Fast and Accurate Real-Time Semantic Segmentation with Dilated Asymmetric Convolutions
Leonel Rosas-Arias,
Gibran Benitez-Garcia,
Jose Portillo-Portillo,
Gabriel Sanchez-Perez,
Keiji Yanai

Auto-TLDR; FASSD-Net: Dilated Asymmetric Pyramidal Fusion for Real-Time Semantic Segmentation
Similar papers
Multi-Direction Convolution for Semantic Segmentation
Dehui Li, Zhiguo Cao, Ke Xian, Xinyuan Qi, Chao Zhang, Hao Lu

Auto-TLDR; Multi-Direction Convolution for Contextual Segmentation
Transitional Asymmetric Non-Local Neural Networks for Real-World Dirt Road Segmentation

Auto-TLDR; Transitional Asymmetric Non-Local Neural Networks for Semantic Segmentation on Dirt Roads
Abstract Slides Poster Similar
Real-Time Semantic Segmentation Via Region and Pixel Context Network
Yajun Li, Yazhou Liu, Quansen Sun

Auto-TLDR; A Dual Context Network for Real-Time Semantic Segmentation
Abstract Slides Poster Similar
Global-Local Attention Network for Semantic Segmentation in Aerial Images
Minglong Li, Lianlei Shan, Weiqiang Wang

Auto-TLDR; GLANet: Global-Local Attention Network for Semantic Segmentation
Abstract Slides Poster Similar
PSDNet: A Balanced Architecture of Accuracy and Parameters for Semantic Segmentation

Auto-TLDR; Pyramid Pooling Module with SE1Cblock and D2SUpsample Network (PSDNet)
Abstract Slides Poster Similar
GSTO: Gated Scale-Transfer Operation for Multi-Scale Feature Learning in Semantic Segmentation
Zhuoying Wang, Yongtao Wang, Zhi Tang, Yangyan Li, Ying Chen, Haibin Ling, Weisi Lin

Auto-TLDR; Gated Scale-Transfer Operation for Semantic Segmentation
Abstract Slides Poster Similar
Semantic Segmentation Refinement Using Entropy and Boundary-guided Monte Carlo Sampling and Directed Regional Search
Zitang Sun, Sei-Ichiro Kamata, Ruojing Wang, Weili Chen

Auto-TLDR; Directed Region Search and Refinement for Semantic Segmentation
Abstract Slides Poster Similar
Enhanced Feature Pyramid Network for Semantic Segmentation
Mucong Ye, Ouyang Jinpeng, Ge Chen, Jing Zhang, Xiaogang Yu

Auto-TLDR; EFPN: Enhanced Feature Pyramid Network for Semantic Segmentation
Abstract Slides Poster Similar
Boundary-Aware Graph Convolution for Semantic Segmentation
Hanzhe Hu, Jinshi Cui, Jinshi Hongbin Zha

Auto-TLDR; Boundary-Aware Graph Convolution for Semantic Segmentation
Abstract Slides Poster Similar
E-DNAS: Differentiable Neural Architecture Search for Embedded Systems
Javier García López, Antonio Agudo, Francesc Moreno-Noguer

Auto-TLDR; E-DNAS: Differentiable Architecture Search for Light-Weight Networks for Image Classification
Abstract Slides Poster Similar
Enhancing Semantic Segmentation of Aerial Images with Inhibitory Neurons
Ihsan Ullah, Sean Reilly, Michael Madden

Auto-TLDR; Lateral Inhibition in Deep Neural Networks for Object Recognition and Semantic Segmentation
Abstract Slides Poster Similar
A Fine-Grained Dataset and Its Efficient Semantic Segmentation for Unstructured Driving Scenarios
Kai Andreas Metzger, Peter Mortimer, Hans J "Joe" Wuensche

Auto-TLDR; TAS500: A Semantic Segmentation Dataset for Autonomous Driving in Unstructured Environments
Abstract Slides Poster Similar
FastCompletion: A Cascade Network with Multiscale Group-Fused Inputs for Real-Time Depth Completion
Ang Li, Zejian Yuan, Yonggen Ling, Wanchao Chi, Shenghao Zhang, Chong Zhang

