Deep Homography-Based Video Stabilization
Maria Silvia Ito,
Ebroul Izquierdo

Auto-TLDR; Video Stabilization using Deep Learning and Spatial Transformer Networks
Similar papers
Edge-Aware Monocular Dense Depth Estimation with Morphology
Zhi Li, Xiaoyang Zhu, Haitao Yu, Qi Zhang, Yongshi Jiang

Auto-TLDR; Spatio-Temporally Smooth Dense Depth Maps Using Only a CPU
Abstract Slides Poster Similar
OmniFlowNet: A Perspective Neural Network Adaptation for Optical Flow Estimation in Omnidirectional Images
Charles-Olivier Artizzu, Haozhou Zhang, Guillaume Allibert, Cédric Demonceaux

Auto-TLDR; OmniFlowNet: A Convolutional Neural Network for Omnidirectional Optical Flow Estimation
Abstract Slides Poster Similar
DR2S: Deep Regression with Region Selection for Camera Quality Evaluation
Marcelin Tworski, Stéphane Lathuiliere, Salim Belkarfa, Attilio Fiandrotti, Marco Cagnazzo

Auto-TLDR; Texture Quality Estimation Using Deep Learning
Abstract Slides Poster Similar
Mobile Augmented Reality: Fast, Precise, and Smooth Planar Object Tracking
Dmitrii Matveichev, Daw-Tung Lin

Auto-TLDR; Planar Object Tracking with Sparse Optical Flow Tracking and Descriptor Matching
Abstract Slides Poster Similar
A NoGAN Approach for Image and Video Restoration and Compression Artifact Removal
Mameli Filippo, Marco Bertini, Leonardo Galteri, Alberto Del Bimbo

Auto-TLDR; Deep Neural Network for Image and Video Compression Artifact Removal and Restoration
Residual Learning of Video Frame Interpolation Using Convolutional LSTM

Auto-TLDR; Video Frame Interpolation Using Residual Learning and Convolutional LSTMs
Abstract Slides Poster Similar
Movement-Induced Priors for Deep Stereo
Yuxin Hou, Muhammad Kamran Janjua, Juho Kannala, Arno Solin

Auto-TLDR; Fusing Stereo Disparity Estimation with Movement-induced Prior Information
Abstract Slides Poster Similar
Future Urban Scenes Generation through Vehicles Synthesis
Alessandro Simoni, Luca Bergamini, Andrea Palazzi, Simone Calderara, Rita Cucchiara

Auto-TLDR; Predicting the Future of an Urban Scene with a Novel View Synthesis Paradigm
Abstract Slides Poster Similar
Learning Non-Rigid Surface Reconstruction from Spatio-Temporal Image Patches
Matteo Pedone, Abdelrahman Mostafa, Janne Heikkilä

