Edge-Guided CNN for Denoising Images from Portable Ultrasound Devices
Yingnan Ma,
Fei Yang,
Anup Basu

Auto-TLDR; Edge-Guided Convolutional Neural Network for Portable Ultrasound Images
Similar papers
Ultrasound Image Restoration Using Weighted Nuclear Norm Minimization
Hanmei Yang, Ye Luo, Jianwei Lu, Jian Lu

Auto-TLDR; A Nonconvex Low-Rank Matrix Approximation Model for Ultrasound Images Restoration
DSPNet: Deep Learning-Enabled Blind Reduction of Speckle Noise
Yuxu Lu, Meifang Yang, Liu Wen

Auto-TLDR; Deep Blind DeSPeckling Network for Imaging Applications
Deep Universal Blind Image Denoising

Auto-TLDR; Image Denoising with Deep Convolutional Neural Networks
Multi-scale Processing of Noisy Images using Edge Preservation Losses

Auto-TLDR; Multi-scale U-net for Noisy Image Detection and Denoising
Abstract Slides Poster Similar
DCT/IDCT Filter Design for Ultrasound Image Filtering
Barmak Honarvar Shakibaei Asli, Jan Flusser, Yifan Zhao, John Ahmet Erkoyuncu, Rajkumar Roy

Auto-TLDR; Finite impulse response digital filter using DCT-II and inverse DCT
Abstract Slides Poster Similar
Automatical Enhancement and Denoising of Extremely Low-Light Images
Yuda Song, Yunfang Zhu, Xin Du

Auto-TLDR; INSNet: Illumination and Noise Separation Network for Low-Light Image Restoring
Abstract Slides Poster Similar
MBD-GAN: Model-Based Image Deblurring with a Generative Adversarial Network

Auto-TLDR; Model-Based Deblurring GAN for Inverse Imaging
Abstract Slides Poster Similar
Deep Iterative Residual Convolutional Network for Single Image Super-Resolution
Rao Muhammad Umer, Gian Luca Foresti, Christian Micheloni

Auto-TLDR; ISRResCNet: Deep Iterative Super-Resolution Residual Convolutional Network for Single Image Super-resolution
D3Net: Joint Demosaicking, Deblurring and Deringing
Tomas Kerepecky, Filip Sroubek

Auto-TLDR; Joint demosaicking deblurring and deringing network with light-weight architecture inspired by the alternating direction method of multipliers
Detail-Revealing Deep Low-Dose CT Reconstruction
Xinchen Ye, Yuyao Xu, Rui Xu, Shoji Kido, Noriyuki Tomiyama

Auto-TLDR; A Dual-branch Aggregation Network for Low-Dose CT Reconstruction
Abstract Slides Poster Similar
Merged 1D-2D Deep Convolutional Neural Networks for Nerve Detection in Ultrasound Images
Mohammad Alkhatib, Adel Hafiane, Pierre Vieyres

Auto-TLDR; A Deep Neural Network for Deep Neural Networks to Detect Median Nerve in Ultrasound-Guided Regional Anesthesia
Abstract Slides Poster Similar
Hierarchically Aggregated Residual Transformation for Single Image Super Resolution

Auto-TLDR; HARTnet: Hierarchically Aggregated Residual Transformation for Multi-Scale Super-resolution
Abstract Slides Poster Similar
Boosting High-Level Vision with Joint Compression Artifacts Reduction and Super-Resolution
Xiaoyu Xiang, Qian Lin, Jan Allebach

Auto-TLDR; A Context-Aware Joint CAR and SR Neural Network for High-Resolution Text Recognition and Face Detection
Abstract Slides Poster Similar
SIDGAN: Single Image Dehazing without Paired Supervision
Pan Wei, Xin Wang, Lei Wang, Ji Xiang, Zihan Wang

Auto-TLDR; DehazeGAN: An End-to-End Generative Adversarial Network for Image Dehazing
Abstract Slides Poster Similar
Towards Artifacts-Free Image Defogging
Gabriele Graffieti, Davide Maltoni

Auto-TLDR; CurL-Defog: Learning Based Defogging with CycleGAN and HArD
A NoGAN Approach for Image and Video Restoration and Compression Artifact Removal
Mameli Filippo, Marco Bertini, Leonardo Galteri, Alberto Del Bimbo

