DSPNet: Deep Learning-Enabled Blind Reduction of Speckle Noise
Yuxu Lu,
Meifang Yang,
Liu Wen

Auto-TLDR; Deep Blind DeSPeckling Network for Imaging Applications
Similar papers
Edge-Guided CNN for Denoising Images from Portable Ultrasound Devices
Yingnan Ma, Fei Yang, Anup Basu

Auto-TLDR; Edge-Guided Convolutional Neural Network for Portable Ultrasound Images
Abstract Slides Poster Similar
Ultrasound Image Restoration Using Weighted Nuclear Norm Minimization
Hanmei Yang, Ye Luo, Jianwei Lu, Jian Lu

Auto-TLDR; A Nonconvex Low-Rank Matrix Approximation Model for Ultrasound Images Restoration
Automatical Enhancement and Denoising of Extremely Low-Light Images
Yuda Song, Yunfang Zhu, Xin Du

Auto-TLDR; INSNet: Illumination and Noise Separation Network for Low-Light Image Restoring
Abstract Slides Poster Similar
Deep Universal Blind Image Denoising

Auto-TLDR; Image Denoising with Deep Convolutional Neural Networks
Video Lightening with Dedicated CNN Architecture
Li-Wen Wang, Wan-Chi Siu, Zhi-Song Liu, Chu-Tak Li, P. K. Daniel Lun

Auto-TLDR; VLN: Video Lightening Network for Driving Assistant Systems in Dark Environment
Abstract Slides Poster Similar
Boosting High-Level Vision with Joint Compression Artifacts Reduction and Super-Resolution
Xiaoyu Xiang, Qian Lin, Jan Allebach

Auto-TLDR; A Context-Aware Joint CAR and SR Neural Network for High-Resolution Text Recognition and Face Detection
Abstract Slides Poster Similar
DCT/IDCT Filter Design for Ultrasound Image Filtering
Barmak Honarvar Shakibaei Asli, Jan Flusser, Yifan Zhao, John Ahmet Erkoyuncu, Rajkumar Roy

Auto-TLDR; Finite impulse response digital filter using DCT-II and inverse DCT
Abstract Slides Poster Similar
Multi-scale Processing of Noisy Images using Edge Preservation Losses

Auto-TLDR; Multi-scale U-net for Noisy Image Detection and Denoising
Abstract Slides Poster Similar
Deep Fusion of RGB and NIR Paired Images Using Convolutional Neural Networks

Auto-TLDR; Deep Fusion of RGB and NIR paired images in low light condition using convolutional neural networks
Abstract Slides Poster Similar
Detail-Revealing Deep Low-Dose CT Reconstruction
Xinchen Ye, Yuyao Xu, Rui Xu, Shoji Kido, Noriyuki Tomiyama

Auto-TLDR; A Dual-branch Aggregation Network for Low-Dose CT Reconstruction
Abstract Slides Poster Similar
RSAN: Residual Subtraction and Attention Network for Single Image Super-Resolution
Shuo Wei, Xin Sun, Haoran Zhao, Junyu Dong

Auto-TLDR; RSAN: Residual subtraction and attention network for super-resolution
Hierarchically Aggregated Residual Transformation for Single Image Super Resolution

Auto-TLDR; HARTnet: Hierarchically Aggregated Residual Transformation for Multi-Scale Super-resolution
Abstract Slides Poster Similar
Face Super-Resolution Network with Incremental Enhancement of Facial Parsing Information
Shuang Liu, Chengyi Xiong, Zhirong Gao

Auto-TLDR; Learning-based Face Super-Resolution with Incremental Boosting Facial Parsing Information
Abstract Slides Poster Similar
A NoGAN Approach for Image and Video Restoration and Compression Artifact Removal
Mameli Filippo, Marco Bertini, Leonardo Galteri, Alberto Del Bimbo

Auto-TLDR; Deep Neural Network for Image and Video Compression Artifact Removal and Restoration
SIDGAN: Single Image Dehazing without Paired Supervision
Pan Wei, Xin Wang, Lei Wang, Ji Xiang, Zihan Wang

Auto-TLDR; DehazeGAN: An End-to-End Generative Adversarial Network for Image Dehazing
Abstract Slides Poster Similar
D3Net: Joint Demosaicking, Deblurring and Deringing
Tomas Kerepecky, Filip Sroubek

