Video Lightening with Dedicated CNN Architecture
Li-Wen Wang,
Wan-Chi Siu,
Zhi-Song Liu,
Chu-Tak Li,
P. K. Daniel Lun

Auto-TLDR; VLN: Video Lightening Network for Driving Assistant Systems in Dark Environment
Similar papers
Automatical Enhancement and Denoising of Extremely Low-Light Images
Yuda Song, Yunfang Zhu, Xin Du

Auto-TLDR; INSNet: Illumination and Noise Separation Network for Low-Light Image Restoring
Abstract Slides Poster Similar
Hierarchically Aggregated Residual Transformation for Single Image Super Resolution

Auto-TLDR; HARTnet: Hierarchically Aggregated Residual Transformation for Multi-Scale Super-resolution
Abstract Slides Poster Similar
Deep Fusion of RGB and NIR Paired Images Using Convolutional Neural Networks

Auto-TLDR; Deep Fusion of RGB and NIR paired images in low light condition using convolutional neural networks
Abstract Slides Poster Similar
Dynamic Low-Light Image Enhancement for Object Detection Via End-To-End Training
Haifeng Guo, Yirui Wu, Tong Lu

Auto-TLDR; Object Detection using Low-Light Image Enhancement for End-to-End Training
Abstract Slides Poster Similar
Thermal Image Enhancement Using Generative Adversarial Network for Pedestrian Detection
Mohamed Amine Marnissi, Hajer Fradi, Anis Sahbani, Najoua Essoukri Ben Amara

Auto-TLDR; Improving Visual Quality of Infrared Images for Pedestrian Detection Using Generative Adversarial Network
Abstract Slides Poster Similar
Video Reconstruction by Spatio-Temporal Fusion of Blurred-Coded Image Pair
Anupama S, Prasan Shedligeri, Abhishek Pal, Kaushik Mitr

Auto-TLDR; Recovering Video from Motion-Blurred and Coded Exposure Images Using Deep Learning
Abstract Slides Poster Similar
SIDGAN: Single Image Dehazing without Paired Supervision
Pan Wei, Xin Wang, Lei Wang, Ji Xiang, Zihan Wang

Auto-TLDR; DehazeGAN: An End-to-End Generative Adversarial Network for Image Dehazing
Abstract Slides Poster Similar
DSPNet: Deep Learning-Enabled Blind Reduction of Speckle Noise
Yuxu Lu, Meifang Yang, Liu Wen

Auto-TLDR; Deep Blind DeSPeckling Network for Imaging Applications
Wavelet Attention Embedding Networks for Video Super-Resolution
Young-Ju Choi, Young-Woon Lee, Byung-Gyu Kim

Auto-TLDR; Wavelet Attention Embedding Network for Video Super-Resolution
Abstract Slides Poster Similar
CURL: Neural Curve Layers for Global Image Enhancement
Sean Moran, Steven Mcdonagh, Greg Slabaugh

Auto-TLDR; CURL: Neural CURve Layers for Image Enhancement
Abstract Slides Poster Similar
Residual Learning of Video Frame Interpolation Using Convolutional LSTM

Auto-TLDR; Video Frame Interpolation Using Residual Learning and Convolutional LSTMs
Abstract Slides Poster Similar
Cross-Layer Information Refining Network for Single Image Super-Resolution
Hongyi Zhang, Wen Lu, Xiaopeng Sun

Auto-TLDR; Interlaced Spatial Attention Block for Single Image Super-Resolution
Abstract Slides Poster Similar
Boosting High-Level Vision with Joint Compression Artifacts Reduction and Super-Resolution
Xiaoyu Xiang, Qian Lin, Jan Allebach

Auto-TLDR; A Context-Aware Joint CAR and SR Neural Network for High-Resolution Text Recognition and Face Detection
Abstract Slides Poster Similar
Detail-Revealing Deep Low-Dose CT Reconstruction
Xinchen Ye, Yuyao Xu, Rui Xu, Shoji Kido, Noriyuki Tomiyama

