ResFPN: Residual Skip Connections in Multi-Resolution Feature Pyramid Networks for Accurate Dense Pixel Matching
Rishav .,
René Schuster,
Ramy Battrawy,
Oliver Wasenmüler,
Didier Stricker

Auto-TLDR; Resolution Feature Pyramid Networks for Dense Pixel Matching
Similar papers
Deeply-Fused Attentive Network for Stereo Matching
Zuliu Yang, Xindong Ai, Weida Yang, Yong Zhao, Qifei Dai, Fuchi Li

Auto-TLDR; DF-Net: Deep Learning-based Network for Stereo Matching
Abstract Slides Poster Similar
Learning Stereo Matchability in Disparity Regression Networks
Jingyang Zhang, Yao Yao, Zixin Luo, Shiwei Li, Tianwei Shen, Tian Fang, Long Quan

Auto-TLDR; Deep Stereo Matchability for Weakly Matchable Regions
HMFlow: Hybrid Matching Optical Flow Network for Small and Fast-Moving Objects
Suihanjin Yu, Youmin Zhang, Chen Wang, Xiao Bai, Liang Zhang, Edwin Hancock

Auto-TLDR; Hybrid Matching Optical Flow Network with Global Matching Component
Abstract Slides Poster Similar
Attention Stereo Matching Network
Doudou Zhang, Jing Cai, Yanbing Xue, Zan Gao, Hua Zhang

Auto-TLDR; ASM-Net: Attention Stereo Matching with Disparity Refinement
Abstract Slides Poster Similar
STaRFlow: A SpatioTemporal Recurrent Cell for Lightweight Multi-Frame Optical Flow Estimation
Pierre Godet, Alexandre Boulch, Aurélien Plyer, Guy Le Besnerais

Auto-TLDR; STaRFlow: A lightweight CNN-based algorithm for optical flow estimation
Abstract Slides Poster Similar
Suppressing Features That Contain Disparity Edge for Stereo Matching
Xindong Ai, Zuliu Yang, Weida Yang, Yong Zhao, Zhengzhong Yu, Fuchi Li

Auto-TLDR; SDE-Attention: A Novel Attention Mechanism for Stereo Matching
Abstract Slides Poster Similar
Two-Stage Adaptive Object Scene Flow Using Hybrid CNN-CRF Model
Congcong Li, Haoyu Ma, Qingmin Liao

Auto-TLDR; Adaptive object scene flow estimation using a hybrid CNN-CRF model and adaptive iteration
Abstract Slides Poster Similar
Movement-Induced Priors for Deep Stereo
Yuxin Hou, Muhammad Kamran Janjua, Juho Kannala, Arno Solin

Auto-TLDR; Fusing Stereo Disparity Estimation with Movement-induced Prior Information
Abstract Slides Poster Similar
Leveraging a Weakly Adversarial Paradigm for Joint Learning of Disparity and Confidence Estimation
Matteo Poggi, Fabio Tosi, Filippo Aleotti, Stefano Mattoccia

Auto-TLDR; Joint Training of Deep-Networks for Outlier Detection from Stereo Images
Abstract Slides Poster Similar
Delivering Meaningful Representation for Monocular Depth Estimation
Doyeon Kim, Donggyu Joo, Junmo Kim

Auto-TLDR; Monocular Depth Estimation by Bridging the Context between Encoding and Decoding
Abstract Slides Poster Similar
FC-DCNN: A Densely Connected Neural Network for Stereo Estimation
Dominik Hirner, Friedrich Fraundorfer

Auto-TLDR; FC-DCNN: A Lightweight Network for Stereo Estimation
Abstract Slides Poster Similar
PA-FlowNet: Pose-Auxiliary Optical Flow Network for Spacecraft Relative Pose Estimation
Zhi Yu Chen, Po-Heng Chen, Kuan-Wen Chen, Chen-Yu Chan

Auto-TLDR; PA-FlowNet: An End-to-End Pose-auxiliary Optical Flow Network for Space Travel and Landing
Abstract Slides Poster Similar
Transitional Asymmetric Non-Local Neural Networks for Real-World Dirt Road Segmentation