Auto-TLDR; Joint demosaicking deblurring and deringing network with light-weight architecture inspired by the alternating direction method of multipliers
MBD-GAN: Model-Based Image Deblurring with a Generative Adversarial Network

Auto-TLDR; Model-Based Deblurring GAN for Inverse Imaging
Abstract Slides Poster Similar
Thermal Image Enhancement Using Generative Adversarial Network for Pedestrian Detection
Mohamed Amine Marnissi, Hajer Fradi, Anis Sahbani, Najoua Essoukri Ben Amara

Auto-TLDR; Improving Visual Quality of Infrared Images for Pedestrian Detection Using Generative Adversarial Network
Abstract Slides Poster Similar
Deep Iterative Residual Convolutional Network for Single Image Super-Resolution
Rao Muhammad Umer, Gian Luca Foresti, Christian Micheloni

Auto-TLDR; ISRResCNet: Deep Iterative Super-Resolution Residual Convolutional Network for Single Image Super-resolution
Adaptive Image Compression Using GAN Based Semantic-Perceptual Residual Compensation
Ruojing Wang, Zitang Sun, Sei-Ichiro Kamata, Weili Chen

Auto-TLDR; Adaptive Image Compression using GAN based Semantic-Perceptual Residual Compensation
Abstract Slides Poster Similar
GAN-Based Image Deblurring Using DCT Discriminator
Hiroki Tomosada, Takahiro Kudo, Takanori Fujisawa, Masaaki Ikehara
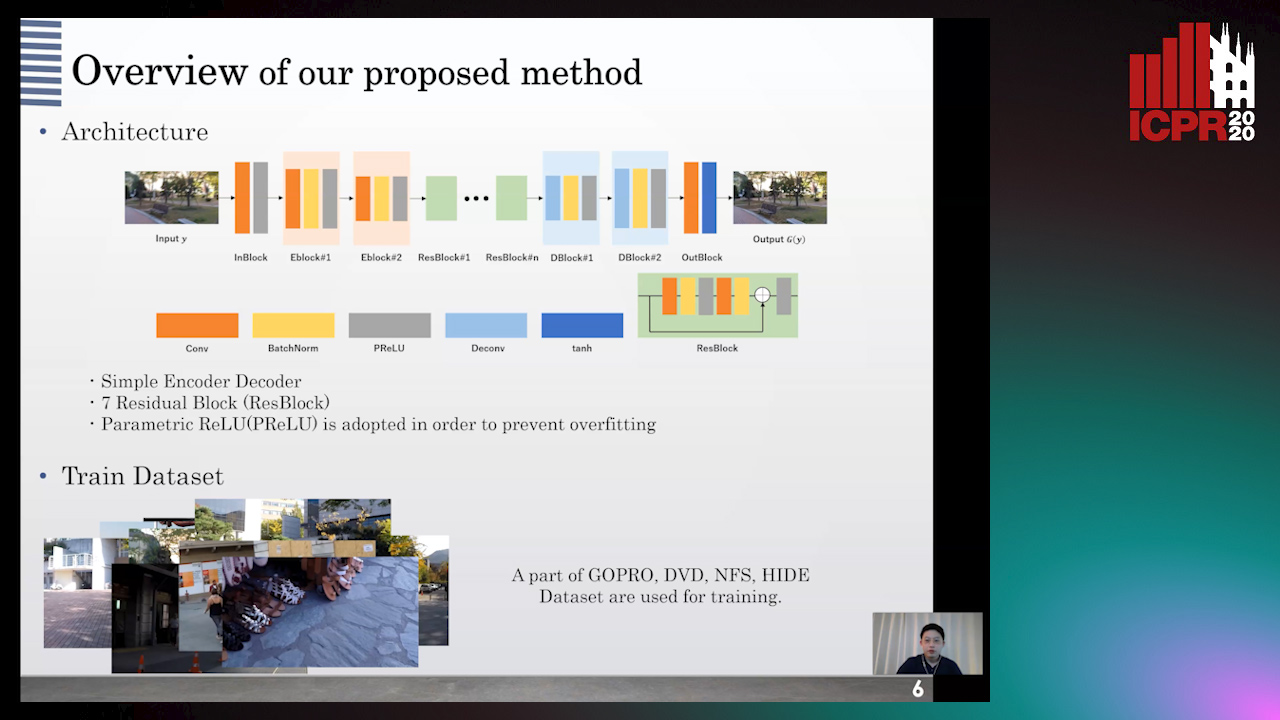
Auto-TLDR; DeblurDCTGAN: A Discrete Cosine Transform for Image Deblurring
Abstract Slides Poster Similar
SECI-GAN: Semantic and Edge Completion for Dynamic Objects Removal
Francesco Pinto, Andrea Romanoni, Matteo Matteucci, Phil Torr

