D3Net: Joint Demosaicking, Deblurring and Deringing
Tomas Kerepecky,
Filip Sroubek

Auto-TLDR; Joint demosaicking deblurring and deringing network with light-weight architecture inspired by the alternating direction method of multipliers
Similar papers
MBD-GAN: Model-Based Image Deblurring with a Generative Adversarial Network

Auto-TLDR; Model-Based Deblurring GAN for Inverse Imaging
Abstract Slides Poster Similar
Deep Iterative Residual Convolutional Network for Single Image Super-Resolution
Rao Muhammad Umer, Gian Luca Foresti, Christian Micheloni

Auto-TLDR; ISRResCNet: Deep Iterative Super-Resolution Residual Convolutional Network for Single Image Super-resolution
Video Reconstruction by Spatio-Temporal Fusion of Blurred-Coded Image Pair
Anupama S, Prasan Shedligeri, Abhishek Pal, Kaushik Mitr

Auto-TLDR; Recovering Video from Motion-Blurred and Coded Exposure Images Using Deep Learning
Abstract Slides Poster Similar
GAN-Based Image Deblurring Using DCT Discriminator
Hiroki Tomosada, Takahiro Kudo, Takanori Fujisawa, Masaaki Ikehara
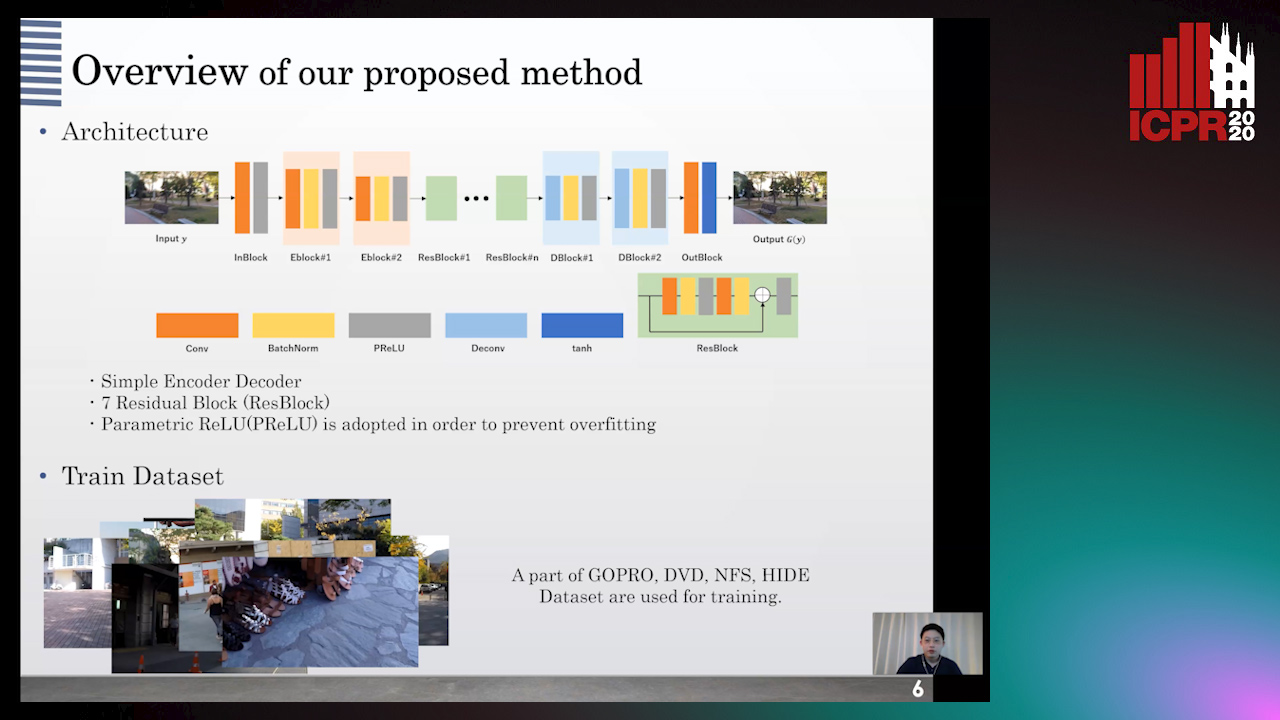
Auto-TLDR; DeblurDCTGAN: A Discrete Cosine Transform for Image Deblurring
Abstract Slides Poster Similar
Deep Universal Blind Image Denoising