Auto-TLDR; Transitional Asymmetric Non-Local Neural Networks for Semantic Segmentation on Dirt Roads
Abstract Slides Poster Similar
Bidirectional Matrix Feature Pyramid Network for Object Detection

Auto-TLDR; BMFPN: Bidirectional Matrix Feature Pyramid Network for Object Detection
Abstract Slides Poster Similar
Context-Aware Residual Module for Image Classification

Auto-TLDR; Context-Aware Residual Module for Image Classification
Abstract Slides Poster Similar
Efficient-Receptive Field Block with Group Spatial Attention Mechanism for Object Detection
Jiacheng Zhang, Zhicheng Zhao, Fei Su

Auto-TLDR; E-RFB: Efficient-Receptive Field Block for Deep Neural Network for Object Detection
Abstract Slides Poster Similar
A Novel Region of Interest Extraction Layer for Instance Segmentation
Leonardo Rossi, Akbar Karimi, Andrea Prati

Auto-TLDR; Generic RoI Extractor for Two-Stage Neural Network for Instance Segmentation
Abstract Slides Poster Similar
Real-Time Monocular Depth Estimation with Extremely Light-Weight Neural Network
Mian Jhong Chiu, Wei-Chen Chiu, Hua-Tsung Chen, Jen-Hui Chuang

Auto-TLDR; Real-Time Light-Weight Depth Prediction for Obstacle Avoidance and Environment Sensing with Deep Learning-based CNN
Abstract Slides Poster Similar
Extending Single Beam Lidar to Full Resolution by Fusing with Single Image Depth Estimation
Yawen Lu, Yuxing Wang, Devarth Parikh, Guoyu Lu

Auto-TLDR; Self-supervised LIDAR for Low-Cost Depth Estimation
Domain Siamese CNNs for Sparse Multispectral Disparity Estimation
David-Alexandre Beaupre, Guillaume-Alexandre Bilodeau

Auto-TLDR; Multispectral Disparity Estimation between Thermal and Visible Images using Deep Neural Networks
Abstract Slides Poster Similar
Multi-Scale Residual Pyramid Attention Network for Monocular Depth Estimation
Jing Liu, Xiaona Zhang, Zhaoxin Li, Tianlu Mao

Auto-TLDR; Multi-scale Residual Pyramid Attention Network for Monocular Depth Estimation
Abstract Slides Poster Similar
Fast and Accurate Real-Time Semantic Segmentation with Dilated Asymmetric Convolutions
Leonel Rosas-Arias, Gibran Benitez-Garcia, Jose Portillo-Portillo, Gabriel Sanchez-Perez, Keiji Yanai

