Cost Volume Refinement for Depth Prediction
João L. Cardoso,
Nuno Goncalves,
Michael Wimmer

Auto-TLDR; Refining the Cost Volume for Depth Prediction from Light Field Cameras
Similar papers
Fast and Efficient Neural Network for Light Field Disparity Estimation

Auto-TLDR; Improving Efficient Light Field Disparity Estimation Using Deep Neural Networks
Abstract Slides Poster Similar
P2D: A Self-Supervised Method for Depth Estimation from Polarimetry
Marc Blanchon, Desire Sidibe, Olivier Morel, Ralph Seulin, Daniel Braun, Fabrice Meriaudeau

Auto-TLDR; Polarimetric Regularization for Monocular Depth Estimation
Abstract Slides Poster Similar
Extending Single Beam Lidar to Full Resolution by Fusing with Single Image Depth Estimation
Yawen Lu, Yuxing Wang, Devarth Parikh, Guoyu Lu

Auto-TLDR; Self-supervised LIDAR for Low-Cost Depth Estimation
5D Light Field Synthesis from a Monocular Video
Kyuho Bae, Andre Ivan, Hajime Nagahara, In Kyu Park

Auto-TLDR; Synthesis of Light Field Video from Monocular Video using Deep Learning
Edge-Aware Monocular Dense Depth Estimation with Morphology
Zhi Li, Xiaoyang Zhu, Haitao Yu, Qi Zhang, Yongshi Jiang

Auto-TLDR; Spatio-Temporally Smooth Dense Depth Maps Using Only a CPU
Abstract Slides Poster Similar
NetCalib: A Novel Approach for LiDAR-Camera Auto-Calibration Based on Deep Learning
Shan Wu, Amnir Hadachi, Damien Vivet, Yadu Prabhakar

Auto-TLDR; Automatic Calibration of LiDAR and Cameras using Deep Neural Network
Abstract Slides Poster Similar
FC-DCNN: A Densely Connected Neural Network for Stereo Estimation
Dominik Hirner, Friedrich Fraundorfer

Auto-TLDR; FC-DCNN: A Lightweight Network for Stereo Estimation
Abstract Slides Poster Similar
Facetwise Mesh Refinement for Multi-View Stereo
Andrea Romanoni, Matteo Matteucci

Auto-TLDR; Facetwise Refinement of Multi-View Stereo using Delaunay Triangulations
Learning Non-Rigid Surface Reconstruction from Spatio-Temporal Image Patches
Matteo Pedone, Abdelrahman Mostafa, Janne Heikkilä

Auto-TLDR; Dense Spatio-Temporal Depth Maps of Deformable Objects from Video Sequences
Abstract Slides Poster Similar
Movement-Induced Priors for Deep Stereo
Yuxin Hou, Muhammad Kamran Janjua, Juho Kannala, Arno Solin

Auto-TLDR; Fusing Stereo Disparity Estimation with Movement-induced Prior Information
Abstract Slides Poster Similar
Two-Stage Adaptive Object Scene Flow Using Hybrid CNN-CRF Model
Congcong Li, Haoyu Ma, Qingmin Liao

Auto-TLDR; Adaptive object scene flow estimation using a hybrid CNN-CRF model and adaptive iteration
Abstract Slides Poster Similar
Real-Time Monocular Depth Estimation with Extremely Light-Weight Neural Network
Mian Jhong Chiu, Wei-Chen Chiu, Hua-Tsung Chen, Jen-Hui Chuang

Auto-TLDR; Real-Time Light-Weight Depth Prediction for Obstacle Avoidance and Environment Sensing with Deep Learning-based CNN
Abstract Slides Poster Similar
Light3DPose: Real-Time Multi-Person 3D Pose Estimation from Multiple Views
Alessio Elmi, Davide Mazzini, Pietro Tortella

Auto-TLDR; 3D Pose Estimation of Multiple People from a Few calibrated Camera Views using Deep Learning
Abstract Slides Poster Similar
A Novel Deep-Learning Pipeline for Light Field Image Based Material Recognition
Yunlong Wang, Kunbo Zhang, Zhenan Sun

Auto-TLDR; Factorize-Connect-Merge Deep Learning Pipeline for Light Field Image Based Material Recognition
Dynamic Guided Network for Monocular Depth Estimation
Xiaoxia Xing, Yinghao Cai, Yiping Yang, Dayong Wen