Auto-TLDR; Dense Spatio-Temporal Depth Maps of Deformable Objects from Video Sequences
Abstract Slides Poster Similar
Revisiting Optical Flow Estimation in 360 Videos
Keshav Bhandari, Ziliang Zong, Yan Yan
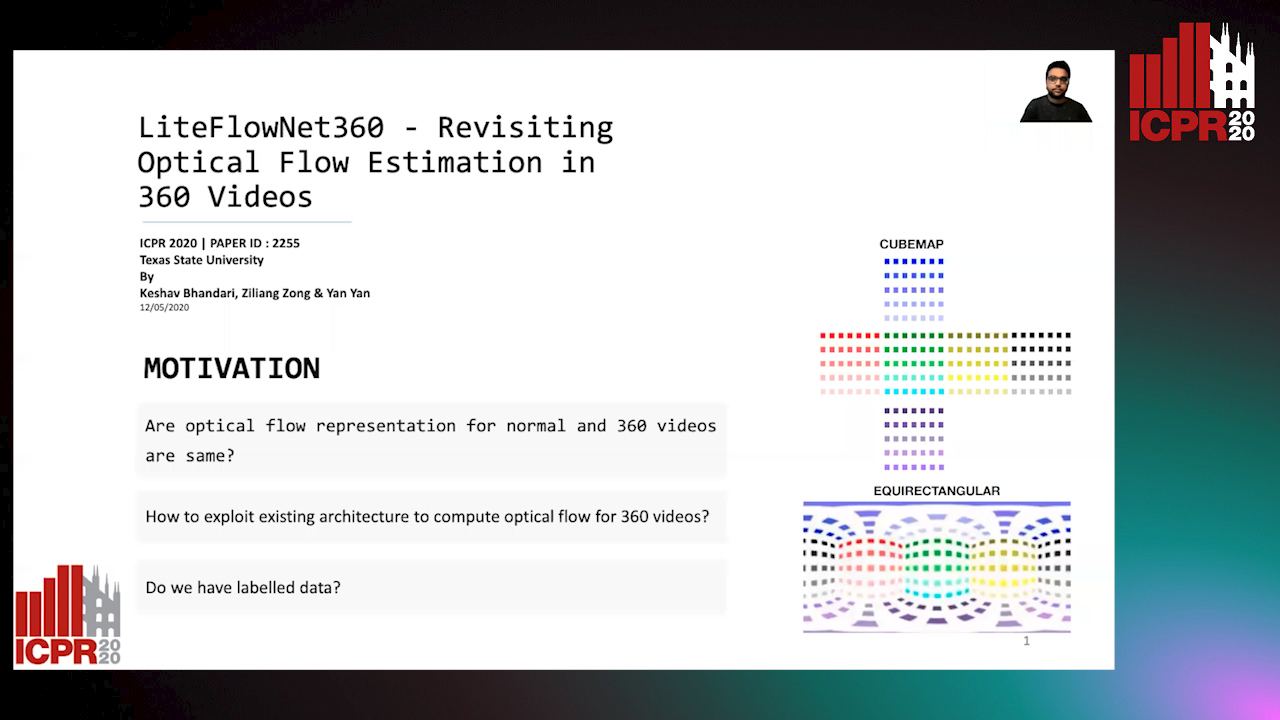
Auto-TLDR; LiteFlowNet360: A Domain Adaptation Framework for 360 Video Optical Flow Estimation
Learning Knowledge-Rich Sequential Model for Planar Homography Estimation in Aerial Video

Auto-TLDR; Sequential Estimation of Planar Homographic Transformations over Aerial Videos
Abstract Slides Poster Similar
ID Documents Matching and Localization with Multi-Hypothesis Constraints
Guillaume Chiron, Nabil Ghanmi, Ahmad Montaser Awal

Auto-TLDR; Identity Document Localization in the Wild Using Multi-hypothesis Exploration
Abstract Slides Poster Similar
Two-Stage Adaptive Object Scene Flow Using Hybrid CNN-CRF Model
Congcong Li, Haoyu Ma, Qingmin Liao

Auto-TLDR; Adaptive object scene flow estimation using a hybrid CNN-CRF model and adaptive iteration
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
VTT: Long-Term Visual Tracking with Transformers
Tianling Bian, Yang Hua, Tao Song, Zhengui Xue, Ruhui Ma, Neil Robertson, Haibing Guan

Auto-TLDR; Visual Tracking Transformer with transformers for long-term visual tracking
Extending Single Beam Lidar to Full Resolution by Fusing with Single Image Depth Estimation
Yawen Lu, Yuxing Wang, Devarth Parikh, Guoyu Lu

Auto-TLDR; Self-supervised LIDAR for Low-Cost Depth Estimation
MBD-GAN: Model-Based Image Deblurring with a Generative Adversarial Network

Auto-TLDR; Model-Based Deblurring GAN for Inverse Imaging
Abstract Slides Poster Similar
P2D: A Self-Supervised Method for Depth Estimation from Polarimetry
Marc Blanchon, Desire Sidibe, Olivier Morel, Ralph Seulin, Daniel Braun, Fabrice Meriaudeau

Auto-TLDR; Polarimetric Regularization for Monocular Depth Estimation
Abstract Slides Poster Similar
Video Lightening with Dedicated CNN Architecture
Li-Wen Wang, Wan-Chi Siu, Zhi-Song Liu, Chu-Tak Li, P. K. Daniel Lun

Auto-TLDR; VLN: Video Lightening Network for Driving Assistant Systems in Dark Environment
Abstract Slides Poster Similar
5D Light Field Synthesis from a Monocular Video
Kyuho Bae, Andre Ivan, Hajime Nagahara, In Kyu Park

Auto-TLDR; Synthesis of Light Field Video from Monocular Video using Deep Learning
Cost Volume Refinement for Depth Prediction
João L. Cardoso, Nuno Goncalves, Michael Wimmer