Auto-TLDR; FASSD-Net: Dilated Asymmetric Pyramidal Fusion for Real-Time Semantic Segmentation
Abstract Slides Poster Similar
Revisiting Optical Flow Estimation in 360 Videos
Keshav Bhandari, Ziliang Zong, Yan Yan
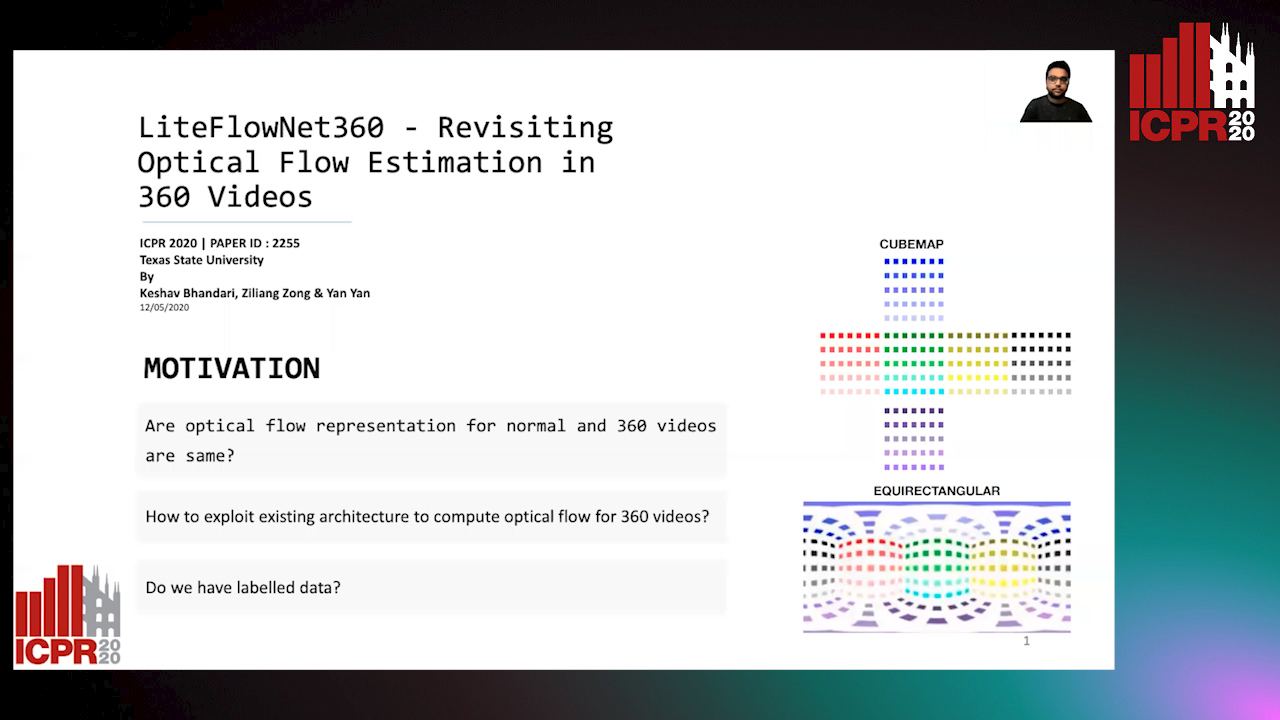
Auto-TLDR; LiteFlowNet360: A Domain Adaptation Framework for 360 Video Optical Flow Estimation
OmniFlowNet: A Perspective Neural Network Adaptation for Optical Flow Estimation in Omnidirectional Images
Charles-Olivier Artizzu, Haozhou Zhang, Guillaume Allibert, Cédric Demonceaux

Auto-TLDR; OmniFlowNet: A Convolutional Neural Network for Omnidirectional Optical Flow Estimation
Abstract Slides Poster Similar
Encoder-Decoder Based Convolutional Neural Networks with Multi-Scale-Aware Modules for Crowd Counting
Pongpisit Thanasutives, Ken-Ichi Fukui, Masayuki Numao, Boonserm Kijsirikul

Auto-TLDR; M-SFANet and M-SegNet for Crowd Counting Using Multi-Scale Fusion Networks
Abstract Slides Poster Similar
Hierarchically Aggregated Residual Transformation for Single Image Super Resolution

Auto-TLDR; HARTnet: Hierarchically Aggregated Residual Transformation for Multi-Scale Super-resolution
Abstract Slides Poster Similar
A Lightweight Network to Learn Optical Flow from Event Data

Auto-TLDR; A lightweight pyramid network with attention mechanism to learn optical flow from events data
Improved Residual Networks for Image and Video Recognition
Ionut Cosmin Duta, Li Liu, Fan Zhu, Ling Shao

Auto-TLDR; Residual Networks for Deep Learning
Abstract Slides Poster Similar
SFPN: Semantic Feature Pyramid Network for Object Detection

Auto-TLDR; SFPN: Semantic Feature Pyramid Network to Address Information Dilution Issue in FPN
Abstract Slides Poster Similar
PSDNet: A Balanced Architecture of Accuracy and Parameters for Semantic Segmentation

Auto-TLDR; Pyramid Pooling Module with SE1Cblock and D2SUpsample Network (PSDNet)
Abstract Slides Poster Similar
Revisiting Sequence-To-Sequence Video Object Segmentation with Multi-Task Loss and Skip-Memory
Fatemeh Azimi, Benjamin Bischke, Sebastian Palacio, Federico Raue, Jörn Hees, Andreas Dengel

