Video Reconstruction by Spatio-Temporal Fusion of Blurred-Coded Image Pair
Anupama S,
Prasan Shedligeri,
Abhishek Pal,
Kaushik Mitr

Auto-TLDR; Recovering Video from Motion-Blurred and Coded Exposure Images Using Deep Learning
Similar papers
Deep Residual Attention Network for Hyperspectral Image Reconstruction

Auto-TLDR; Deep Convolutional Neural Network for Hyperspectral Image Reconstruction from a Snapshot
Abstract Slides Poster Similar
Wavelet Attention Embedding Networks for Video Super-Resolution
Young-Ju Choi, Young-Woon Lee, Byung-Gyu Kim

Auto-TLDR; Wavelet Attention Embedding Network for Video Super-Resolution
Abstract Slides Poster Similar
Residual Learning of Video Frame Interpolation Using Convolutional LSTM

Auto-TLDR; Video Frame Interpolation Using Residual Learning and Convolutional LSTMs
Abstract Slides Poster Similar
Video Lightening with Dedicated CNN Architecture
Li-Wen Wang, Wan-Chi Siu, Zhi-Song Liu, Chu-Tak Li, P. K. Daniel Lun

Auto-TLDR; VLN: Video Lightening Network for Driving Assistant Systems in Dark Environment
Abstract Slides Poster Similar
D3Net: Joint Demosaicking, Deblurring and Deringing
Tomas Kerepecky, Filip Sroubek

Auto-TLDR; Joint demosaicking deblurring and deringing network with light-weight architecture inspired by the alternating direction method of multipliers
MBD-GAN: Model-Based Image Deblurring with a Generative Adversarial Network

Auto-TLDR; Model-Based Deblurring GAN for Inverse Imaging
Abstract Slides Poster Similar
Selective Kernel and Motion-Emphasized Loss Based Attention-Guided Network for HDR Imaging of Dynamic Scenes
Yipeng Deng, Qin Liu, Takeshi Ikenaga

Auto-TLDR; SK-AHDRNet: A Deep Network with attention module and motion-emphasized loss function to produce ghost-free HDR images
Abstract Slides Poster Similar
5D Light Field Synthesis from a Monocular Video
Kyuho Bae, Andre Ivan, Hajime Nagahara, In Kyu Park

Auto-TLDR; Synthesis of Light Field Video from Monocular Video using Deep Learning
Single Image Deblurring Using Bi-Attention Network

Auto-TLDR; Bi-Attention Neural Network for Single Image Deblurring
TinyVIRAT: Low-Resolution Video Action Recognition
Ugur Demir, Yogesh Rawat, Mubarak Shah

Auto-TLDR; TinyVIRAT: A Progressive Generative Approach for Action Recognition in Videos
Abstract Slides Poster Similar
Video Semantic Segmentation Using Deep Multi-View Representation Learning
Akrem Sellami, Salvatore Tabbone

Auto-TLDR; Deep Multi-view Representation Learning for Video Object Segmentation
Abstract Slides Poster Similar
Boosting High-Level Vision with Joint Compression Artifacts Reduction and Super-Resolution
Xiaoyu Xiang, Qian Lin, Jan Allebach

Auto-TLDR; A Context-Aware Joint CAR and SR Neural Network for High-Resolution Text Recognition and Face Detection
Abstract Slides Poster Similar
A Lightweight Network to Learn Optical Flow from Event Data

Auto-TLDR; A lightweight pyramid network with attention mechanism to learn optical flow from events data
Learning Non-Rigid Surface Reconstruction from Spatio-Temporal Image Patches
Matteo Pedone, Abdelrahman Mostafa, Janne Heikkilä