Auto-TLDR; SECI-GAN: Semantic and Edge Conditioned Inpainting Generative Adversarial Network
Abstract Slides Poster Similar
LFIEM: Lightweight Filter-Based Image Enhancement Model
Oktai Tatanov, Aleksei Samarin

Auto-TLDR; Image Retouching Using Semi-supervised Learning for Mobile Devices
Abstract Slides Poster Similar
Selective Kernel and Motion-Emphasized Loss Based Attention-Guided Network for HDR Imaging of Dynamic Scenes
Yipeng Deng, Qin Liu, Takeshi Ikenaga

Auto-TLDR; SK-AHDRNet: A Deep Network with attention module and motion-emphasized loss function to produce ghost-free HDR images
Abstract Slides Poster Similar
Deep Realistic Novel View Generation for City-Scale Aerial Images
Koundinya Nouduri, Ke Gao, Joshua Fraser, Shizeng Yao, Hadi Aliakbarpour, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; End-to-End 3D Voxel Renderer for Multi-View Stereo Data Generation and Evaluation
Abstract Slides Poster Similar
DR2S: Deep Regression with Region Selection for Camera Quality Evaluation
Marcelin Tworski, Stéphane Lathuiliere, Salim Belkarfa, Attilio Fiandrotti, Marco Cagnazzo

Auto-TLDR; Texture Quality Estimation Using Deep Learning
Abstract Slides Poster Similar
Deep Residual Attention Network for Hyperspectral Image Reconstruction

Auto-TLDR; Deep Convolutional Neural Network for Hyperspectral Image Reconstruction from a Snapshot
Abstract Slides Poster Similar
Residual Fractal Network for Single Image Super Resolution by Widening and Deepening
Jiahang Gu, Zhaowei Qu, Xiaoru Wang, Jiawang Dan, Junwei Sun

Auto-TLDR; Residual fractal convolutional network for single image super-resolution
Abstract Slides Poster Similar
Multi-focus Image Fusion for Confocal Microscopy Using U-Net Regression Map
Md Maruf Hossain Shuvo, Yasmin M. Kassim, Filiz Bunyak, Olga V. Glinskii, Leike Xie, Vladislav V Glinsky, Virginia H. Huxley, Kannappan Palaniappan

Auto-TLDR; Independent Single Channel U-Net Fusion for Multi-focus Microscopy Images
Abstract Slides Poster Similar
Attention Pyramid Module for Scene Recognition
Zhinan Qiao, Xiaohui Yuan, Chengyuan Zhuang, Abolfazl Meyarian

Auto-TLDR; Attention Pyramid Module for Multi-Scale Scene Recognition
Abstract Slides Poster Similar
Towards Artifacts-Free Image Defogging
Gabriele Graffieti, Davide Maltoni

Auto-TLDR; CurL-Defog: Learning Based Defogging with CycleGAN and HArD
CSpA-DN: Channel and Spatial Attention Dense Network for Fusing PET and MRI Images
Bicao Li, Zhoufeng Liu, Shan Gao, Jenq-Neng Hwang, Jun Sun, Zongmin Wang

Auto-TLDR; CSpA-DN: Unsupervised Fusion of PET and MR Images with Channel and Spatial Attention
Abstract Slides Poster Similar
Tarsier: Evolving Noise Injection inSuper-Resolution GANs
Baptiste Roziere, Nathanaël Carraz Rakotonirina, Vlad Hosu, Rasoanaivo Andry, Hanhe Lin, Camille Couprie, Olivier Teytaud

