A NoGAN Approach for Image and Video Restoration and Compression Artifact Removal
Mameli Filippo,
Marco Bertini,
Leonardo Galteri,
Alberto Del Bimbo

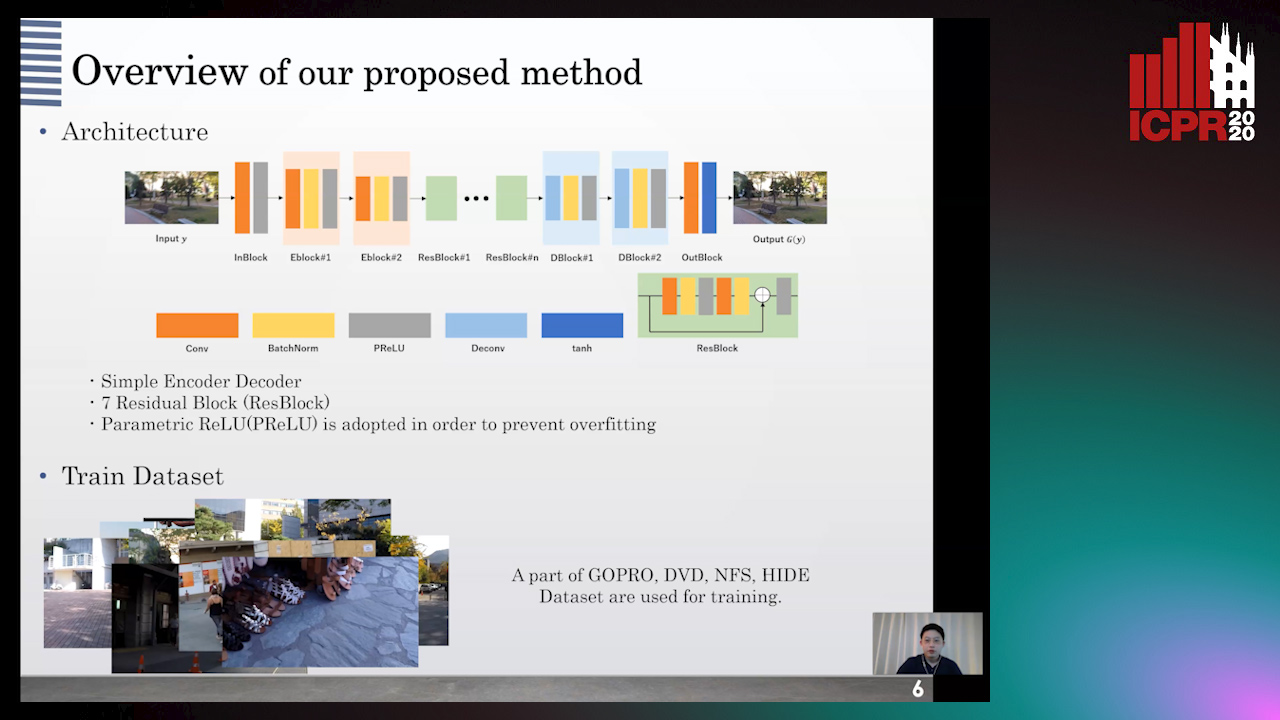
Auto-TLDR; Deep Neural Network for Image and Video Compression Artifact Removal and Restoration
Similar papers
Boosting High-Level Vision with Joint Compression Artifacts Reduction and Super-Resolution
Xiaoyu Xiang, Qian Lin, Jan Allebach

Auto-TLDR; A Context-Aware Joint CAR and SR Neural Network for High-Resolution Text Recognition and Face Detection
Abstract Slides Poster Similar
Tarsier: Evolving Noise Injection inSuper-Resolution GANs
Baptiste Roziere, Nathanaël Carraz Rakotonirina, Vlad Hosu, Rasoanaivo Andry, Hanhe Lin, Camille Couprie, Olivier Teytaud

Auto-TLDR; Evolutionary Super-Resolution using Diagonal CMA
Abstract Slides Poster Similar
Towards Artifacts-Free Image Defogging
Gabriele Graffieti, Davide Maltoni

Auto-TLDR; CurL-Defog: Learning Based Defogging with CycleGAN and HArD
Thermal Image Enhancement Using Generative Adversarial Network for Pedestrian Detection
Mohamed Amine Marnissi, Hajer Fradi, Anis Sahbani, Najoua Essoukri Ben Amara

