Position-Aware and Symmetry Enhanced GAN for Radial Distortion Correction
Yongjie Shi,
Xin Tong,
Jingsi Wen,
He Zhao,
Xianghua Ying,
Jinshi Hongbin Zha

Auto-TLDR; Generative Adversarial Network for Radial Distorted Image Correction
Similar papers
SIDGAN: Single Image Dehazing without Paired Supervision
Pan Wei, Xin Wang, Lei Wang, Ji Xiang, Zihan Wang

Auto-TLDR; DehazeGAN: An End-to-End Generative Adversarial Network for Image Dehazing
Abstract Slides Poster Similar
An Adaptive Model for Face Distortion Correction

Auto-TLDR; Adaptive Polynomial Model for Face Distortion Correction in Selfie Photos
MBD-GAN: Model-Based Image Deblurring with a Generative Adversarial Network

Auto-TLDR; Model-Based Deblurring GAN for Inverse Imaging
Abstract Slides Poster Similar
Efficient Shadow Detection and Removal Using Synthetic Data with Domain Adaptation
Rui Guo, Babajide Ayinde, Hao Sun

Auto-TLDR; Shadow Detection and Removal with Domain Adaptation and Synthetic Image Database
GAN-Based Image Deblurring Using DCT Discriminator
Hiroki Tomosada, Takahiro Kudo, Takanori Fujisawa, Masaaki Ikehara
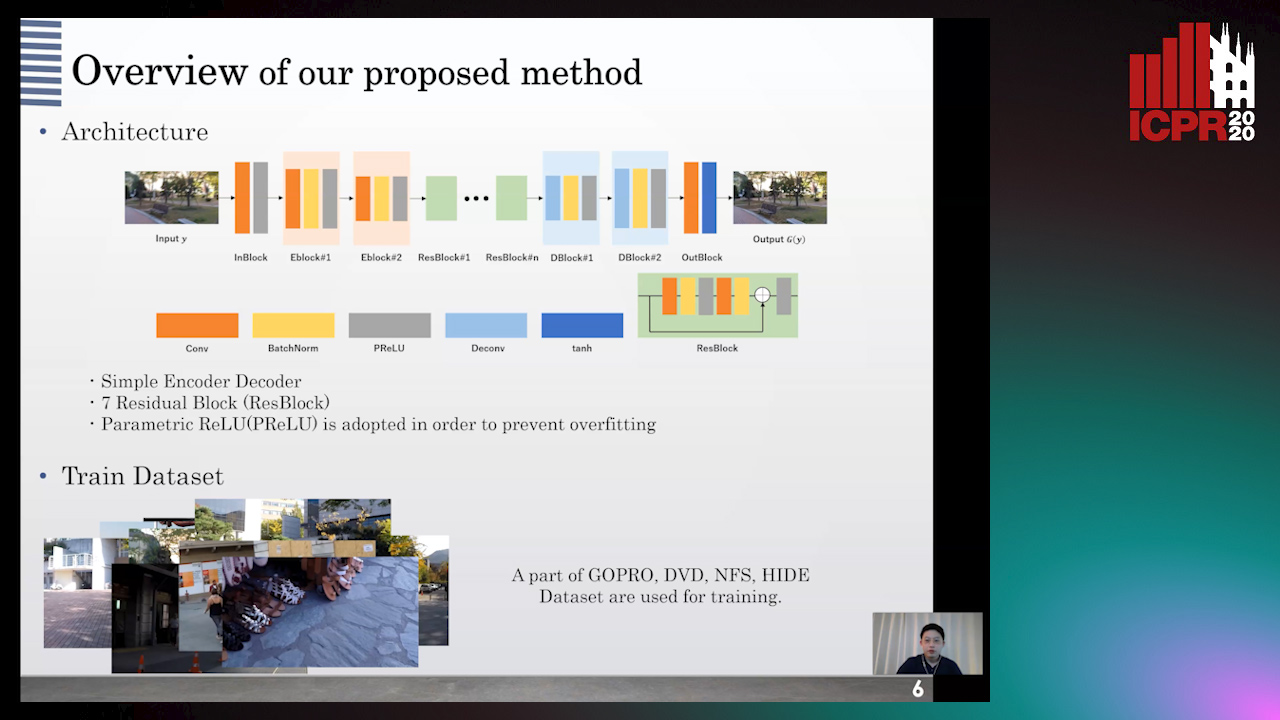
Auto-TLDR; DeblurDCTGAN: A Discrete Cosine Transform for Image Deblurring
Abstract Slides Poster Similar
Novel View Synthesis from a 6-DoF Pose by Two-Stage Networks
Xiang Guo, Bo Li, Yuchao Dai, Tongxin Zhang, Hui Deng