Auto-TLDR; Dense Spatio-Temporal Depth Maps of Deformable Objects from Video Sequences
Abstract Slides Poster Similar
Motion U-Net: Multi-Cue Encoder-Decoder Network for Motion Segmentation
Gani Rahmon, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; Motion U-Net: A Deep Learning Framework for Robust Moving Object Detection under Challenging Conditions
Abstract Slides Poster Similar
Deep Iterative Residual Convolutional Network for Single Image Super-Resolution
Rao Muhammad Umer, Gian Luca Foresti, Christian Micheloni

Auto-TLDR; ISRResCNet: Deep Iterative Super-Resolution Residual Convolutional Network for Single Image Super-resolution
Mutual Information Based Method for Unsupervised Disentanglement of Video Representation
Aditya Sreekar P, Ujjwal Tiwari, Anoop Namboodiri

Auto-TLDR; MIPAE: Mutual Information Predictive Auto-Encoder for Video Prediction
Abstract Slides Poster Similar
Reducing the Variance of Variational Estimates of Mutual Information by Limiting the Critic's Hypothesis Space to RKHS
Aditya Sreekar P, Ujjwal Tiwari, Anoop Namboodiri

Auto-TLDR; Mutual Information Estimation from Variational Lower Bounds Using a Critic's Hypothesis Space
Learning to Take Directions One Step at a Time
Qiyang Hu, Adrian Wälchli, Tiziano Portenier, Matthias Zwicker, Paolo Favaro

Auto-TLDR; Generating a Sequence of Motion Strokes from a Single Image
Abstract Slides Poster Similar
SAT-Net: Self-Attention and Temporal Fusion for Facial Action Unit Detection
Zhihua Li, Zheng Zhang, Lijun Yin

Auto-TLDR; Temporal Fusion and Self-Attention Network for Facial Action Unit Detection
Abstract Slides Poster Similar
Dual-MTGAN: Stochastic and Deterministic Motion Transfer for Image-To-Video Synthesis
Fu-En Yang, Jing-Cheng Chang, Yuan-Hao Lee, Yu-Chiang Frank Wang

Auto-TLDR; Dual Motion Transfer GAN for Convolutional Neural Networks
Abstract Slides Poster Similar
Deep Universal Blind Image Denoising

Auto-TLDR; Image Denoising with Deep Convolutional Neural Networks
Detail-Revealing Deep Low-Dose CT Reconstruction
Xinchen Ye, Yuyao Xu, Rui Xu, Shoji Kido, Noriyuki Tomiyama

Auto-TLDR; A Dual-branch Aggregation Network for Low-Dose CT Reconstruction
Abstract Slides Poster Similar
Automatical Enhancement and Denoising of Extremely Low-Light Images
Yuda Song, Yunfang Zhu, Xin Du

Auto-TLDR; INSNet: Illumination and Noise Separation Network for Low-Light Image Restoring
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
TSMSAN: A Three-Stream Multi-Scale Attentive Network for Video Saliency Detection
Jingwen Yang, Guanwen Zhang, Wei Zhou

Auto-TLDR; Three-stream Multi-scale attentive network for video saliency detection in dynamic scenes
Abstract Slides Poster Similar
Extending Single Beam Lidar to Full Resolution by Fusing with Single Image Depth Estimation
Yawen Lu, Yuxing Wang, Devarth Parikh, Guoyu Lu

Auto-TLDR; Self-supervised LIDAR for Low-Cost Depth Estimation
Learning Knowledge-Rich Sequential Model for Planar Homography Estimation in Aerial Video

Auto-TLDR; Sequential Estimation of Planar Homographic Transformations over Aerial Videos
Abstract Slides Poster Similar
On-Device Text Image Super Resolution
Dhruval Jain, Arun Prabhu, Gopi Ramena, Manoj Goyal, Debi Mohanty, Naresh Purre, Sukumar Moharana

Auto-TLDR; A Novel Deep Neural Network for Super-Resolution on Low Resolution Text Images
Abstract Slides Poster Similar
Hierarchically Aggregated Residual Transformation for Single Image Super Resolution