Auto-TLDR; Improving Visual Quality of Infrared Images for Pedestrian Detection Using Generative Adversarial Network
Abstract Slides Poster Similar
Adaptive Image Compression Using GAN Based Semantic-Perceptual Residual Compensation
Ruojing Wang, Zitang Sun, Sei-Ichiro Kamata, Weili Chen

Auto-TLDR; Adaptive Image Compression using GAN based Semantic-Perceptual Residual Compensation
Abstract Slides Poster Similar
Robust Pedestrian Detection in Thermal Imagery Using Synthesized Images
My Kieu, Lorenzo Berlincioni, Leonardo Galteri, Marco Bertini, Andrew Bagdanov, Alberto Del Bimbo

Auto-TLDR; Improving Pedestrian Detection in the thermal domain using Generative Adversarial Network
Abstract Slides Poster Similar
Explorable Tone Mapping Operators
Su Chien-Chuan, Yu-Lun Liu, Hung Jin Lin, Ren Wang, Chia-Ping Chen, Yu-Lin Chang, Soo-Chang Pei

Auto-TLDR; Learning-based multimodal tone-mapping from HDR images
Abstract Slides Poster Similar
High Resolution Face Age Editing
Xu Yao, Gilles Puy, Alasdair Newson, Yann Gousseau, Pierre Hellier

Auto-TLDR; An Encoder-Decoder Architecture for Face Age editing on High Resolution Images
Abstract Slides Poster Similar
Fidelity-Controllable Extreme Image Compression with Generative Adversarial Networks
Shoma Iwai, Tomo Miyazaki, Yoshihiro Sugaya, Shinichiro Omachi

Auto-TLDR; GAN-based Image Compression at Low Bitrates
SIDGAN: Single Image Dehazing without Paired Supervision
Pan Wei, Xin Wang, Lei Wang, Ji Xiang, Zihan Wang

Auto-TLDR; DehazeGAN: An End-to-End Generative Adversarial Network for Image Dehazing
Abstract Slides Poster Similar
A Scalable Deep Neural Network to Detect Low Quality Images without a Reference
Auto-TLDR; A Deep Neural Network-based Algorithm for Non-reference Non-Reference Non-Referential Image Quality Metrics for Streaming Services
Abstract Slides Poster Similar
MBD-GAN: Model-Based Image Deblurring with a Generative Adversarial Network

Auto-TLDR; Model-Based Deblurring GAN for Inverse Imaging
Abstract Slides Poster Similar
On-Device Text Image Super Resolution
Dhruval Jain, Arun Prabhu, Gopi Ramena, Manoj Goyal, Debi Mohanty, Naresh Purre, Sukumar Moharana

Auto-TLDR; A Novel Deep Neural Network for Super-Resolution on Low Resolution Text Images
Abstract Slides Poster Similar
Boundary Guided Image Translation for Pose Estimation from Ultra-Low Resolution Thermal Sensor
Kohei Kurihara, Tianren Wang, Teng Zhang, Brian Carrington Lovell

Auto-TLDR; Pose Estimation on Low-Resolution Thermal Images Using Image-to-Image Translation Architecture
Abstract Slides Poster Similar
SECI-GAN: Semantic and Edge Completion for Dynamic Objects Removal
Francesco Pinto, Andrea Romanoni, Matteo Matteucci, Phil Torr

Auto-TLDR; SECI-GAN: Semantic and Edge Conditioned Inpainting Generative Adversarial Network
Abstract Slides Poster Similar
Deep Realistic Novel View Generation for City-Scale Aerial Images
Koundinya Nouduri, Ke Gao, Joshua Fraser, Shizeng Yao, Hadi Aliakbarpour, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; End-to-End 3D Voxel Renderer for Multi-View Stereo Data Generation and Evaluation
Abstract Slides Poster Similar
Multi-Laplacian GAN with Edge Enhancement for Face Super Resolution

Auto-TLDR; Face Image Super-Resolution with Enhanced Edge Information
Abstract Slides Poster Similar
Local Facial Attribute Transfer through Inpainting
Ricard Durall, Franz-Josef Pfreundt, Janis Keuper