Auto-TLDR; Refining the Cost Volume for Depth Prediction from Light Field Cameras
Abstract Slides Poster Similar
Deep Realistic Novel View Generation for City-Scale Aerial Images
Koundinya Nouduri, Ke Gao, Joshua Fraser, Shizeng Yao, Hadi Aliakbarpour, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; End-to-End 3D Voxel Renderer for Multi-View Stereo Data Generation and Evaluation
Abstract Slides Poster Similar
Relevance Detection in Cataract Surgery Videos by Spatio-Temporal Action Localization
Negin Ghamsarian, Mario Taschwer, Doris Putzgruber, Stephanie. Sarny, Klaus Schoeffmann

Auto-TLDR; relevance-based retrieval in cataract surgery videos
Exploring Severe Occlusion: Multi-Person 3D Pose Estimation with Gated Convolution
Renshu Gu, Gaoang Wang, Jenq-Neng Hwang

Auto-TLDR; 3D Human Pose Estimation for Multi-Human Videos with Occlusion
Towards Artifacts-Free Image Defogging
Gabriele Graffieti, Davide Maltoni

Auto-TLDR; CurL-Defog: Learning Based Defogging with CycleGAN and HArD
TinyVIRAT: Low-Resolution Video Action Recognition
Ugur Demir, Yogesh Rawat, Mubarak Shah

Auto-TLDR; TinyVIRAT: A Progressive Generative Approach for Action Recognition in Videos
Abstract Slides Poster Similar
Better Prior Knowledge Improves Human-Pose-Based Extrinsic Camera Calibration
Olivier Moliner, Sangxia Huang, Kalle Åström

Auto-TLDR; Improving Human-pose-based Extrinsic Calibration for Multi-Camera Systems
Abstract Slides Poster Similar
Computational Data Analysis for First Quantization Estimation on JPEG Double Compressed Images
Sebastiano Battiato, Oliver Giudice, Francesco Guarnera, Giovanni Puglisi

Auto-TLDR; Exploiting Discrete Cosine Transform Coefficients for Multimedia Forensics
Abstract Slides Poster Similar
Visual Saliency Oriented Vehicle Scale Estimation
Qixin Chen, Tie Liu, Jiali Ding, Zejian Yuan, Yuanyuan Shang

Auto-TLDR; Regularized Intensity Matching for Vehicle Scale Estimation with salient object detection
Abstract Slides Poster Similar
Thermal Image Enhancement Using Generative Adversarial Network for Pedestrian Detection
Mohamed Amine Marnissi, Hajer Fradi, Anis Sahbani, Najoua Essoukri Ben Amara

Auto-TLDR; Improving Visual Quality of Infrared Images for Pedestrian Detection Using Generative Adversarial Network
Abstract Slides Poster Similar
Understanding When Spatial Transformer Networks Do Not Support Invariance, and What to Do about It
Lukas Finnveden, Ylva Jansson, Tony Lindeberg

Auto-TLDR; Spatial Transformer Networks are unable to support invariance when transforming CNN feature maps
Abstract Slides Poster Similar
Boundary Guided Image Translation for Pose Estimation from Ultra-Low Resolution Thermal Sensor
Kohei Kurihara, Tianren Wang, Teng Zhang, Brian Carrington Lovell

Auto-TLDR; Pose Estimation on Low-Resolution Thermal Images Using Image-to-Image Translation Architecture
Abstract Slides Poster Similar
High Resolution Face Age Editing
Xu Yao, Gilles Puy, Alasdair Newson, Yann Gousseau, Pierre Hellier

Auto-TLDR; An Encoder-Decoder Architecture for Face Age editing on High Resolution Images
Abstract Slides Poster Similar
AerialMPTNet: Multi-Pedestrian Tracking in Aerial Imagery Using Temporal and Graphical Features
Maximilian Kraus, Seyed Majid Azimi, Emec Ercelik, Reza Bahmanyar, Peter Reinartz, Alois Knoll