Auto-TLDR; Image Denoising with Deep Convolutional Neural Networks
Edge-Guided CNN for Denoising Images from Portable Ultrasound Devices
Yingnan Ma, Fei Yang, Anup Basu

Auto-TLDR; Edge-Guided Convolutional Neural Network for Portable Ultrasound Images
Abstract Slides Poster Similar
Deep Realistic Novel View Generation for City-Scale Aerial Images
Koundinya Nouduri, Ke Gao, Joshua Fraser, Shizeng Yao, Hadi Aliakbarpour, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; End-to-End 3D Voxel Renderer for Multi-View Stereo Data Generation and Evaluation
Abstract Slides Poster Similar
Automatical Enhancement and Denoising of Extremely Low-Light Images
Yuda Song, Yunfang Zhu, Xin Du

Auto-TLDR; INSNet: Illumination and Noise Separation Network for Low-Light Image Restoring
Abstract Slides Poster Similar
Boosting High-Level Vision with Joint Compression Artifacts Reduction and Super-Resolution
Xiaoyu Xiang, Qian Lin, Jan Allebach

Auto-TLDR; A Context-Aware Joint CAR and SR Neural Network for High-Resolution Text Recognition and Face Detection
Abstract Slides Poster Similar
DSPNet: Deep Learning-Enabled Blind Reduction of Speckle Noise
Yuxu Lu, Meifang Yang, Liu Wen

Auto-TLDR; Deep Blind DeSPeckling Network for Imaging Applications
Detail-Revealing Deep Low-Dose CT Reconstruction
Xinchen Ye, Yuyao Xu, Rui Xu, Shoji Kido, Noriyuki Tomiyama

Auto-TLDR; A Dual-branch Aggregation Network for Low-Dose CT Reconstruction
Abstract Slides Poster Similar
Single Image Deblurring Using Bi-Attention Network

Auto-TLDR; Bi-Attention Neural Network for Single Image Deblurring
Hierarchically Aggregated Residual Transformation for Single Image Super Resolution

Auto-TLDR; HARTnet: Hierarchically Aggregated Residual Transformation for Multi-Scale Super-resolution
Abstract Slides Poster Similar
Deep Residual Attention Network for Hyperspectral Image Reconstruction

Auto-TLDR; Deep Convolutional Neural Network for Hyperspectral Image Reconstruction from a Snapshot
Abstract Slides Poster Similar
Ultrasound Image Restoration Using Weighted Nuclear Norm Minimization
Hanmei Yang, Ye Luo, Jianwei Lu, Jian Lu

Auto-TLDR; A Nonconvex Low-Rank Matrix Approximation Model for Ultrasound Images Restoration
A NoGAN Approach for Image and Video Restoration and Compression Artifact Removal
Mameli Filippo, Marco Bertini, Leonardo Galteri, Alberto Del Bimbo

Auto-TLDR; Deep Neural Network for Image and Video Compression Artifact Removal and Restoration
Multi-scale Processing of Noisy Images using Edge Preservation Losses

Auto-TLDR; Multi-scale U-net for Noisy Image Detection and Denoising
Abstract Slides Poster Similar
LFIEM: Lightweight Filter-Based Image Enhancement Model
Oktai Tatanov, Aleksei Samarin

Auto-TLDR; Image Retouching Using Semi-supervised Learning for Mobile Devices
Abstract Slides Poster Similar
Video Lightening with Dedicated CNN Architecture
Li-Wen Wang, Wan-Chi Siu, Zhi-Song Liu, Chu-Tak Li, P. K. Daniel Lun

Auto-TLDR; VLN: Video Lightening Network for Driving Assistant Systems in Dark Environment
Abstract Slides Poster Similar
Towards Artifacts-Free Image Defogging
Gabriele Graffieti, Davide Maltoni