Auto-TLDR; A Dual-branch Aggregation Network for Low-Dose CT Reconstruction
Abstract Slides Poster Similar
5D Light Field Synthesis from a Monocular Video
Kyuho Bae, Andre Ivan, Hajime Nagahara, In Kyu Park

Auto-TLDR; Synthesis of Light Field Video from Monocular Video using Deep Learning
MBD-GAN: Model-Based Image Deblurring with a Generative Adversarial Network

Auto-TLDR; Model-Based Deblurring GAN for Inverse Imaging
Abstract Slides Poster Similar
Fast Region-Adaptive Defogging and Enhancement for Outdoor Images Containing Sky
Zhan Li, Xiaopeng Zheng, Bir Bhanu, Shun Long, Qingfeng Zhang, Zhenghao Huang

Auto-TLDR; Image defogging and enhancement of hazy outdoor scenes using region-adaptive segmentation and region-ratio-based adaptive Gamma correction
Abstract Slides Poster Similar
LFIEM: Lightweight Filter-Based Image Enhancement Model
Oktai Tatanov, Aleksei Samarin

Auto-TLDR; Image Retouching Using Semi-supervised Learning for Mobile Devices
Abstract Slides Poster Similar
RSAN: Residual Subtraction and Attention Network for Single Image Super-Resolution
Shuo Wei, Xin Sun, Haoran Zhao, Junyu Dong

Auto-TLDR; RSAN: Residual subtraction and attention network for super-resolution
Selective Kernel and Motion-Emphasized Loss Based Attention-Guided Network for HDR Imaging of Dynamic Scenes
Yipeng Deng, Qin Liu, Takeshi Ikenaga

Auto-TLDR; SK-AHDRNet: A Deep Network with attention module and motion-emphasized loss function to produce ghost-free HDR images
Abstract Slides Poster Similar
Improving Low-Resolution Image Classification by Super-Resolution with Enhancing High-Frequency Content
Liguo Zhou, Guang Chen, Mingyue Feng, Alois Knoll

Auto-TLDR; Super-resolution for Low-Resolution Image Classification
Abstract Slides Poster Similar
Residual Fractal Network for Single Image Super Resolution by Widening and Deepening
Jiahang Gu, Zhaowei Qu, Xiaoru Wang, Jiawang Dan, Junwei Sun

Auto-TLDR; Residual fractal convolutional network for single image super-resolution
Abstract Slides Poster Similar
Deep Universal Blind Image Denoising

Auto-TLDR; Image Denoising with Deep Convolutional Neural Networks
Motion U-Net: Multi-Cue Encoder-Decoder Network for Motion Segmentation
Gani Rahmon, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; Motion U-Net: A Deep Learning Framework for Robust Moving Object Detection under Challenging Conditions
Abstract Slides Poster Similar
Progressive Splitting and Upscaling Structure for Super-Resolution

Auto-TLDR; PSUS: Progressive and Upscaling Layer for Single Image Super-Resolution
Abstract Slides Poster Similar
Deep Iterative Residual Convolutional Network for Single Image Super-Resolution
Rao Muhammad Umer, Gian Luca Foresti, Christian Micheloni

Auto-TLDR; ISRResCNet: Deep Iterative Super-Resolution Residual Convolutional Network for Single Image Super-resolution
Towards Artifacts-Free Image Defogging
Gabriele Graffieti, Davide Maltoni

Auto-TLDR; CurL-Defog: Learning Based Defogging with CycleGAN and HArD
A Lightweight Network to Learn Optical Flow from Event Data

Auto-TLDR; A lightweight pyramid network with attention mechanism to learn optical flow from events data
A NoGAN Approach for Image and Video Restoration and Compression Artifact Removal
Mameli Filippo, Marco Bertini, Leonardo Galteri, Alberto Del Bimbo

Auto-TLDR; Deep Neural Network for Image and Video Compression Artifact Removal and Restoration
Single Image Deblurring Using Bi-Attention Network

