FC-DCNN: A Densely Connected Neural Network for Stereo Estimation
Dominik Hirner,
Friedrich Fraundorfer

Auto-TLDR; FC-DCNN: A Lightweight Network for Stereo Estimation
Similar papers
Domain Siamese CNNs for Sparse Multispectral Disparity Estimation
David-Alexandre Beaupre, Guillaume-Alexandre Bilodeau

Auto-TLDR; Multispectral Disparity Estimation between Thermal and Visible Images using Deep Neural Networks
Abstract Slides Poster Similar
Learning Stereo Matchability in Disparity Regression Networks
Jingyang Zhang, Yao Yao, Zixin Luo, Shiwei Li, Tianwei Shen, Tian Fang, Long Quan

Auto-TLDR; Deep Stereo Matchability for Weakly Matchable Regions
Deeply-Fused Attentive Network for Stereo Matching
Zuliu Yang, Xindong Ai, Weida Yang, Yong Zhao, Qifei Dai, Fuchi Li

Auto-TLDR; DF-Net: Deep Learning-based Network for Stereo Matching
Abstract Slides Poster Similar
Suppressing Features That Contain Disparity Edge for Stereo Matching
Xindong Ai, Zuliu Yang, Weida Yang, Yong Zhao, Zhengzhong Yu, Fuchi Li

Auto-TLDR; SDE-Attention: A Novel Attention Mechanism for Stereo Matching
Abstract Slides Poster Similar
Leveraging a Weakly Adversarial Paradigm for Joint Learning of Disparity and Confidence Estimation
Matteo Poggi, Fabio Tosi, Filippo Aleotti, Stefano Mattoccia

Auto-TLDR; Joint Training of Deep-Networks for Outlier Detection from Stereo Images
Abstract Slides Poster Similar
Attention Stereo Matching Network
Doudou Zhang, Jing Cai, Yanbing Xue, Zan Gao, Hua Zhang

Auto-TLDR; ASM-Net: Attention Stereo Matching with Disparity Refinement
Abstract Slides Poster Similar
Two-Stage Adaptive Object Scene Flow Using Hybrid CNN-CRF Model
Congcong Li, Haoyu Ma, Qingmin Liao

Auto-TLDR; Adaptive object scene flow estimation using a hybrid CNN-CRF model and adaptive iteration
Abstract Slides Poster Similar
Movement-Induced Priors for Deep Stereo
Yuxin Hou, Muhammad Kamran Janjua, Juho Kannala, Arno Solin

Auto-TLDR; Fusing Stereo Disparity Estimation with Movement-induced Prior Information
Abstract Slides Poster Similar
Feature Point Matching in Cross-Spectral Images with Cycle Consistency Learning
Ryosuke Furuta, Naoaki Noguchi, Xueting Wang, Toshihiko Yamasaki

Auto-TLDR; Unsupervised Learning for General Feature Point Matching in Cross-Spectral Settings
Abstract Slides Poster Similar
Extending Single Beam Lidar to Full Resolution by Fusing with Single Image Depth Estimation
Yawen Lu, Yuxing Wang, Devarth Parikh, Guoyu Lu

Auto-TLDR; Self-supervised LIDAR for Low-Cost Depth Estimation
ResFPN: Residual Skip Connections in Multi-Resolution Feature Pyramid Networks for Accurate Dense Pixel Matching
Rishav ., René Schuster, Ramy Battrawy, Oliver Wasenmüler, Didier Stricker

Auto-TLDR; Resolution Feature Pyramid Networks for Dense Pixel Matching
Real-Time Monocular Depth Estimation with Extremely Light-Weight Neural Network
Mian Jhong Chiu, Wei-Chen Chiu, Hua-Tsung Chen, Jen-Hui Chuang

Auto-TLDR; Real-Time Light-Weight Depth Prediction for Obstacle Avoidance and Environment Sensing with Deep Learning-based CNN
Abstract Slides Poster Similar
STaRFlow: A SpatioTemporal Recurrent Cell for Lightweight Multi-Frame Optical Flow Estimation
Pierre Godet, Alexandre Boulch, Aurélien Plyer, Guy Le Besnerais

Auto-TLDR; STaRFlow: A lightweight CNN-based algorithm for optical flow estimation
Abstract Slides Poster Similar
Enhancing Depth Quality of Stereo Vision Using Deep Learning-Based Prior Information of the Driving Environment
Weifu Li, Vijay John, Seiichi Mita

