Transferable Model for Shape Optimization subject to Physical Constraints
Lukas Harsch,
Johannes Burgbacher,
Stefan Riedelbauch

Auto-TLDR; U-Net with Spatial Transformer Network for Flow Simulations
Similar papers
Inferring Functional Properties from Fluid Dynamics Features
Andrea Schillaci, Maurizio Quadrio, Carlotta Pipolo, Marcello Restelli, Giacomo Boracchi

Auto-TLDR; Exploiting Convective Properties of Computational Fluid Dynamics for Medical Diagnosis
Abstract Slides Poster Similar
A New Geodesic-Based Feature for Characterization of 3D Shapes: Application to Soft Tissue Organ Temporal Deformations
Karim Makki, Amine Bohi, Augustin Ogier, Marc-Emmanuel Bellemare

Auto-TLDR; Spatio-Temporal Feature Descriptors for 3D Shape Characterization from Point Clouds
Abstract Slides Poster Similar
Comparison of Deep Learning and Hand Crafted Features for Mining Simulation Data
Theodoros Georgiou, Sebastian Schmitt, Thomas Baeck, Nan Pu, Wei Chen, Michael Lew

Auto-TLDR; Automated Data Analysis of Flow Fields in Computational Fluid Dynamics Simulations
Abstract Slides Poster Similar
Understanding When Spatial Transformer Networks Do Not Support Invariance, and What to Do about It
Lukas Finnveden, Ylva Jansson, Tony Lindeberg

Auto-TLDR; Spatial Transformer Networks are unable to support invariance when transforming CNN feature maps
Abstract Slides Poster Similar
Learning Non-Rigid Surface Reconstruction from Spatio-Temporal Image Patches
Matteo Pedone, Abdelrahman Mostafa, Janne Heikkilä

Auto-TLDR; Dense Spatio-Temporal Depth Maps of Deformable Objects from Video Sequences
Abstract Slides Poster Similar
Mutual Information Based Method for Unsupervised Disentanglement of Video Representation
Aditya Sreekar P, Ujjwal Tiwari, Anoop Namboodiri

Auto-TLDR; MIPAE: Mutual Information Predictive Auto-Encoder for Video Prediction
Abstract Slides Poster Similar
Reducing the Variance of Variational Estimates of Mutual Information by Limiting the Critic's Hypothesis Space to RKHS
Aditya Sreekar P, Ujjwal Tiwari, Anoop Namboodiri

Auto-TLDR; Mutual Information Estimation from Variational Lower Bounds Using a Critic's Hypothesis Space
Trainable Spectrally Initializable Matrix Transformations in Convolutional Neural Networks
Michele Alberti, Angela Botros, Schuetz Narayan, Rolf Ingold, Marcus Liwicki, Mathias Seuret

Auto-TLDR; Trainable and Spectrally Initializable Matrix Transformations for Neural Networks
Abstract Slides Poster Similar
Deep Transformation Models: Tackling Complex Regression Problems with Neural Network Based Transformation Models
Beate Sick, Torsten Hothorn, Oliver Dürr

Auto-TLDR; A Deep Transformation Model for Probabilistic Regression
Abstract Slides Poster Similar
Machine-Learned Regularization and Polygonization of Building Segmentation Masks
Stefano Zorzi, Ksenia Bittner, Friedrich Fraundorfer

Auto-TLDR; Automatic Regularization and Polygonization of Building Segmentation masks using Generative Adversarial Network
Abstract Slides Poster Similar
Sample-Aware Data Augmentor for Scene Text Recognition
Guanghao Meng, Tao Dai, Shudeng Wu, Bin Chen, Jian Lu, Yong Jiang, Shutao Xia

Auto-TLDR; Sample-Aware Data Augmentation for Scene Text Recognition
Abstract Slides Poster Similar
Improving Robotic Grasping on Monocular Images Via Multi-Task Learning and Positional Loss
William Prew, Toby Breckon, Magnus Bordewich, Ulrik Beierholm

Auto-TLDR; Improving grasping performance from monocularcolour images in an end-to-end CNN architecture with multi-task learning
Abstract Slides Poster Similar
Low Dimensional State Representation Learning with Reward-Shaped Priors
Nicolò Botteghi, Ruben Obbink, Daan Geijs, Mannes Poel, Beril Sirmacek, Christoph Brune, Abeje Mersha, Stefano Stramigioli