Auto-TLDR; CurL-Defog: Learning Based Defogging with CycleGAN and HArD
Edge-Aware Monocular Dense Depth Estimation with Morphology
Zhi Li, Xiaoyang Zhu, Haitao Yu, Qi Zhang, Yongshi Jiang

Auto-TLDR; Spatio-Temporally Smooth Dense Depth Maps Using Only a CPU
Abstract Slides Poster Similar
Deep Fusion of RGB and NIR Paired Images Using Convolutional Neural Networks

Auto-TLDR; Deep Fusion of RGB and NIR paired images in low light condition using convolutional neural networks
Abstract Slides Poster Similar
ISP4ML: The Role of Image Signal Processing in Efficient Deep Learning Vision Systems
Patrick Hansen, Alexey Vilkin, Yury Khrustalev, James Stuart Imber, Dumidu Sanjaya Talagala, David Hanwell, Matthew Mattina, Paul Whatmough

Auto-TLDR; Towards Efficient Convolutional Neural Networks with Image Signal Processing
Abstract Slides Poster Similar
SIDGAN: Single Image Dehazing without Paired Supervision
Pan Wei, Xin Wang, Lei Wang, Ji Xiang, Zihan Wang

Auto-TLDR; DehazeGAN: An End-to-End Generative Adversarial Network for Image Dehazing
Abstract Slides Poster Similar
Near-Infrared Depth-Independent Image Dehazing using Haar Wavelets
Sumit Laha, Ankit Sharma, Shengnan Hu, Hassan Foroosh

Auto-TLDR; A fusion algorithm for haze removal using Haar wavelets
Abstract Slides Poster Similar
Removing Raindrops from a Single Image Using Synthetic Data
Yoshihito Kokubo, Shusaku Asada, Hirotaka Maruyama, Masaru Koide, Kohei Yamamoto, Yoshihisa Suetsugu

Auto-TLDR; Raindrop Removal Using Synthetic Raindrop Data
Abstract Slides Poster Similar
On-Device Text Image Super Resolution
Dhruval Jain, Arun Prabhu, Gopi Ramena, Manoj Goyal, Debi Mohanty, Naresh Purre, Sukumar Moharana

Auto-TLDR; A Novel Deep Neural Network for Super-Resolution on Low Resolution Text Images
Abstract Slides Poster Similar
Multi-Laplacian GAN with Edge Enhancement for Face Super Resolution

Auto-TLDR; Face Image Super-Resolution with Enhanced Edge Information
Abstract Slides Poster Similar
A GAN-Based Blind Inpainting Method for Masonry Wall Images
Yahya Ibrahim, Balázs Nagy, Csaba Benedek

Auto-TLDR; An End-to-End Blind Inpainting Algorithm for Masonry Wall Images
Abstract Slides Poster Similar
RSAN: Residual Subtraction and Attention Network for Single Image Super-Resolution
Shuo Wei, Xin Sun, Haoran Zhao, Junyu Dong

Auto-TLDR; RSAN: Residual subtraction and attention network for super-resolution
Improving Gravitational Wave Detection with 2D Convolutional Neural Networks
Siyu Fan, Yisen Wang, Yuan Luo, Alexander Michael Schmitt, Shenghua Yu

Auto-TLDR; Two-dimensional Convolutional Neural Networks for Gravitational Wave Detection from Time Series with Background Noise
Residual Fractal Network for Single Image Super Resolution by Widening and Deepening
Jiahang Gu, Zhaowei Qu, Xiaoru Wang, Jiawang Dan, Junwei Sun

Auto-TLDR; Residual fractal convolutional network for single image super-resolution
Abstract Slides Poster Similar
Multi-focus Image Fusion for Confocal Microscopy Using U-Net Regression Map
Md Maruf Hossain Shuvo, Yasmin M. Kassim, Filiz Bunyak, Olga V. Glinskii, Leike Xie, Vladislav V Glinsky, Virginia H. Huxley, Kannappan Palaniappan

Auto-TLDR; Independent Single Channel U-Net Fusion for Multi-focus Microscopy Images
Abstract Slides Poster Similar
DCT/IDCT Filter Design for Ultrasound Image Filtering
Barmak Honarvar Shakibaei Asli, Jan Flusser, Yifan Zhao, John Ahmet Erkoyuncu, Rajkumar Roy