Auto-TLDR; A Novel Post-processing Mathematical Framework for Stereo Vision
Abstract Slides Poster Similar
HMFlow: Hybrid Matching Optical Flow Network for Small and Fast-Moving Objects
Suihanjin Yu, Youmin Zhang, Chen Wang, Xiao Bai, Liang Zhang, Edwin Hancock

Auto-TLDR; Hybrid Matching Optical Flow Network with Global Matching Component
Abstract Slides Poster Similar
P2D: A Self-Supervised Method for Depth Estimation from Polarimetry
Marc Blanchon, Desire Sidibe, Olivier Morel, Ralph Seulin, Daniel Braun, Fabrice Meriaudeau

Auto-TLDR; Polarimetric Regularization for Monocular Depth Estimation
Abstract Slides Poster Similar
NetCalib: A Novel Approach for LiDAR-Camera Auto-Calibration Based on Deep Learning
Shan Wu, Amnir Hadachi, Damien Vivet, Yadu Prabhakar

Auto-TLDR; Automatic Calibration of LiDAR and Cameras using Deep Neural Network
Abstract Slides Poster Similar
Multi-Scale Residual Pyramid Attention Network for Monocular Depth Estimation
Jing Liu, Xiaona Zhang, Zhaoxin Li, Tianlu Mao

Auto-TLDR; Multi-scale Residual Pyramid Attention Network for Monocular Depth Estimation
Abstract Slides Poster Similar
Cost Volume Refinement for Depth Prediction
João L. Cardoso, Nuno Goncalves, Michael Wimmer

Auto-TLDR; Refining the Cost Volume for Depth Prediction from Light Field Cameras
Abstract Slides Poster Similar
Fast and Efficient Neural Network for Light Field Disparity Estimation

Auto-TLDR; Improving Efficient Light Field Disparity Estimation Using Deep Neural Networks
Abstract Slides Poster Similar
Porting a Convolutional Neural Network for Stereo Matching in Hardware
Dionisis - Odysseas Sotiropoulos, George - Peter Economou

Auto-TLDR; Real-Time Stereo Matching with Artificial Neural Networks using FPGAs
Abstract Slides Poster Similar
MixedFusion: 6D Object Pose Estimation from Decoupled RGB-Depth Features
Hangtao Feng, Lu Zhang, Xu Yang, Zhiyong Liu

Auto-TLDR; MixedFusion: Combining Color and Point Clouds for 6D Pose Estimation
Abstract Slides Poster Similar
Point In: Counting Trees with Weakly Supervised Segmentation Network
Pinmo Tong, Shuhui Bu, Pengcheng Han

Auto-TLDR; Weakly Tree counting using Deep Segmentation Network with Localization and Mask Prediction
Abstract Slides Poster Similar
A Fine-Grained Dataset and Its Efficient Semantic Segmentation for Unstructured Driving Scenarios
Kai Andreas Metzger, Peter Mortimer, Hans J "Joe" Wuensche

Auto-TLDR; TAS500: A Semantic Segmentation Dataset for Autonomous Driving in Unstructured Environments
Abstract Slides Poster Similar
Multi-Scale Keypoint Matching

Auto-TLDR; Multi-Scale Keypoint Matching Using Multi-Scale Information
Abstract Slides Poster Similar
Delivering Meaningful Representation for Monocular Depth Estimation
Doyeon Kim, Donggyu Joo, Junmo Kim

Auto-TLDR; Monocular Depth Estimation by Bridging the Context between Encoding and Decoding
Abstract Slides Poster Similar
HPERL: 3D Human Pose Estimastion from RGB and LiDAR
Michael Fürst, Shriya T.P. Gupta, René Schuster, Oliver Wasenmüler, Didier Stricker

Auto-TLDR; 3D Human Pose Estimation Using RGB and LiDAR Using Weakly-Supervised Approach
Abstract Slides Poster Similar
Siamese Fully Convolutional Tracker with Motion Correction
Mathew Francis, Prithwijit Guha

Auto-TLDR; A Siamese Ensemble for Visual Tracking with Appearance and Motion Components
Abstract Slides Poster Similar
Visual Localization for Autonomous Driving: Mapping the Accurate Location in the City Maze
Dongfang Liu, Yiming Cui, Xiaolei Guo, Wei Ding, Baijian Yang, Yingjie Chen