Auto-TLDR; Sequence-to-Sequence Learning for Video Object Segmentation
Abstract Slides Poster Similar
HPERL: 3D Human Pose Estimastion from RGB and LiDAR
Michael Fürst, Shriya T.P. Gupta, René Schuster, Oliver Wasenmüler, Didier Stricker

Auto-TLDR; 3D Human Pose Estimation Using RGB and LiDAR Using Weakly-Supervised Approach
Abstract Slides Poster Similar
Dynamic Guided Network for Monocular Depth Estimation
Xiaoxia Xing, Yinghao Cai, Yiping Yang, Dayong Wen

Auto-TLDR; DGNet: Dynamic Guidance Upsampling for Self-attention-Decoding for Monocular Depth Estimation
Abstract Slides Poster Similar
ScarfNet: Multi-Scale Features with Deeply Fused and Redistributed Semantics for Enhanced Object Detection
Jin Hyeok Yoo, Dongsuk Kum, Jun Won Choi

Auto-TLDR; Semantic Fusion of Multi-scale Feature Maps for Object Detection
Abstract Slides Poster Similar
Fast and Efficient Neural Network for Light Field Disparity Estimation

Auto-TLDR; Improving Efficient Light Field Disparity Estimation Using Deep Neural Networks
Abstract Slides Poster Similar
Ordinal Depth Classification Using Region-Based Self-Attention
Minh Hieu Phan, Son Lam Phung, Abdesselam Bouzerdoum

Auto-TLDR; Region-based Self-Attention for Multi-scale Depth Estimation from a Single 2D Image
Abstract Slides Poster Similar
P2 Net: Augmented Parallel-Pyramid Net for Attention Guided Pose Estimation
Luanxuan Hou, Jie Cao, Yuan Zhao, Haifeng Shen, Jian Tang, Ran He

Auto-TLDR; Parallel-Pyramid Net with Partial Attention for Human Pose Estimation
Abstract Slides Poster Similar
Dual Encoder Fusion U-Net (DEFU-Net) for Cross-manufacturer Chest X-Ray Segmentation
Zhang Lipei, Aozhi Liu, Jing Xiao
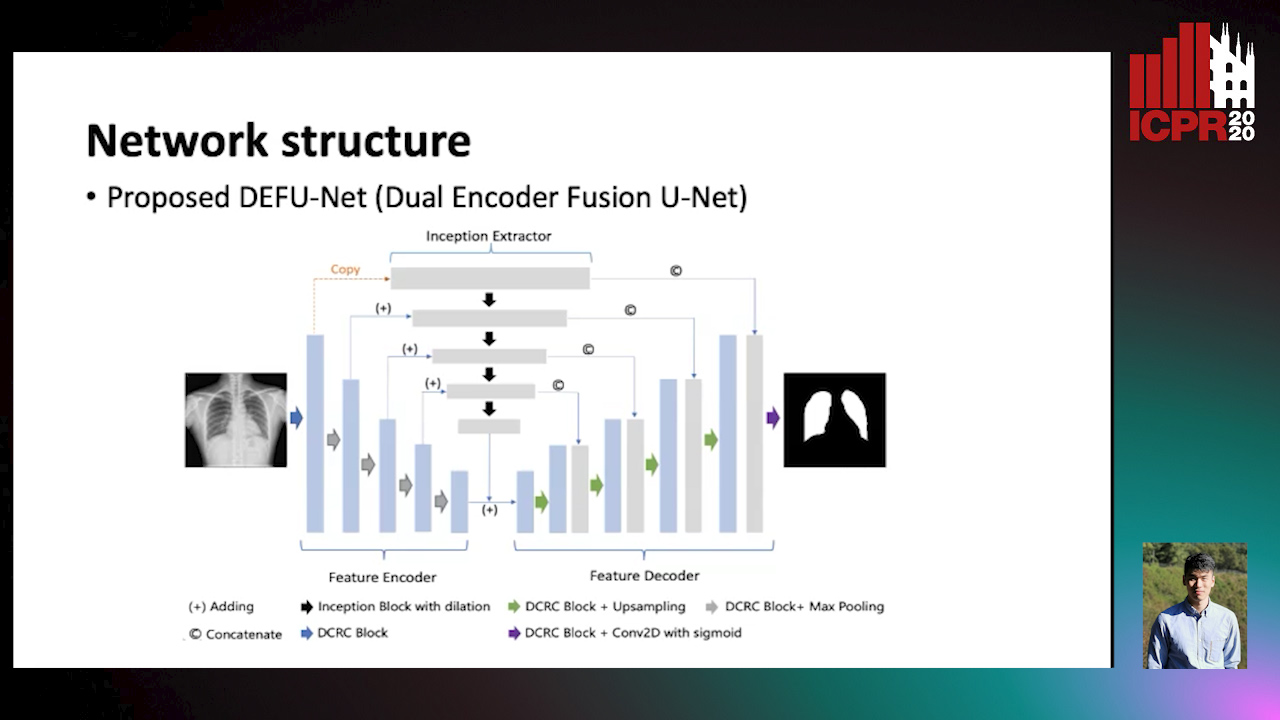
Auto-TLDR; Inception Convolutional Neural Network with Dilation for Chest X-Ray Segmentation
Enhanced Feature Pyramid Network for Semantic Segmentation
Mucong Ye, Ouyang Jinpeng, Ge Chen, Jing Zhang, Xiaogang Yu