Auto-TLDR; Novel View Synthesis from a 6-DoF Pose Using Generative Adversarial Network
Abstract Slides Poster Similar
Local Facial Attribute Transfer through Inpainting
Ricard Durall, Franz-Josef Pfreundt, Janis Keuper

Auto-TLDR; Attribute Transfer Inpainting Generative Adversarial Network
Abstract Slides Poster Similar
Camera Calibration Using Parallel Line Segments

Auto-TLDR; Closed-Form Calibration of Surveillance Cameras using Parallel 3D Line Segment Projections
Abstract Slides Poster Similar
Pose Variation Adaptation for Person Re-Identification
Lei Zhang, Na Jiang, Qishuai Diao, Yue Xu, Zhong Zhou, Wei Wu

Auto-TLDR; Pose Transfer Generative Adversarial Network for Person Re-identification
Abstract Slides Poster Similar
Removing Raindrops from a Single Image Using Synthetic Data
Yoshihito Kokubo, Shusaku Asada, Hirotaka Maruyama, Masaru Koide, Kohei Yamamoto, Yoshihisa Suetsugu

Auto-TLDR; Raindrop Removal Using Synthetic Raindrop Data
Abstract Slides Poster Similar
Detail Fusion GAN: High-Quality Translation for Unpaired Images with GAN-Based Data Augmentation
Ling Li, Yaochen Li, Chuan Wu, Hang Dong, Peilin Jiang, Fei Wang

Auto-TLDR; Data Augmentation with GAN-based Generative Adversarial Network
Abstract Slides Poster Similar
Sample-Aware Data Augmentor for Scene Text Recognition
Guanghao Meng, Tao Dai, Shudeng Wu, Bin Chen, Jian Lu, Yong Jiang, Shutao Xia

Auto-TLDR; Sample-Aware Data Augmentation for Scene Text Recognition
Abstract Slides Poster Similar
Adaptive Image Compression Using GAN Based Semantic-Perceptual Residual Compensation
Ruojing Wang, Zitang Sun, Sei-Ichiro Kamata, Weili Chen

Auto-TLDR; Adaptive Image Compression using GAN based Semantic-Perceptual Residual Compensation
Abstract Slides Poster Similar
Extending Single Beam Lidar to Full Resolution by Fusing with Single Image Depth Estimation
Yawen Lu, Yuxing Wang, Devarth Parikh, Guoyu Lu

Auto-TLDR; Self-supervised LIDAR for Low-Cost Depth Estimation
2D License Plate Recognition based on Automatic Perspective Rectification
Hui Xu, Zhao-Hong Guo, Da-Han Wang, Xiang-Dong Zhou, Yu Shi

Auto-TLDR; Perspective Rectification Network for License Plate Recognition
Abstract Slides Poster Similar
Explorable Tone Mapping Operators
Su Chien-Chuan, Yu-Lun Liu, Hung Jin Lin, Ren Wang, Chia-Ping Chen, Yu-Lin Chang, Soo-Chang Pei

Auto-TLDR; Learning-based multimodal tone-mapping from HDR images
Abstract Slides Poster Similar
Single Image Deblurring Using Bi-Attention Network

Auto-TLDR; Bi-Attention Neural Network for Single Image Deblurring
Local-Global Interactive Network for Face Age Transformation
Jie Song, Ping Wei, Huan Li, Yongchi Zhang, Nanning Zheng

Auto-TLDR; A Novel Local-Global Interaction Framework for Long-span Face Age Transformation
Abstract Slides Poster Similar
Super-Resolution Guided Pore Detection for Fingerprint Recognition
Syeda Nyma Ferdous, Ali Dabouei, Jeremy Dawson, Nasser M. Nasarabadi