Auto-TLDR; AerialMPTNet: A novel approach for multi-pedestrian tracking in geo-referenced aerial imagery by fusing appearance features
Abstract Slides Poster Similar
GAN-Based Image Deblurring Using DCT Discriminator
Hiroki Tomosada, Takahiro Kudo, Takanori Fujisawa, Masaaki Ikehara
Auto-TLDR; DeblurDCTGAN: A Discrete Cosine Transform for Image Deblurring
Abstract Slides Poster Similar
Video Face Manipulation Detection through Ensemble of CNNs
Nicolo Bonettini, Edoardo Daniele Cannas, Sara Mandelli, Luca Bondi, Paolo Bestagini, Stefano Tubaro

Auto-TLDR; Face Manipulation Detection in Video Sequences Using Convolutional Neural Networks
Learning to Take Directions One Step at a Time
Qiyang Hu, Adrian Wälchli, Tiziano Portenier, Matthias Zwicker, Paolo Favaro

Auto-TLDR; Generating a Sequence of Motion Strokes from a Single Image
Abstract Slides Poster Similar
How Important Are Faces for Person Re-Identification?
Julia Dietlmeier, Joseph Antony, Kevin Mcguinness, Noel E O'Connor

Auto-TLDR; Anonymization of Person Re-identification Datasets with Face Detection and Blurring
Abstract Slides Poster Similar
Benchmarking Cameras for OpenVSLAM Indoors
Kevin Chappellet, Guillaume Caron, Fumio Kanehiro, Ken Sakurada, Abderrahmane Kheddar

Auto-TLDR; OpenVSLAM: Benchmarking Camera Types for Visual Simultaneous Localization and Mapping
Abstract Slides Poster Similar
Video Reconstruction by Spatio-Temporal Fusion of Blurred-Coded Image Pair
Anupama S, Prasan Shedligeri, Abhishek Pal, Kaushik Mitr

Auto-TLDR; Recovering Video from Motion-Blurred and Coded Exposure Images Using Deep Learning
Abstract Slides Poster Similar
Adaptive Estimation of Optimal Color Transformations for Deep Convolutional Network Based Homography Estimation
Miguel A. Molina-Cabello, Jorge García-González, Rafael Marcos Luque-Baena, Karl Thurnhofer-Hemsi, Ezequiel López-Rubio

Auto-TLDR; Improving Homography Estimation from a Pair of Natural Images Using Deep Convolutional Neural Networks
Abstract Slides Poster Similar
Wavelet Attention Embedding Networks for Video Super-Resolution
Young-Ju Choi, Young-Woon Lee, Byung-Gyu Kim

Auto-TLDR; Wavelet Attention Embedding Network for Video Super-Resolution
Abstract Slides Poster Similar
STaRFlow: A SpatioTemporal Recurrent Cell for Lightweight Multi-Frame Optical Flow Estimation
Pierre Godet, Alexandre Boulch, Aurélien Plyer, Guy Le Besnerais

Auto-TLDR; STaRFlow: A lightweight CNN-based algorithm for optical flow estimation
Abstract Slides Poster Similar
Transformer Networks for Trajectory Forecasting
Francesco Giuliari, Hasan Irtiza, Marco Cristani, Fabio Galasso

Auto-TLDR; TransformerNetworks for Trajectory Prediction of People Interactions
Abstract Slides Poster Similar
Boosting High-Level Vision with Joint Compression Artifacts Reduction and Super-Resolution
Xiaoyu Xiang, Qian Lin, Jan Allebach

Auto-TLDR; A Context-Aware Joint CAR and SR Neural Network for High-Resolution Text Recognition and Face Detection
Abstract Slides Poster Similar
Anomaly Detection, Localization and Classification for Railway Inspection
Riccardo Gasparini, Andrea D'Eusanio, Guido Borghi, Stefano Pini, Giuseppe Scaglione, Simone Calderara, Eugenio Fedeli, Rita Cucchiara

Auto-TLDR; Anomaly Detection and Localization using thermal images in the lowlight environment
Self-Supervised Joint Encoding of Motion and Appearance for First Person Action Recognition
Mirco Planamente, Andrea Bottino, Barbara Caputo

Auto-TLDR; A Single Stream Architecture for Egocentric Action Recognition from the First-Person Point of View
Abstract Slides Poster Similar
Wireless Localisation in WiFi Using Novel Deep Architectures
Peizheng Li, Han Cui, Aftab Khan, Usman Raza, Robert Piechocki, Angela Doufexi, Tim Farnham

Auto-TLDR; Deep Neural Network for Indoor Localisation of WiFi Devices in Indoor Environments
Abstract Slides Poster Similar