Auto-TLDR; Unsupervised Learning for Unsupervised Reinforcement Learning in Robotics
Convolutional STN for Weakly Supervised Object Localization
Akhil Meethal, Marco Pedersoli, Soufiane Belharbi, Eric Granger

Auto-TLDR; Spatial Localization for Weakly Supervised Object Localization
Hybrid Approach for 3D Head Reconstruction: Using Neural Networks and Visual Geometry
Oussema Bouafif, Bogdan Khomutenko, Mohammed Daoudi

Auto-TLDR; Recovering 3D Head Geometry from a Single Image using Deep Learning and Geometric Techniques
Abstract Slides Poster Similar
Meta Learning Via Learned Loss
Sarah Bechtle, Artem Molchanov, Yevgen Chebotar, Edward Thomas Grefenstette, Ludovic Righetti, Gaurav Sukhatme, Franziska Meier

Auto-TLDR; meta-learning for learning parametric loss functions that generalize across different tasks and model architectures
Total Estimation from RGB Video: On-Line Camera Self-Calibration, Non-Rigid Shape and Motion

Auto-TLDR; Joint Auto-Calibration, Pose and 3D Reconstruction of a Non-rigid Object from an uncalibrated RGB Image Sequence
Abstract Slides Poster Similar
Recovery of 2D and 3D Layout Information through an Advanced Image Stitching Algorithm Using Scanning Electron Microscope Images
Aayush Singla, Bernhard Lippmann, Helmut Graeb

Auto-TLDR; Image Stitching for True Geometrical Layout Recovery in Nanoscale Dimension
Abstract Slides Poster Similar
A Globally Optimal Method for the PnP Problem with MRP Rotation Parameterization
Manolis Lourakis, George Terzakis

Auto-TLDR; A Direct least squares, algebraic PnP solver with modified Rodrigues parameters
NetCalib: A Novel Approach for LiDAR-Camera Auto-Calibration Based on Deep Learning
Shan Wu, Amnir Hadachi, Damien Vivet, Yadu Prabhakar

Auto-TLDR; Automatic Calibration of LiDAR and Cameras using Deep Neural Network
Abstract Slides Poster Similar
Deep Space Probing for Point Cloud Analysis
Yirong Yang, Bin Fan, Yongcheng Liu, Hua Lin, Jiyong Zhang, Xin Liu, 蔡鑫宇 蔡鑫宇, Shiming Xiang, Chunhong Pan

Auto-TLDR; SPCNN: Space Probing Convolutional Neural Network for Point Cloud Analysis
Abstract Slides Poster Similar
Wireless Localisation in WiFi Using Novel Deep Architectures
Peizheng Li, Han Cui, Aftab Khan, Usman Raza, Robert Piechocki, Angela Doufexi, Tim Farnham

Auto-TLDR; Deep Neural Network for Indoor Localisation of WiFi Devices in Indoor Environments
Abstract Slides Poster Similar
Image Representation Learning by Transformation Regression
Xifeng Guo, Jiyuan Liu, Sihang Zhou, En Zhu, Shihao Dong

Auto-TLDR; Self-supervised Image Representation Learning using Continuous Parameter Prediction
Abstract Slides Poster Similar
Semi-Supervised Deep Learning Techniques for Spectrum Reconstruction
Adriano Simonetto, Vincent Parret, Alexander Gatto, Piergiorgio Sartor, Pietro Zanuttigh

Auto-TLDR; hyperspectral data estimation from RGB data using semi-supervised learning
Abstract Slides Poster Similar
Exploring the Ability of CNNs to Generalise to Previously Unseen Scales Over Wide Scale Ranges

Auto-TLDR; A theoretical analysis of invariance and covariance properties of scale channel networks
Abstract Slides Poster Similar
Self-Supervised Detection and Pose Estimation of Logistical Objects in 3D Sensor Data
Nikolas Müller, Jonas Stenzel, Jian-Jia Chen

Auto-TLDR; A self-supervised and fully automated deep learning approach for object pose estimation using simulated 3D data
Abstract Slides Poster Similar
Multiple Future Prediction Leveraging Synthetic Trajectories
Lorenzo Berlincioni, Federico Becattini, Lorenzo Seidenari, Alberto Del Bimbo

Auto-TLDR; Synthetic Trajectory Prediction using Markov Chains
Abstract Slides Poster Similar
Phase Retrieval Using Conditional Generative Adversarial Networks
Tobias Uelwer, Alexander Oberstraß, Stefan Harmeling