Auto-TLDR; Attribute Transfer Inpainting Generative Adversarial Network
Abstract Slides Poster Similar
On the Use of Benford's Law to Detect GAN-Generated Images
Nicolo Bonettini, Paolo Bestagini, Simone Milani, Stefano Tubaro

Auto-TLDR; Using Benford's Law to Detect GAN-generated Images from Natural Images
Abstract Slides Poster Similar
DR2S: Deep Regression with Region Selection for Camera Quality Evaluation
Marcelin Tworski, Stéphane Lathuiliere, Salim Belkarfa, Attilio Fiandrotti, Marco Cagnazzo

Auto-TLDR; Texture Quality Estimation Using Deep Learning
Abstract Slides Poster Similar
Super-Resolution Guided Pore Detection for Fingerprint Recognition
Syeda Nyma Ferdous, Ali Dabouei, Jeremy Dawson, Nasser M. Nasarabadi

Auto-TLDR; Super-Resolution Generative Adversarial Network for Fingerprint Recognition Using Pore Features
Abstract Slides Poster Similar
Learning Disentangled Representations for Identity Preserving Surveillance Face Camouflage
Jingzhi Li, Lutong Han, Hua Zhang, Xiaoguang Han, Jingguo Ge, Xiaochu Cao

Auto-TLDR; Individual Face Privacy under Surveillance Scenario with Multi-task Loss Function
Continuous Learning of Face Attribute Synthesis
Ning Xin, Shaohui Xu, Fangzhe Nan, Xiaoli Dong, Weijun Li, Yuanzhou Yao

Auto-TLDR; Continuous Learning for Face Attribute Synthesis
Abstract Slides Poster Similar
Mask-Based Style-Controlled Image Synthesis Using a Mask Style Encoder
Jaehyeong Cho, Wataru Shimoda, Keiji Yanai

Auto-TLDR; Style-controlled Image Synthesis from Semantic Segmentation masks using GANs
Abstract Slides Poster Similar
Global Image Sentiment Transfer
Jie An, Tianlang Chen, Songyang Zhang, Jiebo Luo

Auto-TLDR; Image Sentiment Transfer Using DenseNet121 Architecture
Wavelet Attention Embedding Networks for Video Super-Resolution
Young-Ju Choi, Young-Woon Lee, Byung-Gyu Kim

Auto-TLDR; Wavelet Attention Embedding Network for Video Super-Resolution
Abstract Slides Poster Similar
Improving Low-Resolution Image Classification by Super-Resolution with Enhancing High-Frequency Content
Liguo Zhou, Guang Chen, Mingyue Feng, Alois Knoll

Auto-TLDR; Super-resolution for Low-Resolution Image Classification
Abstract Slides Poster Similar
LFIEM: Lightweight Filter-Based Image Enhancement Model
Oktai Tatanov, Aleksei Samarin

Auto-TLDR; Image Retouching Using Semi-supervised Learning for Mobile Devices
Abstract Slides Poster Similar
TinyVIRAT: Low-Resolution Video Action Recognition
Ugur Demir, Yogesh Rawat, Mubarak Shah

Auto-TLDR; TinyVIRAT: A Progressive Generative Approach for Action Recognition in Videos
Abstract Slides Poster Similar
Stylized-Colorization for Line Arts
Tzu-Ting Fang, Minh Duc Vo, Akihiro Sugimoto, Shang-Hong Lai

Auto-TLDR; Stylized-colorization using GAN-based End-to-End Model for Anime
Abstract Slides Poster Similar
GAN-Based Image Deblurring Using DCT Discriminator
Hiroki Tomosada, Takahiro Kudo, Takanori Fujisawa, Masaaki Ikehara
Auto-TLDR; DeblurDCTGAN: A Discrete Cosine Transform for Image Deblurring
Abstract Slides Poster Similar
Residual Fractal Network for Single Image Super Resolution by Widening and Deepening
Jiahang Gu, Zhaowei Qu, Xiaoru Wang, Jiawang Dan, Junwei Sun

Auto-TLDR; Residual fractal convolutional network for single image super-resolution
Abstract Slides Poster Similar
A GAN-Based Blind Inpainting Method for Masonry Wall Images
Yahya Ibrahim, Balázs Nagy, Csaba Benedek