Auto-TLDR; Feature Voting for Robust Visual Localization in Urban Settings
Abstract Slides Poster Similar
Yolo+FPN: 2D and 3D Fused Object Detection with an RGB-D Camera

Auto-TLDR; Yolo+FPN: Combining 2D and 3D Object Detection for Real-Time Object Detection
Abstract Slides Poster Similar
Siamese Dynamic Mask Estimation Network for Fast Video Object Segmentation
Dexiang Hong, Guorong Li, Kai Xu, Li Su, Qingming Huang

Auto-TLDR; Siamese Dynamic Mask Estimation for Video Object Segmentation
Abstract Slides Poster Similar
Revisiting Sequence-To-Sequence Video Object Segmentation with Multi-Task Loss and Skip-Memory
Fatemeh Azimi, Benjamin Bischke, Sebastian Palacio, Federico Raue, Jörn Hees, Andreas Dengel

Auto-TLDR; Sequence-to-Sequence Learning for Video Object Segmentation
Abstract Slides Poster Similar
Fast Multi-Level Foreground Estimation
Thomas Germer, Tobias Uelwer, Stefan Conrad, Stefan Harmeling

Auto-TLDR; Fur foreground estimation given the alpha matte
Abstract Slides Poster Similar
Object Segmentation Tracking from Generic Video Cues
Amirhossein Kardoost, Sabine Müller, Joachim Weickert, Margret Keuper

Auto-TLDR; A Light-Weight Variational Framework for Video Object Segmentation in Videos
Abstract Slides Poster Similar
Multiple Future Prediction Leveraging Synthetic Trajectories
Lorenzo Berlincioni, Federico Becattini, Lorenzo Seidenari, Alberto Del Bimbo

Auto-TLDR; Synthetic Trajectory Prediction using Markov Chains
Abstract Slides Poster Similar
Documents Counterfeit Detection through a Deep Learning Approach
Darwin Danilo Saire Pilco, Salvatore Tabbone

Auto-TLDR; End-to-End Learning for Counterfeit Documents Detection using Deep Neural Network
Abstract Slides Poster Similar
Recovery of 2D and 3D Layout Information through an Advanced Image Stitching Algorithm Using Scanning Electron Microscope Images
Aayush Singla, Bernhard Lippmann, Helmut Graeb

Auto-TLDR; Image Stitching for True Geometrical Layout Recovery in Nanoscale Dimension
Abstract Slides Poster Similar
Enhancing Deep Semantic Segmentation of RGB-D Data with Entangled Forests
Matteo Terreran, Elia Bonetto, Stefano Ghidoni

Auto-TLDR; FuseNet: A Lighter Deep Learning Model for Semantic Segmentation
Abstract Slides Poster Similar
Attention Based Coupled Framework for Road and Pothole Segmentation
Shaik Masihullah, Ritu Garg, Prerana Mukherjee, Anupama Ray