Auto-TLDR; HARTnet: Hierarchically Aggregated Residual Transformation for Multi-Scale Super-resolution
Abstract Slides Poster Similar
Snapshot Hyperspectral Imaging Based on Weighted High-Order Singular Value Regularization
Hua Huang, Cheng Niankai, Lizhi Wang

Auto-TLDR; High-Order Tensor Optimization for Hyperspectral Imaging
Abstract Slides Poster Similar
Progressive Splitting and Upscaling Structure for Super-Resolution

Auto-TLDR; PSUS: Progressive and Upscaling Layer for Single Image Super-Resolution
Abstract Slides Poster Similar
Flow-Guided Spatial Attention Tracking for Egocentric Activity Recognition

Auto-TLDR; flow-guided spatial attention tracking for egocentric activity recognition
Abstract Slides Poster Similar
Movement-Induced Priors for Deep Stereo
Yuxin Hou, Muhammad Kamran Janjua, Juho Kannala, Arno Solin

Auto-TLDR; Fusing Stereo Disparity Estimation with Movement-induced Prior Information
Abstract Slides Poster Similar
RSAN: Residual Subtraction and Attention Network for Single Image Super-Resolution
Shuo Wei, Xin Sun, Haoran Zhao, Junyu Dong

Auto-TLDR; RSAN: Residual subtraction and attention network for super-resolution
Human Segmentation with Dynamic LiDAR Data
Tao Zhong, Wonjik Kim, Masayuki Tanaka, Masatoshi Okutomi

Auto-TLDR; Spatiotemporal Neural Network for Human Segmentation with Dynamic Point Clouds
Face Super-Resolution Network with Incremental Enhancement of Facial Parsing Information
Shuang Liu, Chengyi Xiong, Zhirong Gao

Auto-TLDR; Learning-based Face Super-Resolution with Incremental Boosting Facial Parsing Information
Abstract Slides Poster Similar
LiNet: A Lightweight Network for Image Super Resolution
Armin Mehri, Parichehr Behjati Ardakani, Angel D. Sappa

Auto-TLDR; LiNet: A Compact Dense Network for Lightweight Super Resolution
Abstract Slides Poster Similar
Deep Realistic Novel View Generation for City-Scale Aerial Images
Koundinya Nouduri, Ke Gao, Joshua Fraser, Shizeng Yao, Hadi Aliakbarpour, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; End-to-End 3D Voxel Renderer for Multi-View Stereo Data Generation and Evaluation
Abstract Slides Poster Similar
Future Urban Scenes Generation through Vehicles Synthesis
Alessandro Simoni, Luca Bergamini, Andrea Palazzi, Simone Calderara, Rita Cucchiara