Auto-TLDR; Conditional Generative Adversarial Networks for Phase Retrieval
Abstract Slides Poster Similar
DAG-Net: Double Attentive Graph Neural Network for Trajectory Forecasting
Alessio Monti, Alessia Bertugli, Simone Calderara, Rita Cucchiara

Auto-TLDR; Recurrent Generative Model for Multi-modal Human Motion Behaviour in Urban Environments
Abstract Slides Poster Similar
P2D: A Self-Supervised Method for Depth Estimation from Polarimetry
Marc Blanchon, Desire Sidibe, Olivier Morel, Ralph Seulin, Daniel Braun, Fabrice Meriaudeau

Auto-TLDR; Polarimetric Regularization for Monocular Depth Estimation
Abstract Slides Poster Similar
Learning to Implicitly Represent 3D Human Body from Multi-Scale Features and Multi-View Images
Zhongguo Li, Magnus Oskarsson, Anders Heyden

Auto-TLDR; Reconstruction of 3D human bodies from multi-view images using multi-stage end-to-end neural networks
Abstract Slides Poster Similar
Resource-efficient DNNs for Keyword Spotting using Neural Architecture Search and Quantization
David Peter, Wolfgang Roth, Franz Pernkopf

Auto-TLDR; Neural Architecture Search for Keyword Spotting in Limited Resource Environments
Abstract Slides Poster Similar
Holistic Grid Fusion Based Stop Line Estimation
Runsheng Xu, Faezeh Tafazzoli, Li Zhang, Timo Rehfeld, Gunther Krehl, Arunava Seal

Auto-TLDR; Fused Multi-Sensory Data for Stop Lines Detection in Intersection Scenarios
Auto Encoding Explanatory Examples with Stochastic Paths
Cesar Ali Ojeda Marin, Ramses J. Sanchez, Kostadin Cvejoski, Bogdan Georgiev

Auto-TLDR; Semantic Stochastic Path: Explaining a Classifier's Decision Making Process using latent codes
Abstract Slides Poster Similar
Computing Stable Resultant-Based Minimal Solvers by Hiding a Variable
Snehal Bhayani, Zuzana Kukelova, Janne Heikkilä

Auto-TLDR; Sparse Permian-Based Method for Solving Minimal Systems of Polynomial Equations
Uncertainty Guided Recognition of Tiny Craters on the Moon
Thorsten Wilhelm, Christian Wöhler

Auto-TLDR; Accurately Detecting Tiny Craters in Remote Sensed Images Using Deep Neural Networks
Abstract Slides Poster Similar
Extraction and Analysis of 3D Kinematic Parameters of Table Tennis Ball from a Single Camera
Jordan Calandre, Renaud Péteri, Laurent Mascarilla, Benoit Tremblais

Auto-TLDR; 3D Ball Trajectories Analysis using a Single Camera for Sport Gesture Analysis
Abstract Slides Poster Similar
Future Urban Scenes Generation through Vehicles Synthesis
Alessandro Simoni, Luca Bergamini, Andrea Palazzi, Simone Calderara, Rita Cucchiara

Auto-TLDR; Predicting the Future of an Urban Scene with a Novel View Synthesis Paradigm
Abstract Slides Poster Similar
Position-Aware and Symmetry Enhanced GAN for Radial Distortion Correction
Yongjie Shi, Xin Tong, Jingsi Wen, He Zhao, Xianghua Ying, Jinshi Hongbin Zha

Auto-TLDR; Generative Adversarial Network for Radial Distorted Image Correction
Abstract Slides Poster Similar
MBD-GAN: Model-Based Image Deblurring with a Generative Adversarial Network

Auto-TLDR; Model-Based Deblurring GAN for Inverse Imaging
Abstract Slides Poster Similar
On Resource-Efficient Bayesian Network Classifiers and Deep Neural Networks
Wolfgang Roth, Günther Schindler, Holger Fröning, Franz Pernkopf

Auto-TLDR; Quantization-Aware Bayesian Network Classifiers for Small-Scale Scenarios
Abstract Slides Poster Similar
Incorporating a Graph-Matching Algorithm into a Muscle Mechanics Model
Jose Luis Santacruz Muñoz, Francesc Serratosa

Auto-TLDR; Recomputing the Mesh Grid for Differential Models of the Muscle Mechanics
Abstract Slides Poster Similar
JUMPS: Joints Upsampling Method for Pose Sequences
Lucas Mourot, Francois Le Clerc, Cédric Thébault, Pierre Hellier