Auto-TLDR; Finite impulse response digital filter using DCT-II and inverse DCT
Abstract Slides Poster Similar
Improving Low-Resolution Image Classification by Super-Resolution with Enhancing High-Frequency Content
Liguo Zhou, Guang Chen, Mingyue Feng, Alois Knoll

Auto-TLDR; Super-resolution for Low-Resolution Image Classification
Abstract Slides Poster Similar
DR2S: Deep Regression with Region Selection for Camera Quality Evaluation
Marcelin Tworski, Stéphane Lathuiliere, Salim Belkarfa, Attilio Fiandrotti, Marco Cagnazzo

Auto-TLDR; Texture Quality Estimation Using Deep Learning
Abstract Slides Poster Similar
Cost Volume Refinement for Depth Prediction
João L. Cardoso, Nuno Goncalves, Michael Wimmer

Auto-TLDR; Refining the Cost Volume for Depth Prediction from Light Field Cameras
Abstract Slides Poster Similar
LiNet: A Lightweight Network for Image Super Resolution
Armin Mehri, Parichehr Behjati Ardakani, Angel D. Sappa

Auto-TLDR; LiNet: A Compact Dense Network for Lightweight Super Resolution
Abstract Slides Poster Similar
Phase Retrieval Using Conditional Generative Adversarial Networks
Tobias Uelwer, Alexander Oberstraß, Stefan Harmeling

Auto-TLDR; Conditional Generative Adversarial Networks for Phase Retrieval
Abstract Slides Poster Similar
Snapshot Hyperspectral Imaging Based on Weighted High-Order Singular Value Regularization
Hua Huang, Cheng Niankai, Lizhi Wang

Auto-TLDR; High-Order Tensor Optimization for Hyperspectral Imaging
Abstract Slides Poster Similar
Progressive Splitting and Upscaling Structure for Super-Resolution

Auto-TLDR; PSUS: Progressive and Upscaling Layer for Single Image Super-Resolution
Abstract Slides Poster Similar
Learning Defects in Old Movies from Manually Assisted Restoration
Arthur Renaudeau, Travis Seng, Axel Carlier, Jean-Denis Durou, Fabien Pierre, Francois Lauze, Jean-François Aujol

Auto-TLDR; U-Net: Detecting Defects in Old Movies by Inpainting Techniques
Abstract Slides Poster Similar
5D Light Field Synthesis from a Monocular Video
Kyuho Bae, Andre Ivan, Hajime Nagahara, In Kyu Park

Auto-TLDR; Synthesis of Light Field Video from Monocular Video using Deep Learning
Adaptive Image Compression Using GAN Based Semantic-Perceptual Residual Compensation
Ruojing Wang, Zitang Sun, Sei-Ichiro Kamata, Weili Chen

Auto-TLDR; Adaptive Image Compression using GAN based Semantic-Perceptual Residual Compensation
Abstract Slides Poster Similar
Thermal Image Enhancement Using Generative Adversarial Network for Pedestrian Detection
Mohamed Amine Marnissi, Hajer Fradi, Anis Sahbani, Najoua Essoukri Ben Amara

Auto-TLDR; Improving Visual Quality of Infrared Images for Pedestrian Detection Using Generative Adversarial Network
Abstract Slides Poster Similar
Single Image Super-Resolution with Dynamic Residual Connection
Karam Park, Jae Woong Soh, Nam Ik Cho

Auto-TLDR; Dynamic Residual Attention Network for Lightweight Single Image Super-Residual Networks
Abstract Slides Poster Similar
Fidelity-Controllable Extreme Image Compression with Generative Adversarial Networks
Shoma Iwai, Tomo Miyazaki, Yoshihiro Sugaya, Shinichiro Omachi

Auto-TLDR; GAN-based Image Compression at Low Bitrates
CURL: Neural Curve Layers for Global Image Enhancement
Sean Moran, Steven Mcdonagh, Greg Slabaugh

Auto-TLDR; CURL: Neural CURve Layers for Image Enhancement
Abstract Slides Poster Similar