Auto-TLDR; Super-Resolution Generative Adversarial Network for Fingerprint Recognition Using Pore Features
Abstract Slides Poster Similar
MTGAN: Mask and Texture-Driven Generative Adversarial Network for Lung Nodule Segmentation
Wei Chen, Qiuli Wang, Kun Wang, Dan Yang, Xiaohong Zhang, Chen Liu, Yucong Li

Auto-TLDR; Mask and Texture-driven Generative Adversarial Network for Lung Nodule Segmentation
Abstract Slides Poster Similar
Adaptive Feature Fusion Network for Gaze Tracking in Mobile Tablets
Yiwei Bao, Yihua Cheng, Yunfei Liu, Feng Lu

Auto-TLDR; Adaptive Feature Fusion Network for Multi-stream Gaze Estimation in Mobile Tablets
Abstract Slides Poster Similar
An Unsupervised Approach towards Varying Human Skin Tone Using Generative Adversarial Networks
Debapriya Roy, Diganta Mukherjee, Bhabatosh Chanda

Auto-TLDR; Unsupervised Skin Tone Change Using Augmented Reality Based Models
Abstract Slides Poster Similar
JUMPS: Joints Upsampling Method for Pose Sequences
Lucas Mourot, Francois Le Clerc, Cédric Thébault, Pierre Hellier

Auto-TLDR; JUMPS: Increasing the Number of Joints in 2D Pose Estimation and Recovering Occluded or Missing Joints
Abstract Slides Poster Similar
Thermal Image Enhancement Using Generative Adversarial Network for Pedestrian Detection
Mohamed Amine Marnissi, Hajer Fradi, Anis Sahbani, Najoua Essoukri Ben Amara

Auto-TLDR; Improving Visual Quality of Infrared Images for Pedestrian Detection Using Generative Adversarial Network
Abstract Slides Poster Similar
Detail-Revealing Deep Low-Dose CT Reconstruction
Xinchen Ye, Yuyao Xu, Rui Xu, Shoji Kido, Noriyuki Tomiyama

Auto-TLDR; A Dual-branch Aggregation Network for Low-Dose CT Reconstruction
Abstract Slides Poster Similar
Better Prior Knowledge Improves Human-Pose-Based Extrinsic Camera Calibration
Olivier Moliner, Sangxia Huang, Kalle Åström

Auto-TLDR; Improving Human-pose-based Extrinsic Calibration for Multi-Camera Systems
Abstract Slides Poster Similar
The Role of Cycle Consistency for Generating Better Human Action Videos from a Single Frame

Auto-TLDR; Generating Videos with Human Action Semantics using Cycle Constraints
Abstract Slides Poster Similar
Free-Form Image Inpainting Via Contrastive Attention Network
Xin Ma, Xiaoqiang Zhou, Huaibo Huang, Zhenhua Chai, Xiaolin Wei, Ran He

Auto-TLDR; Self-supervised Siamese inference for image inpainting
DeepBEV: A Conditional Adversarial Network for Bird’s Eye View Generation

Auto-TLDR; A Generative Adversarial Network for Semantic Object Representation in Autonomous Vehicles
Abstract Slides Poster Similar
Identity-Preserved Face Beauty Transformation with Conditional Generative Adversarial Networks

Auto-TLDR; Identity-preserved face beauty transformation using conditional GANs
Abstract Slides Poster Similar
Transitional Asymmetric Non-Local Neural Networks for Real-World Dirt Road Segmentation

Auto-TLDR; Transitional Asymmetric Non-Local Neural Networks for Semantic Segmentation on Dirt Roads
Abstract Slides Poster Similar
Semi-Supervised Generative Adversarial Networks with a Pair of Complementary Generators for Retinopathy Screening
Yingpeng Xie, Qiwei Wan, Hai Xie, En-Leng Tan, Yanwu Xu, Baiying Lei

Auto-TLDR; Generative Adversarial Networks for Retinopathy Diagnosis via Fundus Images
Abstract Slides Poster Similar
IBN-STR: A Robust Text Recognizer for Irregular Text in Natural Scenes
Xiaoqian Li, Jie Liu, Shuwu Zhang

Auto-TLDR; IBN-STR: A Robust Text Recognition System Based on Data and Feature Representation
Multi-Scale Residual Pyramid Attention Network for Monocular Depth Estimation
Jing Liu, Xiaona Zhang, Zhaoxin Li, Tianlu Mao