Auto-TLDR; Few Shot Learning for Road and Pothole Segmentation on KITTI and IDD
Abstract Slides Poster Similar
Revisiting Optical Flow Estimation in 360 Videos
Keshav Bhandari, Ziliang Zong, Yan Yan
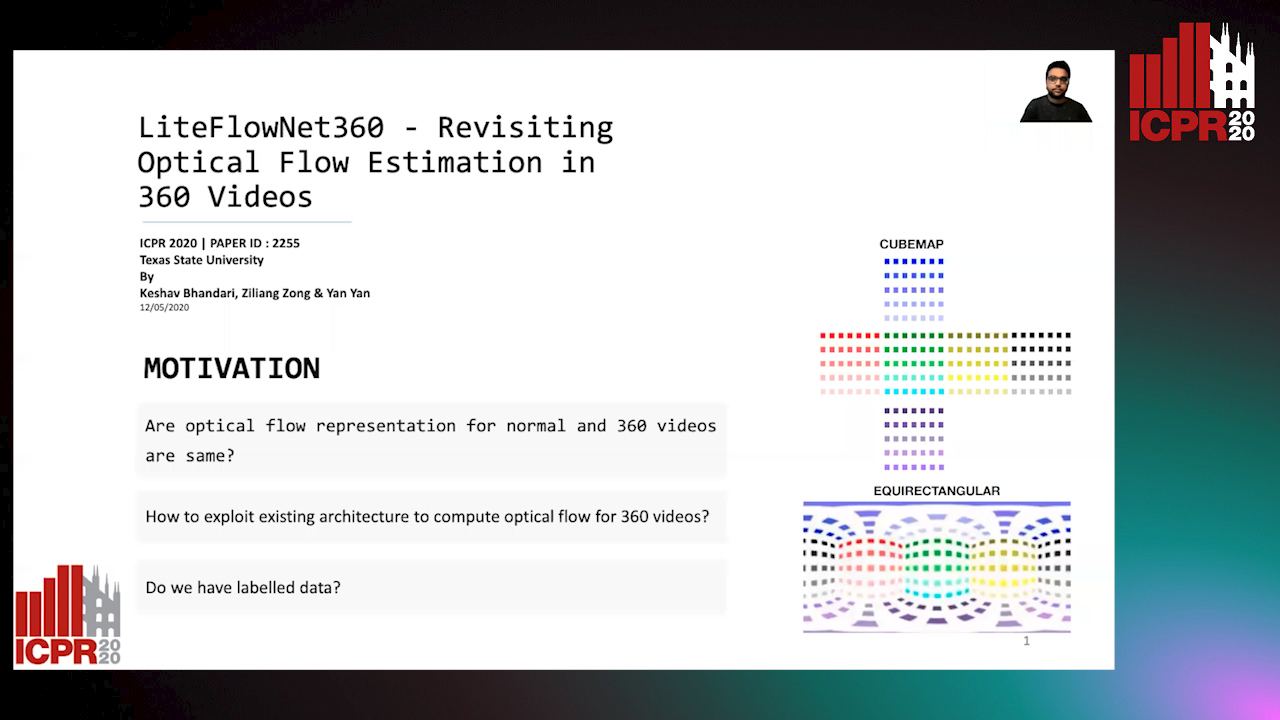
Auto-TLDR; LiteFlowNet360: A Domain Adaptation Framework for 360 Video Optical Flow Estimation
Do We Really Need Scene-Specific Pose Encoders?

Auto-TLDR; Pose Regression Using Deep Convolutional Networks for Visual Similarity
Gabriella: An Online System for Real-Time Activity Detection in Untrimmed Security Videos
Mamshad Nayeem Rizve, Ugur Demir, Praveen Praveen Tirupattur, Aayush Jung Rana, Kevin Duarte, Ishan Rajendrakumar Dave, Yogesh Rawat, Mubarak Shah

Auto-TLDR; Gabriella: A Real-Time Online System for Activity Detection in Surveillance Videos
Transitional Asymmetric Non-Local Neural Networks for Real-World Dirt Road Segmentation

Auto-TLDR; Transitional Asymmetric Non-Local Neural Networks for Semantic Segmentation on Dirt Roads
Abstract Slides Poster Similar
DR2S: Deep Regression with Region Selection for Camera Quality Evaluation
Marcelin Tworski, Stéphane Lathuiliere, Salim Belkarfa, Attilio Fiandrotti, Marco Cagnazzo

Auto-TLDR; Texture Quality Estimation Using Deep Learning
Abstract Slides Poster Similar
Light3DPose: Real-Time Multi-Person 3D Pose Estimation from Multiple Views
Alessio Elmi, Davide Mazzini, Pietro Tortella

Auto-TLDR; 3D Pose Estimation of Multiple People from a Few calibrated Camera Views using Deep Learning
Abstract Slides Poster Similar
Object Detection Model Based on Scene-Level Region Proposal Self-Attention
Yu Quan, Zhixin Li, Canlong Zhang, Huifang Ma

Auto-TLDR; Exploiting Semantic Informations for Object Detection
Abstract Slides Poster Similar
Improving Gravitational Wave Detection with 2D Convolutional Neural Networks
Siyu Fan, Yisen Wang, Yuan Luo, Alexander Michael Schmitt, Shenghua Yu

Auto-TLDR; Two-dimensional Convolutional Neural Networks for Gravitational Wave Detection from Time Series with Background Noise
A Lightweight Network to Learn Optical Flow from Event Data

Auto-TLDR; A lightweight pyramid network with attention mechanism to learn optical flow from events data