Auto-TLDR; Deep Neural Network for Image and Video Compression Artifact Removal and Restoration
Deep Realistic Novel View Generation for City-Scale Aerial Images
Koundinya Nouduri, Ke Gao, Joshua Fraser, Shizeng Yao, Hadi Aliakbarpour, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; End-to-End 3D Voxel Renderer for Multi-View Stereo Data Generation and Evaluation
Abstract Slides Poster Similar
Semantic Segmentation of Breast Ultrasound Image with Pyramid Fuzzy Uncertainty Reduction and Direction Connectedness Feature
Kuan Huang, Yingtao Zhang, Heng-Da Cheng, Ping Xing, Boyu Zhang

Auto-TLDR; Uncertainty-Based Deep Learning for Breast Ultrasound Image Segmentation
Abstract Slides Poster Similar
DE-Net: Dilated Encoder Network for Automated Tongue Segmentation
Hui Tang, Bin Wang, Jun Zhou, Yongsheng Gao

Auto-TLDR; Automated Tongue Image Segmentation using De-Net
Abstract Slides Poster Similar
Thermal Image Enhancement Using Generative Adversarial Network for Pedestrian Detection
Mohamed Amine Marnissi, Hajer Fradi, Anis Sahbani, Najoua Essoukri Ben Amara

Auto-TLDR; Improving Visual Quality of Infrared Images for Pedestrian Detection Using Generative Adversarial Network
Abstract Slides Poster Similar
Deep Fusion of RGB and NIR Paired Images Using Convolutional Neural Networks

Auto-TLDR; Deep Fusion of RGB and NIR paired images in low light condition using convolutional neural networks
Abstract Slides Poster Similar
Near-Infrared Depth-Independent Image Dehazing using Haar Wavelets
Sumit Laha, Ankit Sharma, Shengnan Hu, Hassan Foroosh

Auto-TLDR; A fusion algorithm for haze removal using Haar wavelets
Abstract Slides Poster Similar
Residual Fractal Network for Single Image Super Resolution by Widening and Deepening
Jiahang Gu, Zhaowei Qu, Xiaoru Wang, Jiawang Dan, Junwei Sun

Auto-TLDR; Residual fractal convolutional network for single image super-resolution
Abstract Slides Poster Similar
Fast Region-Adaptive Defogging and Enhancement for Outdoor Images Containing Sky
Zhan Li, Xiaopeng Zheng, Bir Bhanu, Shun Long, Qingfeng Zhang, Zhenghao Huang

Auto-TLDR; Image defogging and enhancement of hazy outdoor scenes using region-adaptive segmentation and region-ratio-based adaptive Gamma correction
Abstract Slides Poster Similar
A Comparison of Neural Network Approaches for Melanoma Classification
Maria Frasca, Michele Nappi, Michele Risi, Genoveffa Tortora, Alessia Auriemma Citarella

Auto-TLDR; Classification of Melanoma Using Deep Neural Network Methodologies
Abstract Slides Poster Similar
Video Lightening with Dedicated CNN Architecture
Li-Wen Wang, Wan-Chi Siu, Zhi-Song Liu, Chu-Tak Li, P. K. Daniel Lun

Auto-TLDR; VLN: Video Lightening Network for Driving Assistant Systems in Dark Environment
Abstract Slides Poster Similar
A Benchmark Dataset for Segmenting Liver, Vasculature and Lesions from Large-Scale Computed Tomography Data
Bo Wang, Zhengqing Xu, Wei Xu, Qingsen Yan, Liang Zhang, Zheng You

Auto-TLDR; The Biggest Treatment-Oriented Liver Cancer Dataset for Segmentation
Abstract Slides Poster Similar
LFIEM: Lightweight Filter-Based Image Enhancement Model
Oktai Tatanov, Aleksei Samarin

Auto-TLDR; Image Retouching Using Semi-supervised Learning for Mobile Devices
Abstract Slides Poster Similar
DR2S: Deep Regression with Region Selection for Camera Quality Evaluation
Marcelin Tworski, Stéphane Lathuiliere, Salim Belkarfa, Attilio Fiandrotti, Marco Cagnazzo

Auto-TLDR; Texture Quality Estimation Using Deep Learning
Abstract Slides Poster Similar
Dynamic Low-Light Image Enhancement for Object Detection Via End-To-End Training
Haifeng Guo, Yirui Wu, Tong Lu