Auto-TLDR; Predicting the Future of an Urban Scene with a Novel View Synthesis Paradigm
Abstract Slides Poster Similar
GAN-Based Image Deblurring Using DCT Discriminator
Hiroki Tomosada, Takahiro Kudo, Takanori Fujisawa, Masaaki Ikehara
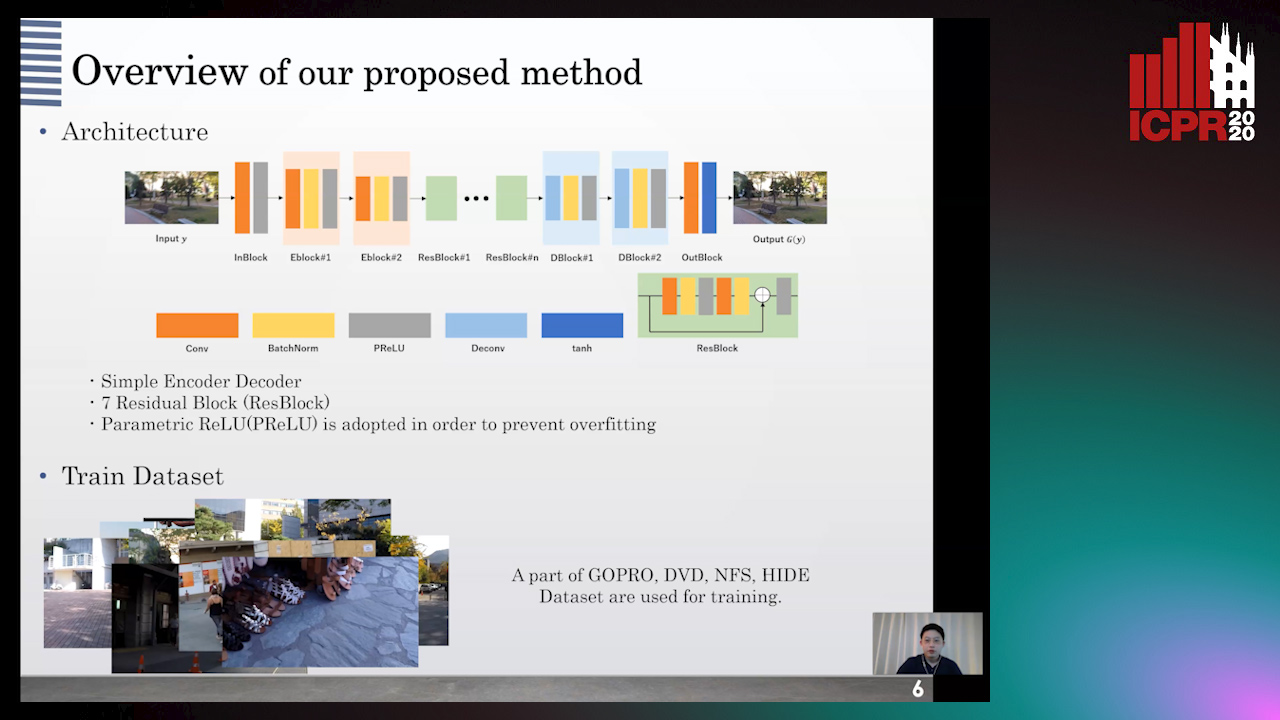
Auto-TLDR; DeblurDCTGAN: A Discrete Cosine Transform for Image Deblurring
Abstract Slides Poster Similar
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
Dynamic Guided Network for Monocular Depth Estimation
Xiaoxia Xing, Yinghao Cai, Yiping Yang, Dayong Wen

Auto-TLDR; DGNet: Dynamic Guidance Upsampling for Self-attention-Decoding for Monocular Depth Estimation
Abstract Slides Poster Similar
Self-Supervised Learning of Dynamic Representations for Static Images
Siyang Song, Enrique Sanchez, Linlin Shen, Michel Valstar

Auto-TLDR; Facial Action Unit Intensity Estimation and Affect Estimation from Still Images with Multiple Temporal Scale
Abstract Slides Poster Similar
A Dual-Branch Network for Infrared and Visible Image Fusion

Auto-TLDR; Image Fusion Using Autoencoder for Deep Learning
Abstract Slides Poster Similar
Adaptive Image Compression Using GAN Based Semantic-Perceptual Residual Compensation
Ruojing Wang, Zitang Sun, Sei-Ichiro Kamata, Weili Chen

Auto-TLDR; Adaptive Image Compression using GAN based Semantic-Perceptual Residual Compensation
Abstract Slides Poster Similar
Residual Fractal Network for Single Image Super Resolution by Widening and Deepening
Jiahang Gu, Zhaowei Qu, Xiaoru Wang, Jiawang Dan, Junwei Sun

Auto-TLDR; Residual fractal convolutional network for single image super-resolution
Abstract Slides Poster Similar
Video Anomaly Detection by Estimating Likelihood of Representations

Auto-TLDR; Video Anomaly Detection in the latent feature space using a deep probabilistic model
Abstract Slides Poster Similar