Single Image Deblurring Using Bi-Attention Network

Auto-TLDR; Bi-Attention Neural Network for Single Image Deblurring
Similar papers
GAN-Based Image Deblurring Using DCT Discriminator
Hiroki Tomosada, Takahiro Kudo, Takanori Fujisawa, Masaaki Ikehara
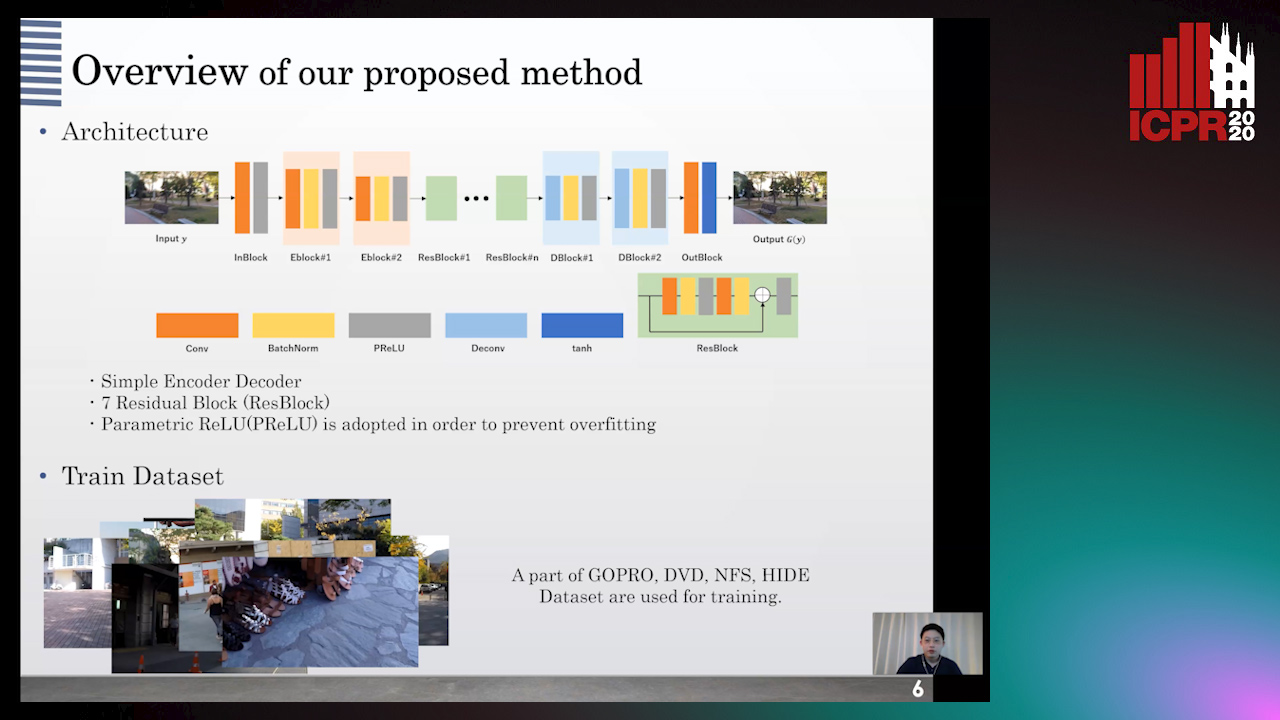
Auto-TLDR; DeblurDCTGAN: A Discrete Cosine Transform for Image Deblurring
Abstract Slides Poster Similar
Cross-Layer Information Refining Network for Single Image Super-Resolution
Hongyi Zhang, Wen Lu, Xiaopeng Sun

Auto-TLDR; Interlaced Spatial Attention Block for Single Image Super-Resolution
Abstract Slides Poster Similar
RSAN: Residual Subtraction and Attention Network for Single Image Super-Resolution
Shuo Wei, Xin Sun, Haoran Zhao, Junyu Dong

Auto-TLDR; RSAN: Residual subtraction and attention network for super-resolution
Hierarchically Aggregated Residual Transformation for Single Image Super Resolution

