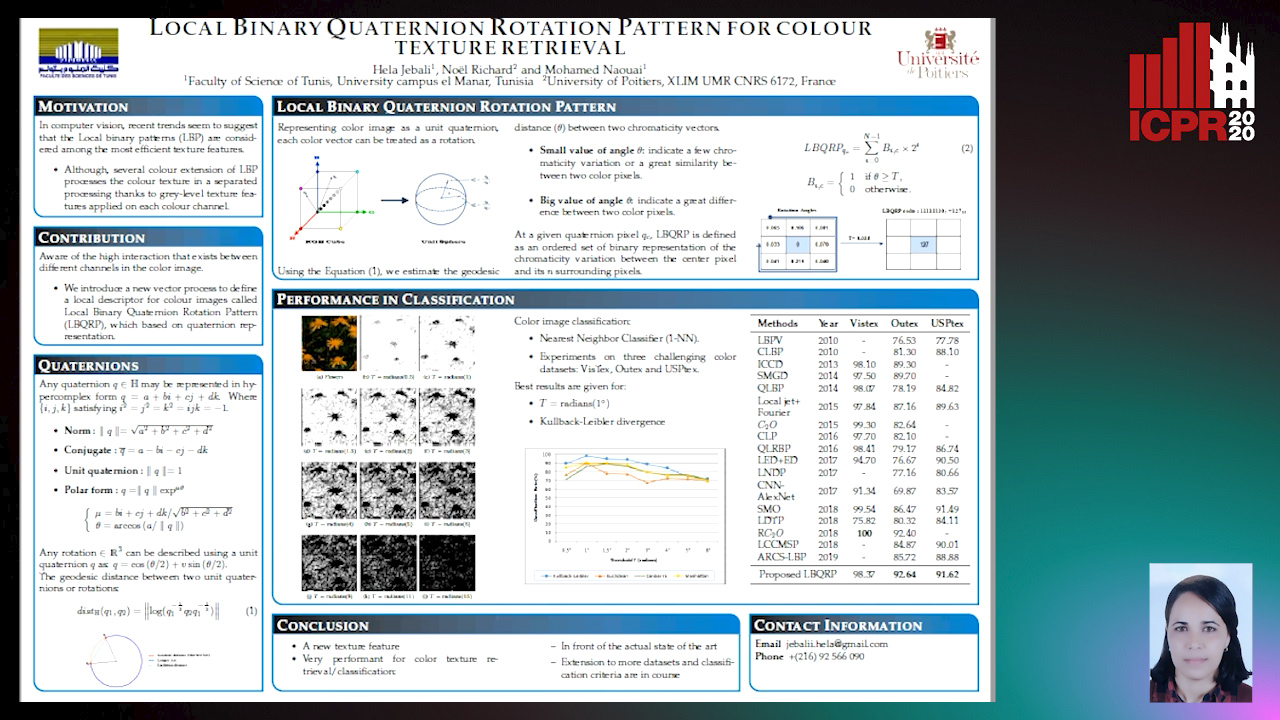
Auto-TLDR; Local Binary Quaternion Rotation Pattern for Color Texture Classification
Learning Sign-Constrained Support Vector Machines
Kenya Tajima, Kouhei Tsuchida, Esmeraldo Ronnie Rey Zara, Naoya Ohta, Tsuyoshi Kato

Auto-TLDR; Constrained Sign Constraints for Learning Linear Support Vector Machine
Directional Graph Networks with Hard Weight Assignments
Miguel Dominguez, Raymond Ptucha

Auto-TLDR; Hard Directional Graph Networks for Point Cloud Analysis
Abstract Slides Poster Similar
Separation of Aleatoric and Epistemic Uncertainty in Deterministic Deep Neural Networks
Denis Huseljic, Bernhard Sick, Marek Herde, Daniel Kottke

Auto-TLDR; AE-DNN: Modeling Uncertainty in Deep Neural Networks
Abstract Slides Poster Similar
Transferable Model for Shape Optimization subject to Physical Constraints
Lukas Harsch, Johannes Burgbacher, Stefan Riedelbauch

Auto-TLDR; U-Net with Spatial Transformer Network for Flow Simulations
Abstract Slides Poster Similar
TreeRNN: Topology-Preserving Deep Graph Embedding and Learning
Yecheng Lyu, Ming Li, Xinming Huang, Ulkuhan Guler, Patrick Schaumont, Ziming Zhang

Auto-TLDR; TreeRNN: Recurrent Neural Network for General Graph Classification
Abstract Slides Poster Similar
Dimensionality Reduction for Data Visualization and Linear Classification, and the Trade-Off between Robustness and Classification Accuracy
Martin Becker, Jens Lippel, Thomas Zielke

Auto-TLDR; Robustness Assessment of Deep Autoencoder for Data Visualization using Scatter Plots
Abstract Slides Poster Similar
Interpretable Structured Learning with Sparse Gated Sequence Encoder for Protein-Protein Interaction Prediction
Kishan K C, Feng Cui, Anne Haake, Rui Li

Auto-TLDR; Predicting Protein-Protein Interactions Using Sequence Representations
Abstract Slides Poster Similar
Label Incorporated Graph Neural Networks for Text Classification
Yuan Xin, Linli Xu, Junliang Guo, Jiquan Li, Xin Sheng, Yuanyuan Zhou

Auto-TLDR; Graph Neural Networks for Semi-supervised Text Classification
Abstract Slides Poster Similar
Signature Features with the Visibility Transformation
Yue Wu, Hao Ni, Terry Lyons, Robin Hudson

Auto-TLDR; The Visibility Transformation for Pattern Recognition
Abstract Slides Poster Similar
An Invariance-Guided Stability Criterion for Time Series Clustering Validation
Florent Forest, Alex Mourer, Mustapha Lebbah, Hanane Azzag, Jérôme Lacaille

Auto-TLDR; An invariance-guided method for clustering model selection in time series data
Abstract Slides Poster Similar
Temporally Coherent Embeddings for Self-Supervised Video Representation Learning
Joshua Knights, Ben Harwood, Daniel Ward, Anthony Vanderkop, Olivia Mackenzie-Ross, Peyman Moghadam

Auto-TLDR; Temporally Coherent Embeddings for Self-supervised Video Representation Learning
Abstract Slides Poster Similar
Evaluation of Anomaly Detection Algorithms for the Real-World Applications
Marija Ivanovska, Domen Tabernik, Danijel Skocaj, Janez Pers

Auto-TLDR; Evaluating Anomaly Detection Algorithms for Practical Applications
Abstract Slides Poster Similar
Explorable Tone Mapping Operators
Su Chien-Chuan, Yu-Lun Liu, Hung Jin Lin, Ren Wang, Chia-Ping Chen, Yu-Lin Chang, Soo-Chang Pei

Auto-TLDR; Learning-based multimodal tone-mapping from HDR images
Abstract Slides Poster Similar
On the Global Self-attention Mechanism for Graph Convolutional Networks

Auto-TLDR; Global Self-Attention Mechanism for Graph Convolutional Networks
Local Clustering with Mean Teacher for Semi-Supervised Learning
Zexi Chen, Benjamin Dutton, Bharathkumar Ramachandra, Tianfu Wu, Ranga Raju Vatsavai

Auto-TLDR; Local Clustering for Semi-supervised Learning