Auto-TLDR; An End-to-End Blind Inpainting Algorithm for Masonry Wall Images
Abstract Slides Poster Similar
Deep Iterative Residual Convolutional Network for Single Image Super-Resolution
Rao Muhammad Umer, Gian Luca Foresti, Christian Micheloni

Auto-TLDR; ISRResCNet: Deep Iterative Super-Resolution Residual Convolutional Network for Single Image Super-resolution
Detail-Revealing Deep Low-Dose CT Reconstruction
Xinchen Ye, Yuyao Xu, Rui Xu, Shoji Kido, Noriyuki Tomiyama

Auto-TLDR; A Dual-branch Aggregation Network for Low-Dose CT Reconstruction
Abstract Slides Poster Similar
An Unsupervised Approach towards Varying Human Skin Tone Using Generative Adversarial Networks
Debapriya Roy, Diganta Mukherjee, Bhabatosh Chanda

Auto-TLDR; Unsupervised Skin Tone Change Using Augmented Reality Based Models
Abstract Slides Poster Similar
Edge-Guided CNN for Denoising Images from Portable Ultrasound Devices
Yingnan Ma, Fei Yang, Anup Basu

Auto-TLDR; Edge-Guided Convolutional Neural Network for Portable Ultrasound Images
Abstract Slides Poster Similar
LiNet: A Lightweight Network for Image Super Resolution
Armin Mehri, Parichehr Behjati Ardakani, Angel D. Sappa

Auto-TLDR; LiNet: A Compact Dense Network for Lightweight Super Resolution
Abstract Slides Poster Similar
Deep Universal Blind Image Denoising

Auto-TLDR; Image Denoising with Deep Convolutional Neural Networks
A Quantitative Evaluation Framework of Video De-Identification Methods
Sathya Bursic, Alessandro D'Amelio, Marco Granato, Giuliano Grossi, Raffaella Lanzarotti

Auto-TLDR; Face de-identification using photo-reality and facial expressions
Abstract Slides Poster Similar
UCCTGAN: Unsupervised Clothing Color Transformation Generative Adversarial Network
Shuming Sun, Xiaoqiang Li, Jide Li

Auto-TLDR; An Unsupervised Clothing Color Transformation Generative Adversarial Network
Abstract Slides Poster Similar
Video Face Manipulation Detection through Ensemble of CNNs
Nicolo Bonettini, Edoardo Daniele Cannas, Sara Mandelli, Luca Bondi, Paolo Bestagini, Stefano Tubaro

Auto-TLDR; Face Manipulation Detection in Video Sequences Using Convolutional Neural Networks
Galaxy Image Translation with Semi-Supervised Noise-Reconstructed Generative Adversarial Networks
Qiufan Lin, Dominique Fouchez, Jérôme Pasquet

Auto-TLDR; Semi-supervised Image Translation with Generative Adversarial Networks Using Paired and Unpaired Images
Abstract Slides Poster Similar
Free-Form Image Inpainting Via Contrastive Attention Network
Xin Ma, Xiaoqiang Zhou, Huaibo Huang, Zhenhua Chai, Xiaolin Wei, Ran He

Auto-TLDR; Self-supervised Siamese inference for image inpainting
Dual-MTGAN: Stochastic and Deterministic Motion Transfer for Image-To-Video Synthesis
Fu-En Yang, Jing-Cheng Chang, Yuan-Hao Lee, Yu-Chiang Frank Wang

Auto-TLDR; Dual Motion Transfer GAN for Convolutional Neural Networks
Abstract Slides Poster Similar
DSPNet: Deep Learning-Enabled Blind Reduction of Speckle Noise
Yuxu Lu, Meifang Yang, Liu Wen

Auto-TLDR; Deep Blind DeSPeckling Network for Imaging Applications
On the Impact of Lossy Image and Video Compression on the Performance of Deep Convolutional Neural Network Architectures
Matt Poyser, Toby Breckon, Amir Atapour-Abarghouei

Auto-TLDR; The Impact of Lossy Image Compression on Deep Neural Networks for Image-based Detection and Classification
RSAN: Residual Subtraction and Attention Network for Single Image Super-Resolution
Shuo Wei, Xin Sun, Haoran Zhao, Junyu Dong

Auto-TLDR; RSAN: Residual subtraction and attention network for super-resolution