Auto-TLDR; HARTnet: Hierarchically Aggregated Residual Transformation for Multi-Scale Super-resolution
Abstract Slides Poster Similar
Residual Fractal Network for Single Image Super Resolution by Widening and Deepening
Jiahang Gu, Zhaowei Qu, Xiaoru Wang, Jiawang Dan, Junwei Sun

Auto-TLDR; Residual fractal convolutional network for single image super-resolution
Abstract Slides Poster Similar
Global-Local Attention Network for Semantic Segmentation in Aerial Images
Minglong Li, Lianlei Shan, Weiqiang Wang

Auto-TLDR; GLANet: Global-Local Attention Network for Semantic Segmentation
Abstract Slides Poster Similar
Free-Form Image Inpainting Via Contrastive Attention Network
Xin Ma, Xiaoqiang Zhou, Huaibo Huang, Zhenhua Chai, Xiaolin Wei, Ran He

Auto-TLDR; Self-supervised Siamese inference for image inpainting
Dynamic Guided Network for Monocular Depth Estimation
Xiaoxia Xing, Yinghao Cai, Yiping Yang, Dayong Wen

Auto-TLDR; DGNet: Dynamic Guidance Upsampling for Self-attention-Decoding for Monocular Depth Estimation
Abstract Slides Poster Similar
Progressive Scene Segmentation Based on Self-Attention Mechanism
Yunyi Pan, Yuan Gan, Kun Liu, Yan Zhang

Auto-TLDR; Two-Stage Semantic Scene Segmentation with Self-Attention
Abstract Slides Poster Similar
Multi-Scale Residual Pyramid Attention Network for Monocular Depth Estimation
Jing Liu, Xiaona Zhang, Zhaoxin Li, Tianlu Mao

Auto-TLDR; Multi-scale Residual Pyramid Attention Network for Monocular Depth Estimation
Abstract Slides Poster Similar
Enhanced Feature Pyramid Network for Semantic Segmentation
Mucong Ye, Ouyang Jinpeng, Ge Chen, Jing Zhang, Xiaogang Yu

Auto-TLDR; EFPN: Enhanced Feature Pyramid Network for Semantic Segmentation
Abstract Slides Poster Similar
GSTO: Gated Scale-Transfer Operation for Multi-Scale Feature Learning in Semantic Segmentation
Zhuoying Wang, Yongtao Wang, Zhi Tang, Yangyan Li, Ying Chen, Haibin Ling, Weisi Lin

Auto-TLDR; Gated Scale-Transfer Operation for Semantic Segmentation
Abstract Slides Poster Similar
MBD-GAN: Model-Based Image Deblurring with a Generative Adversarial Network

Auto-TLDR; Model-Based Deblurring GAN for Inverse Imaging
Abstract Slides Poster Similar
Boosting High-Level Vision with Joint Compression Artifacts Reduction and Super-Resolution
Xiaoyu Xiang, Qian Lin, Jan Allebach

Auto-TLDR; A Context-Aware Joint CAR and SR Neural Network for High-Resolution Text Recognition and Face Detection
Abstract Slides Poster Similar
Deep Residual Attention Network for Hyperspectral Image Reconstruction

Auto-TLDR; Deep Convolutional Neural Network for Hyperspectral Image Reconstruction from a Snapshot
Abstract Slides Poster Similar
Transitional Asymmetric Non-Local Neural Networks for Real-World Dirt Road Segmentation

Auto-TLDR; Transitional Asymmetric Non-Local Neural Networks for Semantic Segmentation on Dirt Roads
Abstract Slides Poster Similar
Selective Kernel and Motion-Emphasized Loss Based Attention-Guided Network for HDR Imaging of Dynamic Scenes
Yipeng Deng, Qin Liu, Takeshi Ikenaga

Auto-TLDR; SK-AHDRNet: A Deep Network with attention module and motion-emphasized loss function to produce ghost-free HDR images
Abstract Slides Poster Similar
Progressive Splitting and Upscaling Structure for Super-Resolution

Auto-TLDR; PSUS: Progressive and Upscaling Layer for Single Image Super-Resolution
Abstract Slides Poster Similar
Single Image Super-Resolution with Dynamic Residual Connection
Karam Park, Jae Woong Soh, Nam Ik Cho