Auto-TLDR; DGNet: Dynamic Guidance Upsampling for Self-attention-Decoding for Monocular Depth Estimation
Abstract Slides Poster Similar
Hybrid Approach for 3D Head Reconstruction: Using Neural Networks and Visual Geometry
Oussema Bouafif, Bogdan Khomutenko, Mohammed Daoudi

Auto-TLDR; Recovering 3D Head Geometry from a Single Image using Deep Learning and Geometric Techniques
Abstract Slides Poster Similar
RefiNet: 3D Human Pose Refinement with Depth Maps
Andrea D'Eusanio, Stefano Pini, Guido Borghi, Roberto Vezzani, Rita Cucchiara

Auto-TLDR; RefiNet: A Multi-stage Framework for 3D Human Pose Estimation
Multi-Scale Residual Pyramid Attention Network for Monocular Depth Estimation
Jing Liu, Xiaona Zhang, Zhaoxin Li, Tianlu Mao

Auto-TLDR; Multi-scale Residual Pyramid Attention Network for Monocular Depth Estimation
Abstract Slides Poster Similar
RISEdb: A Novel Indoor Localization Dataset
Carlos Sanchez Belenguer, Erik Wolfart, Álvaro Casado Coscollá, Vitor Sequeira

Auto-TLDR; Indoor Localization Using LiDAR SLAM and Smartphones: A Benchmarking Dataset
Abstract Slides Poster Similar
Self-Supervised Detection and Pose Estimation of Logistical Objects in 3D Sensor Data
Nikolas Müller, Jonas Stenzel, Jian-Jia Chen

Auto-TLDR; A self-supervised and fully automated deep learning approach for object pose estimation using simulated 3D data
Abstract Slides Poster Similar
Delivering Meaningful Representation for Monocular Depth Estimation
Doyeon Kim, Donggyu Joo, Junmo Kim

Auto-TLDR; Monocular Depth Estimation by Bridging the Context between Encoding and Decoding
Abstract Slides Poster Similar
Extended Depth of Field Preserving Color Fidelity for Automated Digital Cytology
Alexandre Bouyssoux, Riadh Fezzani, Jean-Christophe Olivo-Marin
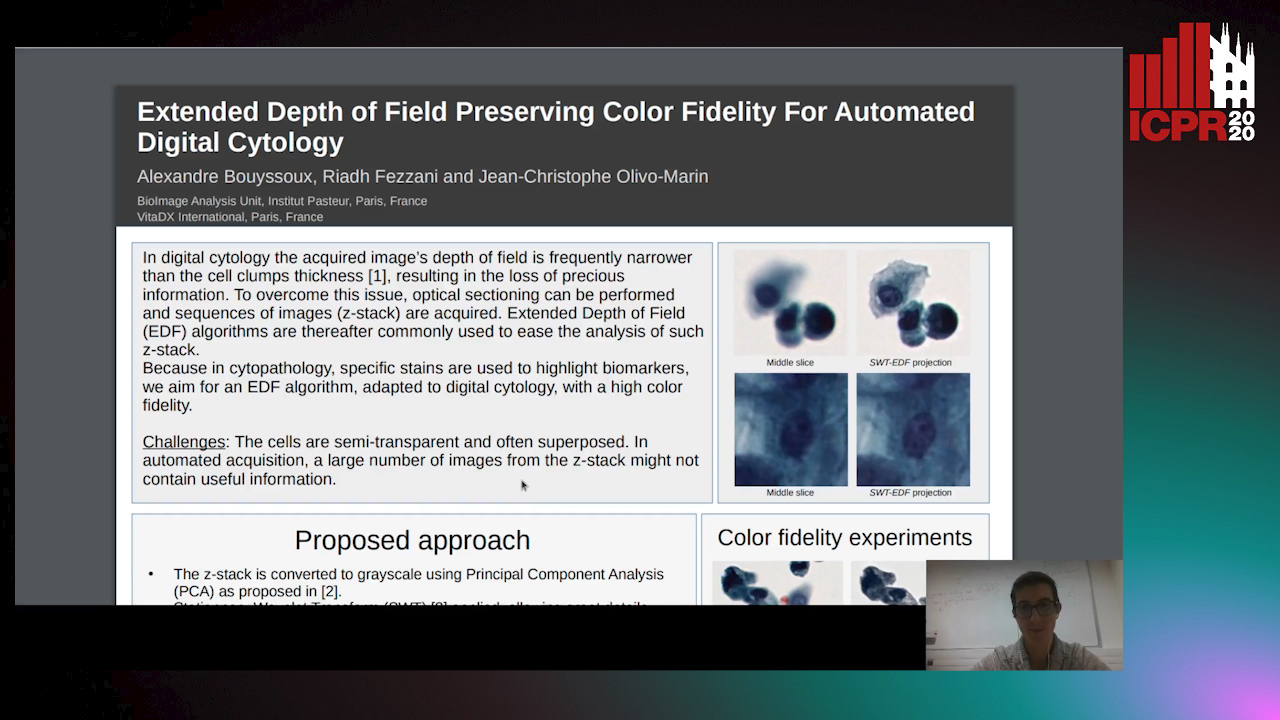
Auto-TLDR; Multi-Channel Extended Depth of Field for Digital cytology based on the stationary wavelet transform
Calibration and Absolute Pose Estimation of Trinocular Linear Camera Array for Smart City Applications
Martin Ahrnbom, Mikael Nilsson, Håkan Ardö, Kalle Åström, Oksana Yastremska-Kravchenko, Aliaksei Laureshyn