Auto-TLDR; EFPN: Enhanced Feature Pyramid Network for Semantic Segmentation
Abstract Slides Poster Similar
Attention Pyramid Module for Scene Recognition
Zhinan Qiao, Xiaohui Yuan, Chengyuan Zhuang, Abolfazl Meyarian

Auto-TLDR; Attention Pyramid Module for Multi-Scale Scene Recognition
Abstract Slides Poster Similar
CAggNet: Crossing Aggregation Network for Medical Image Segmentation

Auto-TLDR; Crossing Aggregation Network for Medical Image Segmentation
Abstract Slides Poster Similar
Feature Point Matching in Cross-Spectral Images with Cycle Consistency Learning
Ryosuke Furuta, Naoaki Noguchi, Xueting Wang, Toshihiko Yamasaki

Auto-TLDR; Unsupervised Learning for General Feature Point Matching in Cross-Spectral Settings
Abstract Slides Poster Similar
Learning a Dynamic High-Resolution Network for Multi-Scale Pedestrian Detection
Mengyuan Ding, Shanshan Zhang, Jian Yang

Auto-TLDR; Learningable Dynamic HRNet for Pedestrian Detection
Abstract Slides Poster Similar
Human Segmentation with Dynamic LiDAR Data
Tao Zhong, Wonjik Kim, Masayuki Tanaka, Masatoshi Okutomi

Auto-TLDR; Spatiotemporal Neural Network for Human Segmentation with Dynamic Point Clouds
Siamese Dynamic Mask Estimation Network for Fast Video Object Segmentation
Dexiang Hong, Guorong Li, Kai Xu, Li Su, Qingming Huang

Auto-TLDR; Siamese Dynamic Mask Estimation for Video Object Segmentation
Abstract Slides Poster Similar
FastCompletion: A Cascade Network with Multiscale Group-Fused Inputs for Real-Time Depth Completion
Ang Li, Zejian Yuan, Yonggen Ling, Wanchao Chi, Shenghao Zhang, Chong Zhang

Auto-TLDR; Efficient Depth Completion with Clustered Hourglass Networks
Abstract Slides Poster Similar
Boundary-Aware Graph Convolution for Semantic Segmentation
Hanzhe Hu, Jinshi Cui, Jinshi Hongbin Zha

Auto-TLDR; Boundary-Aware Graph Convolution for Semantic Segmentation
Abstract Slides Poster Similar
Wavelet Attention Embedding Networks for Video Super-Resolution
Young-Ju Choi, Young-Woon Lee, Byung-Gyu Kim

Auto-TLDR; Wavelet Attention Embedding Network for Video Super-Resolution
Abstract Slides Poster Similar