Auto-TLDR; Dynamic Residual Attention Network for Lightweight Single Image Super-Residual Networks
Abstract Slides Poster Similar
DID: A Nested Dense in Dense Structure with Variable Local Dense Blocks for Super-Resolution Image Reconstruction
Longxi Li, Hesen Feng, Bing Zheng, Lihong Ma, Jing Tian

Auto-TLDR; DID: Deep Super-Residual Dense Network for Image Super-resolution Reconstruction
Abstract Slides Poster Similar
Wavelet Attention Embedding Networks for Video Super-Resolution
Young-Ju Choi, Young-Woon Lee, Byung-Gyu Kim

Auto-TLDR; Wavelet Attention Embedding Network for Video Super-Resolution
Abstract Slides Poster Similar
Arbitrary Style Transfer with Parallel Self-Attention
Tiange Zhang, Ying Gao, Feng Gao, Lin Qi, Junyu Dong

Auto-TLDR; Self-Attention-Based Arbitrary Style Transfer Using Adaptive Instance Normalization
Abstract Slides Poster Similar
Video Reconstruction by Spatio-Temporal Fusion of Blurred-Coded Image Pair
Anupama S, Prasan Shedligeri, Abhishek Pal, Kaushik Mitr

Auto-TLDR; Recovering Video from Motion-Blurred and Coded Exposure Images Using Deep Learning
Abstract Slides Poster Similar
Real-Time Semantic Segmentation Via Region and Pixel Context Network
Yajun Li, Yazhou Liu, Quansen Sun

Auto-TLDR; A Dual Context Network for Real-Time Semantic Segmentation
Abstract Slides Poster Similar
Attention Stereo Matching Network
Doudou Zhang, Jing Cai, Yanbing Xue, Zan Gao, Hua Zhang

Auto-TLDR; ASM-Net: Attention Stereo Matching with Disparity Refinement
Abstract Slides Poster Similar
Context-Aware Residual Module for Image Classification

Auto-TLDR; Context-Aware Residual Module for Image Classification
Abstract Slides Poster Similar
Multi-Laplacian GAN with Edge Enhancement for Face Super Resolution

Auto-TLDR; Face Image Super-Resolution with Enhanced Edge Information
Abstract Slides Poster Similar
Attention Pyramid Module for Scene Recognition
Zhinan Qiao, Xiaohui Yuan, Chengyuan Zhuang, Abolfazl Meyarian

Auto-TLDR; Attention Pyramid Module for Multi-Scale Scene Recognition
Abstract Slides Poster Similar
Adaptive Image Compression Using GAN Based Semantic-Perceptual Residual Compensation
Ruojing Wang, Zitang Sun, Sei-Ichiro Kamata, Weili Chen

Auto-TLDR; Adaptive Image Compression using GAN based Semantic-Perceptual Residual Compensation
Abstract Slides Poster Similar
Do Not Treat Boundaries and Regions Differently: An Example on Heart Left Atrial Segmentation
Zhou Zhao, Elodie Puybareau, Nicolas Boutry, Thierry Geraud

Auto-TLDR; Attention Full Convolutional Network for Atrial Segmentation using ResNet-101 Architecture
PSDNet: A Balanced Architecture of Accuracy and Parameters for Semantic Segmentation

Auto-TLDR; Pyramid Pooling Module with SE1Cblock and D2SUpsample Network (PSDNet)
Abstract Slides Poster Similar
LiNet: A Lightweight Network for Image Super Resolution
Armin Mehri, Parichehr Behjati Ardakani, Angel D. Sappa

Auto-TLDR; LiNet: A Compact Dense Network for Lightweight Super Resolution
Abstract Slides Poster Similar
Deep Iterative Residual Convolutional Network for Single Image Super-Resolution
Rao Muhammad Umer, Gian Luca Foresti, Christian Micheloni

Auto-TLDR; ISRResCNet: Deep Iterative Super-Resolution Residual Convolutional Network for Single Image Super-resolution
Deeply-Fused Attentive Network for Stereo Matching
Zuliu Yang, Xindong Ai, Weida Yang, Yong Zhao, Qifei Dai, Fuchi Li

Auto-TLDR; DF-Net: Deep Learning-based Network for Stereo Matching
Abstract Slides Poster Similar
SIDGAN: Single Image Dehazing without Paired Supervision
Pan Wei, Xin Wang, Lei Wang, Ji Xiang, Zihan Wang