Auto-TLDR; JUMPS: Increasing the Number of Joints in 2D Pose Estimation and Recovering Occluded or Missing Joints
Abstract Slides Poster Similar
Directional Graph Networks with Hard Weight Assignments
Miguel Dominguez, Raymond Ptucha

Auto-TLDR; Hard Directional Graph Networks for Point Cloud Analysis
Abstract Slides Poster Similar
Deep Universal Blind Image Denoising

Auto-TLDR; Image Denoising with Deep Convolutional Neural Networks
Revisiting Optical Flow Estimation in 360 Videos
Keshav Bhandari, Ziliang Zong, Yan Yan
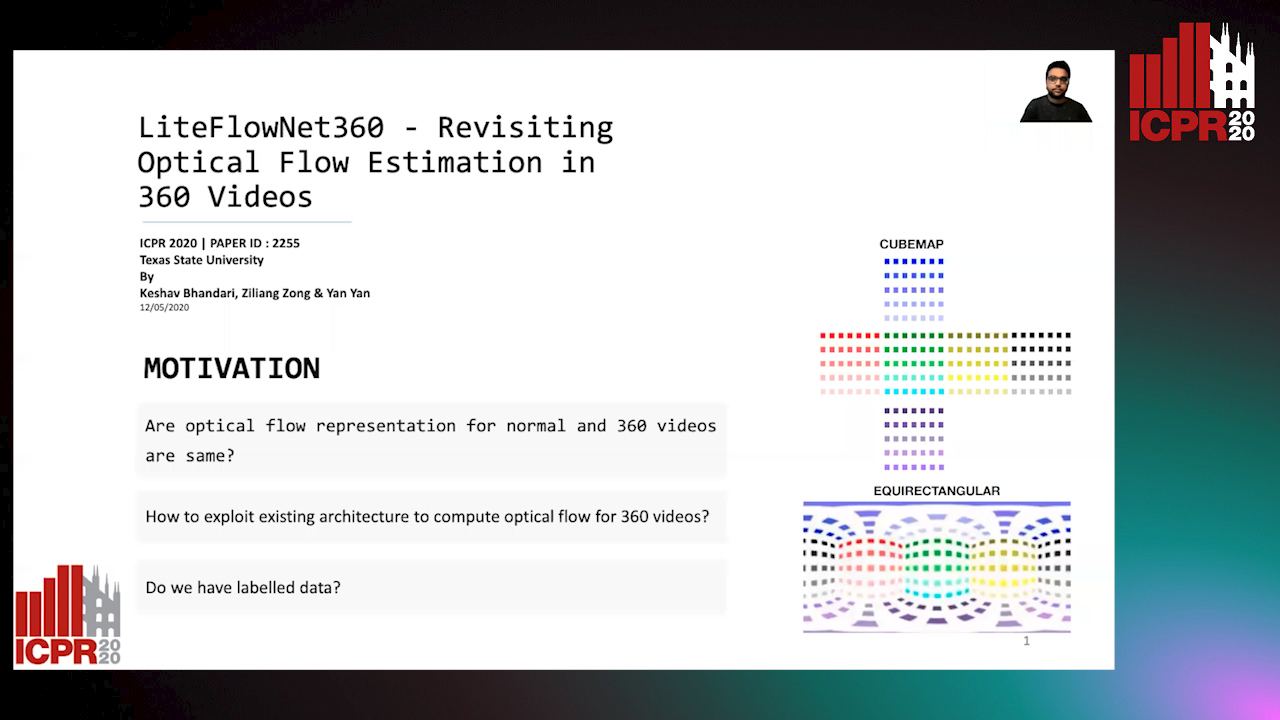
Auto-TLDR; LiteFlowNet360: A Domain Adaptation Framework for 360 Video Optical Flow Estimation
A Two-Step Approach to Lidar-Camera Calibration
Yingna Su, Yaqing Ding, Jian Yang, Hui Kong

Auto-TLDR; Closed-Form Calibration of Lidar-camera System for Ego-motion Estimation and Scene Understanding
Abstract Slides Poster Similar
Interpolation in Auto Encoders with Bridge Processes
Carl Ringqvist, Henrik Hult, Judith Butepage, Hedvig Kjellstrom

Auto-TLDR; Stochastic interpolations from auto encoders trained on flattened sequences
Abstract Slides Poster Similar