Auto-TLDR; Efficient Depth Completion with Clustered Hourglass Networks
Abstract Slides Poster Similar
Multiscale Attention-Based Prototypical Network for Few-Shot Semantic Segmentation
Yifei Zhang, Desire Sidibe, Olivier Morel, Fabrice Meriaudeau

Auto-TLDR; Few-shot Semantic Segmentation with Multiscale Feature Attention
Stage-Wise Neural Architecture Search
Artur Jordão, Fernando Akio Yamada, Maiko Lie, William Schwartz

Auto-TLDR; Efficient Neural Architecture Search for Deep Convolutional Networks
Abstract Slides Poster Similar
Context-Aware Residual Module for Image Classification

Auto-TLDR; Context-Aware Residual Module for Image Classification
Abstract Slides Poster Similar
UHRSNet: A Semantic Segmentation Network Specifically for Ultra-High-Resolution Images

Auto-TLDR; Ultra-High-Resolution Segmentation with Local and Global Feature Fusion
Encoder-Decoder Based Convolutional Neural Networks with Multi-Scale-Aware Modules for Crowd Counting
Pongpisit Thanasutives, Ken-Ichi Fukui, Masayuki Numao, Boonserm Kijsirikul

Auto-TLDR; M-SFANet and M-SegNet for Crowd Counting Using Multi-Scale Fusion Networks
Abstract Slides Poster Similar
NAS-EOD: An End-To-End Neural Architecture Search Method for Efficient Object Detection
Huigang Zhang, Liuan Wang, Jun Sun, Li Sun, Hiromichi Kobashi, Nobutaka Imamura

Auto-TLDR; NAS-EOD: Neural Architecture Search for Object Detection on Edge Devices
EdgeNet: Semantic Scene Completion from a Single RGB-D Image
Aloisio Dourado, Teofilo De Campos, Adrian Hilton, Hansung Kim

Auto-TLDR; Semantic Scene Completion using 3D Depth and RGB Information
Abstract Slides Poster Similar
Real-Time Monocular Depth Estimation with Extremely Light-Weight Neural Network
Mian Jhong Chiu, Wei-Chen Chiu, Hua-Tsung Chen, Jen-Hui Chuang

Auto-TLDR; Real-Time Light-Weight Depth Prediction for Obstacle Avoidance and Environment Sensing with Deep Learning-based CNN
Abstract Slides Poster Similar
Triplet-Path Dilated Network for Detection and Segmentation of General Pathological Images
Jiaqi Luo, Zhicheng Zhao, Fei Su, Limei Guo

Auto-TLDR; Triplet-path Network for One-Stage Object Detection and Segmentation in Pathological Images
Attention Pyramid Module for Scene Recognition
Zhinan Qiao, Xiaohui Yuan, Chengyuan Zhuang, Abolfazl Meyarian

Auto-TLDR; Attention Pyramid Module for Multi-Scale Scene Recognition
Abstract Slides Poster Similar
Multiple Document Datasets Pre-Training Improves Text Line Detection with Deep Neural Networks
Mélodie Boillet, Christopher Kermorvant, Thierry Paquet

Auto-TLDR; A fully convolutional network for document layout analysis
OCT Image Segmentation Using NeuralArchitecture Search and SRGAN
Saba Heidari, Omid Dehzangi, Nasser M. Nasarabadi, Ali Rezai

Auto-TLDR; Automatic Segmentation of Retinal Layers in Optical Coherence Tomography using Neural Architecture Search
Attention Based Coupled Framework for Road and Pothole Segmentation
Shaik Masihullah, Ritu Garg, Prerana Mukherjee, Anupama Ray

Auto-TLDR; Few Shot Learning for Road and Pothole Segmentation on KITTI and IDD
Abstract Slides Poster Similar
Delivering Meaningful Representation for Monocular Depth Estimation
Doyeon Kim, Donggyu Joo, Junmo Kim

Auto-TLDR; Monocular Depth Estimation by Bridging the Context between Encoding and Decoding
Abstract Slides Poster Similar
Attention As Activation
Yimian Dai, Stefan Oehmcke, Fabian Gieseke, Yiquan Wu, Kobus Barnard

Auto-TLDR; Attentional Activation Units for Convolutional Networks
Boosting High-Level Vision with Joint Compression Artifacts Reduction and Super-Resolution
Xiaoyu Xiang, Qian Lin, Jan Allebach