Auto-TLDR; Bi-Attention Neural Network for Single Image Deblurring
Deep Residual Attention Network for Hyperspectral Image Reconstruction

Auto-TLDR; Deep Convolutional Neural Network for Hyperspectral Image Reconstruction from a Snapshot
Abstract Slides Poster Similar
Face Anti-Spoofing Using Spatial Pyramid Pooling
Lei Shi, Zhuo Zhou, Zhenhua Guo

Auto-TLDR; Spatial Pyramid Pooling for Face Anti-Spoofing
Abstract Slides Poster Similar
Novel View Synthesis from a 6-DoF Pose by Two-Stage Networks
Xiang Guo, Bo Li, Yuchao Dai, Tongxin Zhang, Hui Deng

Auto-TLDR; Novel View Synthesis from a 6-DoF Pose Using Generative Adversarial Network
Abstract Slides Poster Similar
Adaptive Image Compression Using GAN Based Semantic-Perceptual Residual Compensation
Ruojing Wang, Zitang Sun, Sei-Ichiro Kamata, Weili Chen

Auto-TLDR; Adaptive Image Compression using GAN based Semantic-Perceptual Residual Compensation
Abstract Slides Poster Similar
Edge-Guided CNN for Denoising Images from Portable Ultrasound Devices
Yingnan Ma, Fei Yang, Anup Basu

Auto-TLDR; Edge-Guided Convolutional Neural Network for Portable Ultrasound Images
Abstract Slides Poster Similar
Coarse-To-Fine Foreground Segmentation Based on Co-Occurrence Pixel-Block and Spatio-Temporal Attention Model

Auto-TLDR; Foreground Segmentation from coarse to Fine Using Co-occurrence Pixel-Block Model for Dynamic Scene
Abstract Slides Poster Similar
LiNet: A Lightweight Network for Image Super Resolution
Armin Mehri, Parichehr Behjati Ardakani, Angel D. Sappa

Auto-TLDR; LiNet: A Compact Dense Network for Lightweight Super Resolution
Abstract Slides Poster Similar
DR2S: Deep Regression with Region Selection for Camera Quality Evaluation
Marcelin Tworski, Stéphane Lathuiliere, Salim Belkarfa, Attilio Fiandrotti, Marco Cagnazzo

Auto-TLDR; Texture Quality Estimation Using Deep Learning
Abstract Slides Poster Similar
SECI-GAN: Semantic and Edge Completion for Dynamic Objects Removal
Francesco Pinto, Andrea Romanoni, Matteo Matteucci, Phil Torr

Auto-TLDR; SECI-GAN: Semantic and Edge Conditioned Inpainting Generative Adversarial Network
Abstract Slides Poster Similar
A Dual-Branch Network for Infrared and Visible Image Fusion

Auto-TLDR; Image Fusion Using Autoencoder for Deep Learning
Abstract Slides Poster Similar
DID: A Nested Dense in Dense Structure with Variable Local Dense Blocks for Super-Resolution Image Reconstruction
Longxi Li, Hesen Feng, Bing Zheng, Lihong Ma, Jing Tian