Auto-TLDR; Multi-scale Residual Pyramid Attention Network for Monocular Depth Estimation
Abstract Slides Poster Similar
Encoder-Decoder Based Convolutional Neural Networks with Multi-Scale-Aware Modules for Crowd Counting
Pongpisit Thanasutives, Ken-Ichi Fukui, Masayuki Numao, Boonserm Kijsirikul

Auto-TLDR; M-SFANet and M-SegNet for Crowd Counting Using Multi-Scale Fusion Networks
Abstract Slides Poster Similar
Leveraging a Weakly Adversarial Paradigm for Joint Learning of Disparity and Confidence Estimation
Matteo Poggi, Fabio Tosi, Filippo Aleotti, Stefano Mattoccia

Auto-TLDR; Joint Training of Deep-Networks for Outlier Detection from Stereo Images
Abstract Slides Poster Similar
Machine-Learned Regularization and Polygonization of Building Segmentation Masks
Stefano Zorzi, Ksenia Bittner, Friedrich Fraundorfer

Auto-TLDR; Automatic Regularization and Polygonization of Building Segmentation masks using Generative Adversarial Network
Abstract Slides Poster Similar
LFIEM: Lightweight Filter-Based Image Enhancement Model
Oktai Tatanov, Aleksei Samarin

Auto-TLDR; Image Retouching Using Semi-supervised Learning for Mobile Devices
Abstract Slides Poster Similar
PSDNet: A Balanced Architecture of Accuracy and Parameters for Semantic Segmentation

Auto-TLDR; Pyramid Pooling Module with SE1Cblock and D2SUpsample Network (PSDNet)
Abstract Slides Poster Similar
Multi-Laplacian GAN with Edge Enhancement for Face Super Resolution

Auto-TLDR; Face Image Super-Resolution with Enhanced Edge Information
Abstract Slides Poster Similar
Calibration and Absolute Pose Estimation of Trinocular Linear Camera Array for Smart City Applications
Martin Ahrnbom, Mikael Nilsson, Håkan Ardö, Kalle Åström, Oksana Yastremska-Kravchenko, Aliaksei Laureshyn

Auto-TLDR; Trinocular Linear Camera Array Calibration for Traffic Surveillance Applications
Abstract Slides Poster Similar
Delivering Meaningful Representation for Monocular Depth Estimation
Doyeon Kim, Donggyu Joo, Junmo Kim

Auto-TLDR; Monocular Depth Estimation by Bridging the Context between Encoding and Decoding
Abstract Slides Poster Similar
SATGAN: Augmenting Age Biased Dataset for Cross-Age Face Recognition
Wenshuang Liu, Wenting Chen, Yuanlue Zhu, Linlin Shen

Auto-TLDR; SATGAN: Stable Age Translation GAN for Cross-Age Face Recognition
Abstract Slides Poster Similar
Let's Play Music: Audio-Driven Performance Video Generation
Hao Zhu, Yi Li, Feixia Zhu, Aihua Zheng, Ran He

Auto-TLDR; APVG: Audio-driven Performance Video Generation Using Structured Temporal UNet
Abstract Slides Poster Similar
UDBNET: Unsupervised Document Binarization Network Via Adversarial Game
Amandeep Kumar, Shuvozit Ghose, Pinaki Nath Chowdhury, Partha Pratim Roy, Umapada Pal

Auto-TLDR; Three-player Min-max Adversarial Game for Unsupervised Document Binarization
Abstract Slides Poster Similar
Hierarchically Aggregated Residual Transformation for Single Image Super Resolution

Auto-TLDR; HARTnet: Hierarchically Aggregated Residual Transformation for Multi-Scale Super-resolution
Abstract Slides Poster Similar
Learning Non-Rigid Surface Reconstruction from Spatio-Temporal Image Patches
Matteo Pedone, Abdelrahman Mostafa, Janne Heikkilä

Auto-TLDR; Dense Spatio-Temporal Depth Maps of Deformable Objects from Video Sequences
Abstract Slides Poster Similar
Dynamic Guided Network for Monocular Depth Estimation
Xiaoxia Xing, Yinghao Cai, Yiping Yang, Dayong Wen

Auto-TLDR; DGNet: Dynamic Guidance Upsampling for Self-attention-Decoding for Monocular Depth Estimation
Abstract Slides Poster Similar