Auto-TLDR; Object Detection using Low-Light Image Enhancement for End-to-End Training
Abstract Slides Poster Similar
GAN-Based Image Deblurring Using DCT Discriminator
Hiroki Tomosada, Takahiro Kudo, Takanori Fujisawa, Masaaki Ikehara
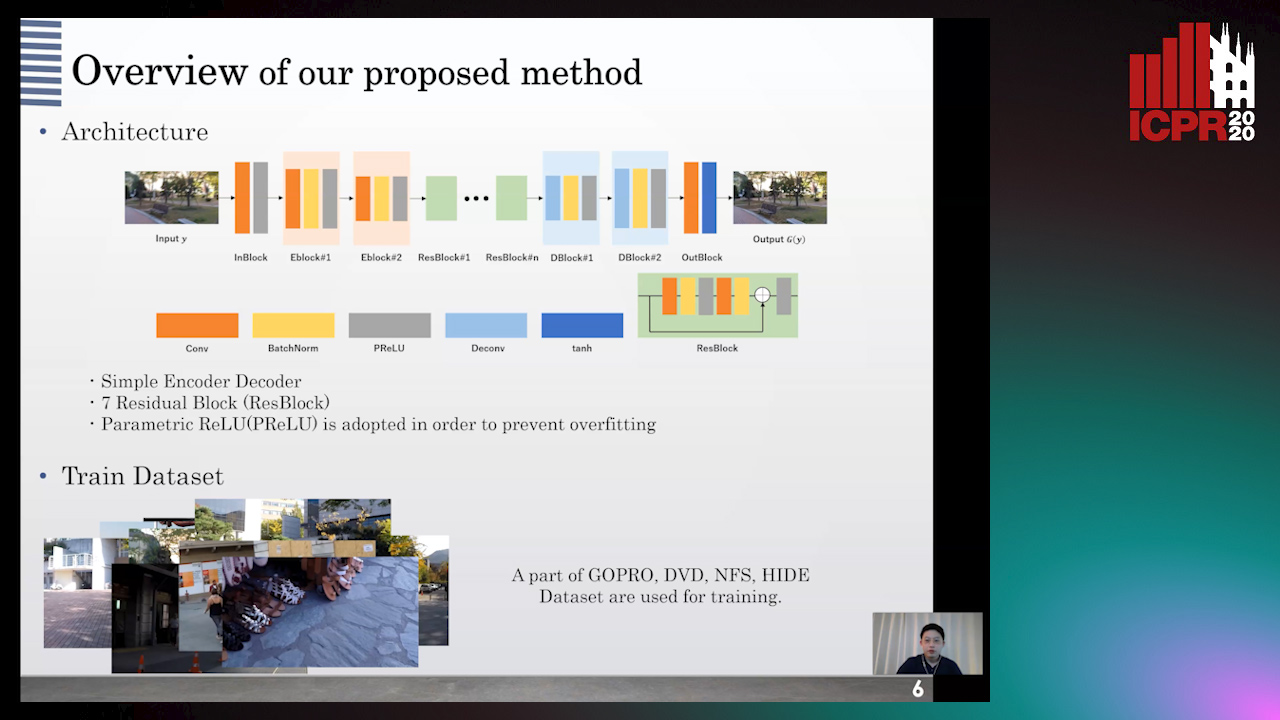
Auto-TLDR; DeblurDCTGAN: A Discrete Cosine Transform for Image Deblurring
Abstract Slides Poster Similar
Edge-Aware Monocular Dense Depth Estimation with Morphology
Zhi Li, Xiaoyang Zhu, Haitao Yu, Qi Zhang, Yongshi Jiang

Auto-TLDR; Spatio-Temporally Smooth Dense Depth Maps Using Only a CPU
Abstract Slides Poster Similar
Removing Raindrops from a Single Image Using Synthetic Data
Yoshihito Kokubo, Shusaku Asada, Hirotaka Maruyama, Masaru Koide, Kohei Yamamoto, Yoshihisa Suetsugu

Auto-TLDR; Raindrop Removal Using Synthetic Raindrop Data
Abstract Slides Poster Similar
On-Device Text Image Super Resolution
Dhruval Jain, Arun Prabhu, Gopi Ramena, Manoj Goyal, Debi Mohanty, Naresh Purre, Sukumar Moharana