Auto-TLDR; Evolutionary Super-Resolution using Diagonal CMA
Abstract Slides Poster Similar
Free-Form Image Inpainting Via Contrastive Attention Network
Xin Ma, Xiaoqiang Zhou, Huaibo Huang, Zhenhua Chai, Xiaolin Wei, Ran He

Auto-TLDR; Self-supervised Siamese inference for image inpainting
Triplet-Path Dilated Network for Detection and Segmentation of General Pathological Images
Jiaqi Luo, Zhicheng Zhao, Fei Su, Limei Guo

Auto-TLDR; Triplet-path Network for One-Stage Object Detection and Segmentation in Pathological Images
5D Light Field Synthesis from a Monocular Video
Kyuho Bae, Andre Ivan, Hajime Nagahara, In Kyu Park

Auto-TLDR; Synthesis of Light Field Video from Monocular Video using Deep Learning
A Multi-Focus Image Fusion Method Based on Fractal Dimension and Guided Filtering
Nikoo Dehghani, Ehsanollah Kabir

Auto-TLDR; Fractal Dimension-based Multi-focus Image Fusion with Guide Filtering
Abstract Slides Poster Similar
Joint Compressive Autoencoders for Full-Image-To-Image Hiding
Xiyao Liu, Ziping Ma, Xingbei Guo, Jialu Hou, Lei Wang, Gerald Schaefer, Hui Fang

Auto-TLDR; J-CAE: Joint Compressive Autoencoder for Image Hiding
Abstract Slides Poster Similar
Multi-Scale Residual Pyramid Attention Network for Monocular Depth Estimation
Jing Liu, Xiaona Zhang, Zhaoxin Li, Tianlu Mao

Auto-TLDR; Multi-scale Residual Pyramid Attention Network for Monocular Depth Estimation
Abstract Slides Poster Similar
Dynamic Low-Light Image Enhancement for Object Detection Via End-To-End Training
Haifeng Guo, Yirui Wu, Tong Lu

Auto-TLDR; Object Detection using Low-Light Image Enhancement for End-to-End Training
Abstract Slides Poster Similar
Quantifying Model Uncertainty in Inverse Problems Via Bayesian Deep Gradient Descent
Riccardo Barbano, Chen Zhang, Simon Arridge, Bangti Jin

Auto-TLDR; Bayesian Neural Networks for Inverse Reconstruction via Bayesian Knowledge-Aided Computation
Abstract Slides Poster Similar
A Dual-Branch Network for Infrared and Visible Image Fusion

Auto-TLDR; Image Fusion Using Autoencoder for Deep Learning
Abstract Slides Poster Similar
DID: A Nested Dense in Dense Structure with Variable Local Dense Blocks for Super-Resolution Image Reconstruction
Longxi Li, Hesen Feng, Bing Zheng, Lihong Ma, Jing Tian

Auto-TLDR; DID: Deep Super-Residual Dense Network for Image Super-resolution Reconstruction
Abstract Slides Poster Similar
Single Image Deblurring Using Bi-Attention Network

Auto-TLDR; Bi-Attention Neural Network for Single Image Deblurring
DE-Net: Dilated Encoder Network for Automated Tongue Segmentation
Hui Tang, Bin Wang, Jun Zhou, Yongsheng Gao

Auto-TLDR; Automated Tongue Image Segmentation using De-Net
Abstract Slides Poster Similar
Novel View Synthesis from a 6-DoF Pose by Two-Stage Networks
Xiang Guo, Bo Li, Yuchao Dai, Tongxin Zhang, Hui Deng

Auto-TLDR; Novel View Synthesis from a 6-DoF Pose Using Generative Adversarial Network
Abstract Slides Poster Similar
Do Not Treat Boundaries and Regions Differently: An Example on Heart Left Atrial Segmentation
Zhou Zhao, Elodie Puybareau, Nicolas Boutry, Thierry Geraud

Auto-TLDR; Attention Full Convolutional Network for Atrial Segmentation using ResNet-101 Architecture
FOANet: A Focus of Attention Network with Application to Myocardium Segmentation
Zhou Zhao, Elodie Puybareau, Nicolas Boutry, Thierry Geraud

Auto-TLDR; FOANet: A Hybrid Loss Function for Myocardium Segmentation of Cardiac Magnetic Resonance Images
Abstract Slides Poster Similar