Auto-TLDR; Trinocular Linear Camera Array Calibration for Traffic Surveillance Applications
Abstract Slides Poster Similar
Polarimetric Image Augmentation
Marc Blanchon, Fabrice Meriaudeau, Olivier Morel, Ralph Seulin, Desire Sidibe

Auto-TLDR; Polarimetric Augmentation for Deep Learning in Robotics Applications
Leveraging a Weakly Adversarial Paradigm for Joint Learning of Disparity and Confidence Estimation
Matteo Poggi, Fabio Tosi, Filippo Aleotti, Stefano Mattoccia

Auto-TLDR; Joint Training of Deep-Networks for Outlier Detection from Stereo Images
Abstract Slides Poster Similar
Deep Realistic Novel View Generation for City-Scale Aerial Images
Koundinya Nouduri, Ke Gao, Joshua Fraser, Shizeng Yao, Hadi Aliakbarpour, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; End-to-End 3D Voxel Renderer for Multi-View Stereo Data Generation and Evaluation
Abstract Slides Poster Similar
Partially Supervised Multi-Task Network for Single-View Dietary Assessment
Ya Lu, Thomai Stathopoulou, Stavroula Mougiakakou

Auto-TLDR; Food Volume Estimation from a Single Food Image via Geometric Understanding and Semantic Prediction
Abstract Slides Poster Similar
Generic Merging of Structure from Motion Maps with a Low Memory Footprint
Gabrielle Flood, David Gillsjö, Patrik Persson, Anders Heyden, Kalle Åström

Auto-TLDR; A Low-Memory Footprint Representation for Robust Map Merge
Abstract Slides Poster Similar
Weight Estimation from an RGB-D Camera in Top-View Configuration
Marco Mameli, Marina Paolanti, Nicola Conci, Filippo Tessaro, Emanuele Frontoni, Primo Zingaretti

Auto-TLDR; Top-View Weight Estimation using Deep Neural Networks
Abstract Slides Poster Similar
Learning Stereo Matchability in Disparity Regression Networks
Jingyang Zhang, Yao Yao, Zixin Luo, Shiwei Li, Tianwei Shen, Tian Fang, Long Quan

Auto-TLDR; Deep Stereo Matchability for Weakly Matchable Regions
Deep Homography-Based Video Stabilization
Maria Silvia Ito, Ebroul Izquierdo

Auto-TLDR; Video Stabilization using Deep Learning and Spatial Transformer Networks
Abstract Slides Poster Similar
Deeply-Fused Attentive Network for Stereo Matching
Zuliu Yang, Xindong Ai, Weida Yang, Yong Zhao, Qifei Dai, Fuchi Li

Auto-TLDR; DF-Net: Deep Learning-based Network for Stereo Matching
Abstract Slides Poster Similar
Benchmarking Cameras for OpenVSLAM Indoors
Kevin Chappellet, Guillaume Caron, Fumio Kanehiro, Ken Sakurada, Abderrahmane Kheddar