Auto-TLDR; A Novel Deep Neural Network for Super-Resolution on Low Resolution Text Images
Abstract Slides Poster Similar
Deep Residual Attention Network for Hyperspectral Image Reconstruction

Auto-TLDR; Deep Convolutional Neural Network for Hyperspectral Image Reconstruction from a Snapshot
Abstract Slides Poster Similar
Tarsier: Evolving Noise Injection inSuper-Resolution GANs
Baptiste Roziere, Nathanaël Carraz Rakotonirina, Vlad Hosu, Rasoanaivo Andry, Hanhe Lin, Camille Couprie, Olivier Teytaud

Auto-TLDR; Evolutionary Super-Resolution using Diagonal CMA
Abstract Slides Poster Similar
RSAN: Residual Subtraction and Attention Network for Single Image Super-Resolution
Shuo Wei, Xin Sun, Haoran Zhao, Junyu Dong

Auto-TLDR; RSAN: Residual subtraction and attention network for super-resolution
Multi-Laplacian GAN with Edge Enhancement for Face Super Resolution

Auto-TLDR; Face Image Super-Resolution with Enhanced Edge Information
Abstract Slides Poster Similar
SECI-GAN: Semantic and Edge Completion for Dynamic Objects Removal
Francesco Pinto, Andrea Romanoni, Matteo Matteucci, Phil Torr

Auto-TLDR; SECI-GAN: Semantic and Edge Conditioned Inpainting Generative Adversarial Network
Abstract Slides Poster Similar
Automatic Semantic Segmentation of Structural Elements related to the Spinal Cord in the Lumbar Region by Using Convolutional Neural Networks
Jhon Jairo Sáenz Gamboa, Maria De La Iglesia-Vaya, Jon Ander Gómez

Auto-TLDR; Semantic Segmentation of Lumbar Spine Using Convolutional Neural Networks
Abstract Slides Poster Similar
Transfer Learning through Weighted Loss Function and Group Normalization for Vessel Segmentation from Retinal Images
Abdullah Sarhan, Jon Rokne, Reda Alhajj, Andrew Crichton

Auto-TLDR; Deep Learning for Segmentation of Blood Vessels in Retinal Images
Abstract Slides Poster Similar
Adaptive Image Compression Using GAN Based Semantic-Perceptual Residual Compensation
Ruojing Wang, Zitang Sun, Sei-Ichiro Kamata, Weili Chen

Auto-TLDR; Adaptive Image Compression using GAN based Semantic-Perceptual Residual Compensation
Abstract Slides Poster Similar
Multi-focus Image Fusion for Confocal Microscopy Using U-Net Regression Map
Md Maruf Hossain Shuvo, Yasmin M. Kassim, Filiz Bunyak, Olga V. Glinskii, Leike Xie, Vladislav V Glinsky, Virginia H. Huxley, Kannappan Palaniappan

Auto-TLDR; Independent Single Channel U-Net Fusion for Multi-focus Microscopy Images
Abstract Slides Poster Similar
Triplet-Path Dilated Network for Detection and Segmentation of General Pathological Images
Jiaqi Luo, Zhicheng Zhao, Fei Su, Limei Guo

Auto-TLDR; Triplet-path Network for One-Stage Object Detection and Segmentation in Pathological Images
Breast Anatomy Enriched Tumor Saliency Estimation
Fei Xu, Yingtao Zhang, Heng-Da Cheng, Jianrui Ding, Boyu Zhang, Chunping Ning, Ying Wang

Auto-TLDR; Tumor Saliency Estimation for Breast Ultrasound using enriched breast anatomy knowledge
Abstract Slides Poster Similar
Single Image Deblurring Using Bi-Attention Network

Auto-TLDR; Bi-Attention Neural Network for Single Image Deblurring
Improving Low-Resolution Image Classification by Super-Resolution with Enhancing High-Frequency Content
Liguo Zhou, Guang Chen, Mingyue Feng, Alois Knoll

Auto-TLDR; Super-resolution for Low-Resolution Image Classification
Abstract Slides Poster Similar
FOANet: A Focus of Attention Network with Application to Myocardium Segmentation
Zhou Zhao, Elodie Puybareau, Nicolas Boutry, Thierry Geraud

Auto-TLDR; FOANet: A Hybrid Loss Function for Myocardium Segmentation of Cardiac Magnetic Resonance Images
Abstract Slides Poster Similar