Auto-TLDR; DehazeGAN: An End-to-End Generative Adversarial Network for Image Dehazing
Abstract Slides Poster Similar
Efficient-Receptive Field Block with Group Spatial Attention Mechanism for Object Detection
Jiacheng Zhang, Zhicheng Zhao, Fei Su

Auto-TLDR; E-RFB: Efficient-Receptive Field Block for Deep Neural Network for Object Detection
Abstract Slides Poster Similar
Ordinal Depth Classification Using Region-Based Self-Attention
Minh Hieu Phan, Son Lam Phung, Abdesselam Bouzerdoum

Auto-TLDR; Region-based Self-Attention for Multi-scale Depth Estimation from a Single 2D Image
Abstract Slides Poster Similar
Face Super-Resolution Network with Incremental Enhancement of Facial Parsing Information
Shuang Liu, Chengyi Xiong, Zhirong Gao

Auto-TLDR; Learning-based Face Super-Resolution with Incremental Boosting Facial Parsing Information
Abstract Slides Poster Similar
Encoder-Decoder Based Convolutional Neural Networks with Multi-Scale-Aware Modules for Crowd Counting
Pongpisit Thanasutives, Ken-Ichi Fukui, Masayuki Numao, Boonserm Kijsirikul

Auto-TLDR; M-SFANet and M-SegNet for Crowd Counting Using Multi-Scale Fusion Networks
Abstract Slides Poster Similar
Automatical Enhancement and Denoising of Extremely Low-Light Images
Yuda Song, Yunfang Zhu, Xin Du

Auto-TLDR; INSNet: Illumination and Noise Separation Network for Low-Light Image Restoring
Abstract Slides Poster Similar
Accurate Cell Segmentation in Digital Pathology Images Via Attention Enforced Networks
Zeyi Yao, Kaiqi Li, Guanhong Zhang, Yiwen Luo, Xiaoguang Zhou, Muyi Sun

Auto-TLDR; AENet: Attention Enforced Network for Automatic Cell Segmentation
Abstract Slides Poster Similar
Boundary-Aware Graph Convolution for Semantic Segmentation
Hanzhe Hu, Jinshi Cui, Jinshi Hongbin Zha

Auto-TLDR; Boundary-Aware Graph Convolution for Semantic Segmentation
Abstract Slides Poster Similar
Self and Channel Attention Network for Person Re-Identification
Asad Munir, Niki Martinel, Christian Micheloni

Auto-TLDR; SCAN: Self and Channel Attention Network for Person Re-identification
Abstract Slides Poster Similar
Efficient Super Resolution by Recursive Aggregation
Zhengxiong Luo Zhengxiong Luo, Yan Huang, Shang Li, Liang Wang, Tieniu Tan

Auto-TLDR; Recursive Aggregation Network for Efficient Deep Super Resolution
Abstract Slides Poster Similar
CSpA-DN: Channel and Spatial Attention Dense Network for Fusing PET and MRI Images
Bicao Li, Zhoufeng Liu, Shan Gao, Jenq-Neng Hwang, Jun Sun, Zongmin Wang

Auto-TLDR; CSpA-DN: Unsupervised Fusion of PET and MR Images with Channel and Spatial Attention
Abstract Slides Poster Similar
Delivering Meaningful Representation for Monocular Depth Estimation
Doyeon Kim, Donggyu Joo, Junmo Kim

Auto-TLDR; Monocular Depth Estimation by Bridging the Context between Encoding and Decoding
Abstract Slides Poster Similar
Multi-Direction Convolution for Semantic Segmentation
Dehui Li, Zhiguo Cao, Ke Xian, Xinyuan Qi, Chao Zhang, Hao Lu

Auto-TLDR; Multi-Direction Convolution for Contextual Segmentation
Thermal Image Enhancement Using Generative Adversarial Network for Pedestrian Detection
Mohamed Amine Marnissi, Hajer Fradi, Anis Sahbani, Najoua Essoukri Ben Amara

Auto-TLDR; Improving Visual Quality of Infrared Images for Pedestrian Detection Using Generative Adversarial Network
Abstract Slides Poster Similar