Auto-TLDR; OpenVSLAM: Benchmarking Camera Types for Visual Simultaneous Localization and Mapping
Abstract Slides Poster Similar
Enhancing Depth Quality of Stereo Vision Using Deep Learning-Based Prior Information of the Driving Environment
Weifu Li, Vijay John, Seiichi Mita

Auto-TLDR; A Novel Post-processing Mathematical Framework for Stereo Vision
Abstract Slides Poster Similar
Near-Infrared Depth-Independent Image Dehazing using Haar Wavelets
Sumit Laha, Ankit Sharma, Shengnan Hu, Hassan Foroosh

Auto-TLDR; A fusion algorithm for haze removal using Haar wavelets
Abstract Slides Poster Similar
Object Segmentation Tracking from Generic Video Cues
Amirhossein Kardoost, Sabine Müller, Joachim Weickert, Margret Keuper

Auto-TLDR; A Light-Weight Variational Framework for Video Object Segmentation in Videos
Abstract Slides Poster Similar
IPT: A Dataset for Identity Preserved Tracking in Closed Domains
Thomas Heitzinger, Martin Kampel

Auto-TLDR; Identity Preserved Tracking Using Depth Data for Privacy and Privacy
Abstract Slides Poster Similar
PROPEL: Probabilistic Parametric Regression Loss for Convolutional Neural Networks
Muhammad Asad, Rilwan Basaru, S M Masudur Rahman Al Arif, Greg Slabaugh

Auto-TLDR; PRObabilistic Parametric rEgression Loss for Probabilistic Regression Using Convolutional Neural Networks
DEN: Disentangling and Exchanging Network for Depth Completion
You-Feng Wu, Vu-Hoang Tran, Ting-Wei Chang, Wei-Chen Chiu, Ching-Chun Huang

Auto-TLDR; Disentangling and Exchanging Network for Depth Completion
Better Prior Knowledge Improves Human-Pose-Based Extrinsic Camera Calibration
Olivier Moliner, Sangxia Huang, Kalle Åström

Auto-TLDR; Improving Human-pose-based Extrinsic Calibration for Multi-Camera Systems
Abstract Slides Poster Similar
Removing Raindrops from a Single Image Using Synthetic Data
Yoshihito Kokubo, Shusaku Asada, Hirotaka Maruyama, Masaru Koide, Kohei Yamamoto, Yoshihisa Suetsugu

Auto-TLDR; Raindrop Removal Using Synthetic Raindrop Data
Abstract Slides Poster Similar
Derivation of Geometrically and Semantically Annotated UAV Datasets at Large Scales from 3D City Models
Sidi Wu, Lukas Liebel, Marco Körner

Auto-TLDR; Large-Scale Dataset of Synthetic UAV Imagery for Geometric and Semantic Annotation
Abstract Slides Poster Similar
User-Independent Gaze Estimation by Extracting Pupil Parameter and Its Mapping to the Gaze Angle

Auto-TLDR; Gaze Point Estimation using Pupil Shape for Generalization
Abstract Slides Poster Similar
Ordinal Depth Classification Using Region-Based Self-Attention
Minh Hieu Phan, Son Lam Phung, Abdesselam Bouzerdoum

Auto-TLDR; Region-based Self-Attention for Multi-scale Depth Estimation from a Single 2D Image
Abstract Slides Poster Similar
Recovery of 2D and 3D Layout Information through an Advanced Image Stitching Algorithm Using Scanning Electron Microscope Images
Aayush Singla, Bernhard Lippmann, Helmut Graeb

Auto-TLDR; Image Stitching for True Geometrical Layout Recovery in Nanoscale Dimension
Abstract Slides Poster Similar
Learning to Find Good Correspondences of Multiple Objects
Youye Xie, Yingheng Tang, Gongguo Tang, William Hoff

Auto-TLDR; Multi-Object Inliers and Outliers for Perspective-n-Point and Object Recognition
Abstract Slides Poster Similar
One Step Clustering Based on A-Contrario Framework for Detection of Alterations in Historical Violins
Alireza Rezaei, Sylvie Le Hégarat-Mascle, Emanuel Aldea, Piercarlo Dondi, Marco Malagodi

Auto-TLDR; A-Contrario Clustering for the Detection of Altered Violins using UVIFL Images
Abstract Slides Poster Similar
Towards Artifacts-Free Image Defogging
Gabriele Graffieti, Davide Maltoni

Auto-TLDR; CurL-Defog: Learning Based Defogging with CycleGAN and HArD