Auto-TLDR; DID: Deep Super-Residual Dense Network for Image Super-resolution Reconstruction
Abstract Slides Poster Similar
GAN-Based Image Deblurring Using DCT Discriminator
Hiroki Tomosada, Takahiro Kudo, Takanori Fujisawa, Masaaki Ikehara
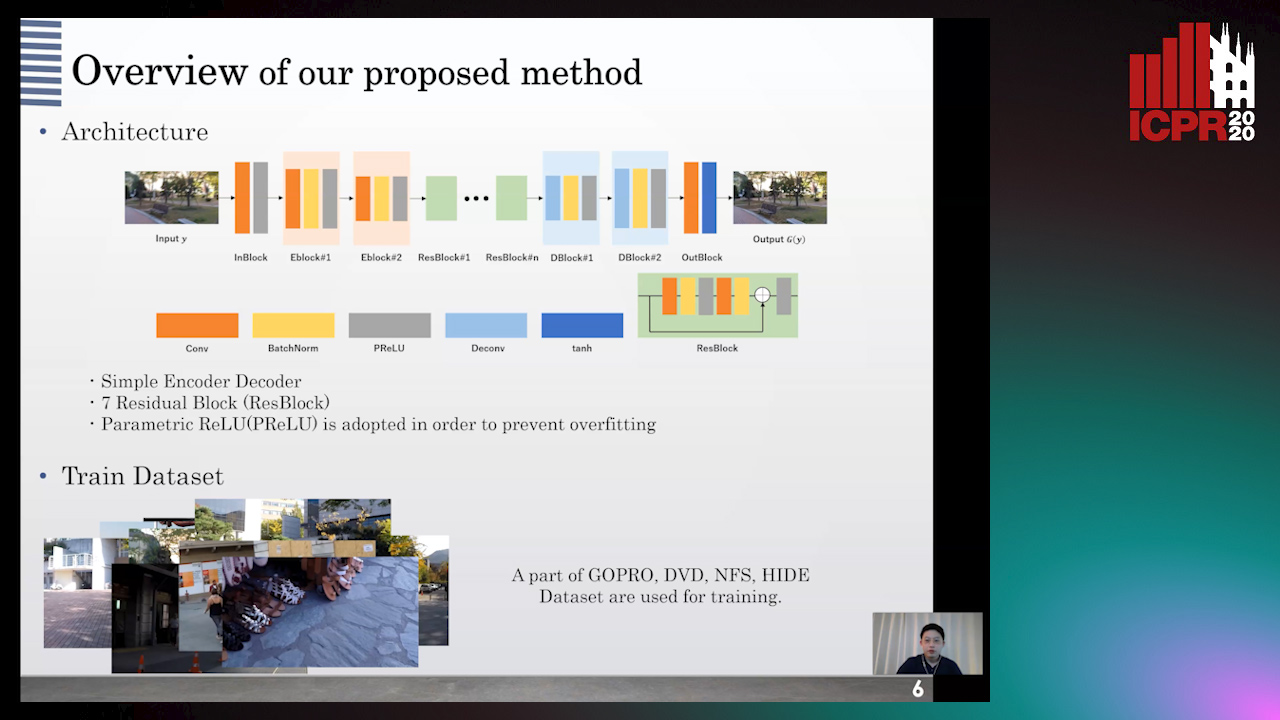
Auto-TLDR; DeblurDCTGAN: A Discrete Cosine Transform for Image Deblurring
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
A Novel Deep-Learning Pipeline for Light Field Image Based Material Recognition
Yunlong Wang, Kunbo Zhang, Zhenan Sun

Auto-TLDR; Factorize-Connect-Merge Deep Learning Pipeline for Light Field Image Based Material Recognition
Removing Raindrops from a Single Image Using Synthetic Data
Yoshihito Kokubo, Shusaku Asada, Hirotaka Maruyama, Masaru Koide, Kohei Yamamoto, Yoshihisa Suetsugu

Auto-TLDR; Raindrop Removal Using Synthetic Raindrop Data
Abstract Slides Poster Similar
Region-Based Non-Local Operation for Video Classification

Auto-TLDR; Regional-based Non-Local Operation for Deep Self-Attention in Convolutional Neural Networks
Abstract Slides Poster Similar
PSDNet: A Balanced Architecture of Accuracy and Parameters for Semantic Segmentation

Auto-TLDR; Pyramid Pooling Module with SE1Cblock and D2SUpsample Network (PSDNet)
Abstract Slides Poster Similar
Free-Form Image Inpainting Via Contrastive Attention Network
Xin Ma, Xiaoqiang Zhou, Huaibo Huang, Zhenhua Chai, Xiaolin Wei, Ran He

Auto-TLDR; Self-supervised Siamese inference for image inpainting