Auto-TLDR; A Context-Aware Joint CAR and SR Neural Network for High-Resolution Text Recognition and Face Detection
Abstract Slides Poster Similar
VPU Specific CNNs through Neural Architecture Search
Ciarán Donegan, Hamza Yous, Saksham Sinha, Jonathan Byrne

Auto-TLDR; Efficient Convolutional Neural Networks for Edge Devices using Neural Architecture Search
Abstract Slides Poster Similar
Efficient-Receptive Field Block with Group Spatial Attention Mechanism for Object Detection
Jiacheng Zhang, Zhicheng Zhao, Fei Su

Auto-TLDR; E-RFB: Efficient-Receptive Field Block for Deep Neural Network for Object Detection
Abstract Slides Poster Similar
Progressive Scene Segmentation Based on Self-Attention Mechanism
Yunyi Pan, Yuan Gan, Kun Liu, Yan Zhang

Auto-TLDR; Two-Stage Semantic Scene Segmentation with Self-Attention
Abstract Slides Poster Similar
FastSal: A Computationally Efficient Network for Visual Saliency Prediction

Auto-TLDR; MobileNetV2: A Convolutional Neural Network for Saliency Prediction
Abstract Slides Poster Similar
Dual Encoder Fusion U-Net (DEFU-Net) for Cross-manufacturer Chest X-Ray Segmentation
Zhang Lipei, Aozhi Liu, Jing Xiao
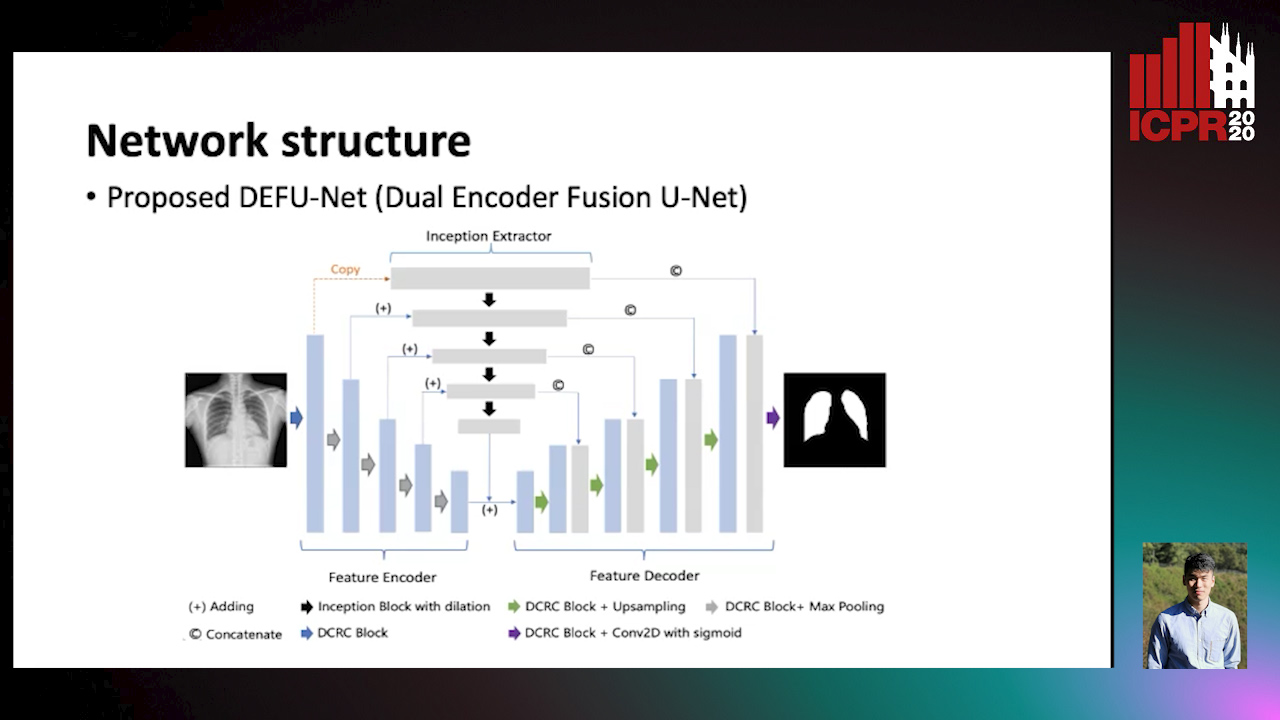
Auto-TLDR; Inception Convolutional Neural Network with Dilation for Chest X-Ray Segmentation
Hierarchically Aggregated Residual Transformation for Single Image Super Resolution

Auto-TLDR; HARTnet: Hierarchically Aggregated Residual Transformation for Multi-Scale Super-resolution
Abstract Slides Poster Similar
LiNet: A Lightweight Network for Image Super Resolution
Armin Mehri, Parichehr Behjati Ardakani, Angel D. Sappa

Auto-TLDR; LiNet: A Compact Dense Network for Lightweight Super Resolution
Abstract Slides Poster Similar
Neural Architecture Search for Image Super-Resolution Using Densely Connected Search Space: DeCoNAS

Auto-TLDR; DeCoNASNet: Automated Neural Architecture Search for Super-Resolution
Abstract Slides Poster Similar
Operation and Topology Aware Fast Differentiable Architecture Search
Shahid Siddiqui, Christos Kyrkou, Theocharis Theocharides

Auto-TLDR; EDARTS: Efficient Differentiable Architecture Search with Efficient Optimization
Abstract Slides Poster Similar
Dynamic Multi-Path Neural Network
Yingcheng Su, Yichao Wu, Ken Chen, Ding Liang, Xiaolin Hu

Auto-TLDR; Dynamic Multi-path Neural Network
Temporal Feature Enhancement Network with External Memory for Object Detection in Surveillance Video
Masato Fujitake, Akihiro Sugimoto

Auto-TLDR; Temporal Attention Based External Memory Network for Surveillance Object Detection
ResFPN: Residual Skip Connections in Multi-Resolution Feature Pyramid Networks for Accurate Dense Pixel Matching
Rishav ., René Schuster, Ramy Battrawy, Oliver Wasenmüler, Didier Stricker

Auto-TLDR; Resolution Feature Pyramid Networks for Dense Pixel Matching
Slimming ResNet by Slimming Shortcut
Donggyu Joo, Doyeon Kim, Junmo Kim

Auto-TLDR; SSPruning: Slimming Shortcut Pruning on ResNet Based Networks
Abstract Slides Poster Similar
Dynamic Guided Network for Monocular Depth Estimation
Xiaoxia Xing, Yinghao Cai, Yiping Yang, Dayong Wen

Auto-TLDR; DGNet: Dynamic Guidance Upsampling for Self-attention-Decoding for Monocular Depth Estimation
Abstract Slides Poster Similar
Deeply-Fused Attentive Network for Stereo Matching
Zuliu Yang, Xindong Ai, Weida Yang, Yong Zhao, Qifei Dai, Fuchi Li

Auto-TLDR; DF-Net: Deep Learning-based Network for Stereo Matching
Abstract Slides Poster Similar
BiLuNet: A Multi-Path Network for Semantic Segmentation on X-Ray Images
Van Luan Tran, Huei-Yung Lin, Rachel Liu, Chun-Han Tseng, Chun-Han Tseng

Auto-TLDR; BiLuNet: Multi-path Convolutional Neural Network for Semantic Segmentation of Lumbar vertebrae, sacrum,
PC-Net: A Deep Network for 3D Point Clouds Analysis
Zhuo Chen, Tao Guan, Yawei Luo, Yuesong Wang

Auto-TLDR; PC-Net: A Hierarchical Neural Network for 3D Point Clouds Analysis
Abstract Slides Poster Similar
Fine-Tuning DARTS for Image Classification
Muhammad Suhaib Tanveer, Umar Karim Khan, Chong Min Kyung

Auto-TLDR; Fine-Tune Neural Architecture Search using Fixed Operations
Abstract Slides Poster Similar
FatNet: A Feature-Attentive Network for 3D Point Cloud Processing
Chaitanya Kaul, Nick Pears, Suresh Manandhar

Auto-TLDR; Feature-Attentive Neural Networks for Point Cloud Classification and Segmentation