Multiple Document Datasets Pre-Training Improves Text Line Detection with Deep Neural Networks
Mélodie Boillet,
Christopher Kermorvant,
Thierry Paquet

Auto-TLDR; A fully convolutional network for document layout analysis
Similar papers
Text Baseline Recognition Using a Recurrent Convolutional Neural Network
Matthias Wödlinger, Robert Sablatnig

Auto-TLDR; Automatic Baseline Detection of Handwritten Text Using Recurrent Convolutional Neural Network
Abstract Slides Poster Similar
Combining Deep and Ad-Hoc Solutions to Localize Text Lines in Ancient Arabic Document Images
Olfa Mechi, Maroua Mehri, Rolf Ingold, Najoua Essoukri Ben Amara

Auto-TLDR; Text Line Localization in Ancient Handwritten Arabic Document Images using U-Net and Topological Structural Analysis
Abstract Slides Poster Similar
Unsupervised deep learning for text line segmentation
Berat Kurar Barakat, Ahmad Droby, Reem Alaasam, Borak Madi, Irina Rabaev, Raed Shammes, Jihad El-Sana

Auto-TLDR; Unsupervised Deep Learning for Handwritten Text Line Segmentation without Annotation
The HisClima Database: Historical Weather Logs for Automatic Transcription and Information Extraction
Verónica Romero, Joan Andreu Sánchez

Auto-TLDR; Automatic Handwritten Text Recognition and Information Extraction from Historical Weather Logs
Abstract Slides Poster Similar
Watch Your Strokes: Improving Handwritten Text Recognition with Deformable Convolutions
Iulian Cojocaru, Silvia Cascianelli, Lorenzo Baraldi, Massimiliano Corsini, Rita Cucchiara

Auto-TLDR; Deformable Convolutional Neural Networks for Handwritten Text Recognition
Abstract Slides Poster Similar
An Evaluation of DNN Architectures for Page Segmentation of Historical Newspapers
Manuel Burghardt, Bernhard Liebl

Auto-TLDR; Evaluation of Backbone Architectures for Optical Character Segmentation of Historical Documents
Abstract Slides Poster Similar
Vision-Based Layout Detection from Scientific Literature Using Recurrent Convolutional Neural Networks

Auto-TLDR; Transfer Learning for Scientific Literature Layout Detection Using Convolutional Neural Networks
Abstract Slides Poster Similar
A Gated and Bifurcated Stacked U-Net Module for Document Image Dewarping
Hmrishav Bandyopadhyay, Tanmoy Dasgupta, Nibaran Das, Mita Nasipuri

Auto-TLDR; Gated and Bifurcated Stacked U-Net for Dewarping Document Images
Abstract Slides Poster Similar
End-To-End Hierarchical Relation Extraction for Generic Form Understanding
Tuan Anh Nguyen Dang, Duc-Thanh Hoang, Quang Bach Tran, Chih-Wei Pan, Thanh-Dat Nguyen

Auto-TLDR; Joint Entity Labeling and Link Prediction for Form Understanding in Noisy Scanned Documents
Abstract Slides Poster Similar
Enhancing Semantic Segmentation of Aerial Images with Inhibitory Neurons
Ihsan Ullah, Sean Reilly, Michael Madden

Auto-TLDR; Lateral Inhibition in Deep Neural Networks for Object Recognition and Semantic Segmentation
Abstract Slides Poster Similar
Mutually Guided Dual-Task Network for Scene Text Detection
Mengbiao Zhao, Wei Feng, Fei Yin, Xu-Yao Zhang, Cheng-Lin Liu

Auto-TLDR; A dual-task network for word-level and line-level text detection
Learning to Sort Handwritten Text Lines in Reading Order through Estimated Binary Order Relations

Auto-TLDR; Automatic Reading Order of Text Lines in Handwritten Text Documents
Ancient Document Layout Analysis: Autoencoders Meet Sparse Coding
Homa Davoudi, Marco Fiorucci, Arianna Traviglia

Auto-TLDR; Unsupervised Unsupervised Representation Learning for Document Layout Analysis
Abstract Slides Poster Similar
Fast and Accurate Real-Time Semantic Segmentation with Dilated Asymmetric Convolutions
Leonel Rosas-Arias, Gibran Benitez-Garcia, Jose Portillo-Portillo, Gabriel Sanchez-Perez, Keiji Yanai

Auto-TLDR; FASSD-Net: Dilated Asymmetric Pyramidal Fusion for Real-Time Semantic Segmentation
Abstract Slides Poster Similar
Writer Identification Using Deep Neural Networks: Impact of Patch Size and Number of Patches
Akshay Punjabi, José Ramón Prieto Fontcuberta, Enrique Vidal

Auto-TLDR; Writer Recognition Using Deep Neural Networks for Handwritten Text Images
Abstract Slides Poster Similar
CDeC-Net: Composite Deformable Cascade Network for Table Detection in Document Images
Madhav Agarwal, Ajoy Mondal, C. V. Jawahar

Auto-TLDR; CDeC-Net: An End-to-End Trainable Deep Network for Detecting Tables in Document Images
A Few-Shot Learning Approach for Historical Ciphered Manuscript Recognition
Mohamed Ali Souibgui, Alicia Fornés, Yousri Kessentini, Crina Tudor

Auto-TLDR; Handwritten Ciphers Recognition Using Few-Shot Object Detection
Multimodal Side-Tuning for Document Classification
Stefano Zingaro, Giuseppe Lisanti, Maurizio Gabbrielli

Auto-TLDR; Side-tuning for Multimodal Document Classification
Abstract Slides Poster Similar
Image-Based Table Cell Detection: A New Dataset and an Improved Detection Method
Dafeng Wei, Hongtao Lu, Yi Zhou, Kai Chen

Auto-TLDR; TableCell: A Semi-supervised Dataset for Table-wise Detection and Recognition
Abstract Slides Poster Similar
LODENet: A Holistic Approach to Offline Handwritten Chinese and Japanese Text Line Recognition
Huu Tin Hoang, Chun-Jen Peng, Hung Tran, Hung Le, Huy Hoang Nguyen

Auto-TLDR; Logographic DEComposition Encoding for Chinese and Japanese Text Line Recognition
Abstract Slides Poster Similar
Semantic Segmentation Refinement Using Entropy and Boundary-guided Monte Carlo Sampling and Directed Regional Search
Zitang Sun, Sei-Ichiro Kamata, Ruojing Wang, Weili Chen

Auto-TLDR; Directed Region Search and Refinement for Semantic Segmentation
Abstract Slides Poster Similar
Feature Embedding Based Text Instance Grouping for Largely Spaced and Occluded Text Detection
Pan Gao, Qi Wan, Renwu Gao, Linlin Shen

Auto-TLDR; Text Instance Embedding Based Feature Embeddings for Multiple Text Instance Grouping
Abstract Slides Poster Similar
Dual Encoder Fusion U-Net (DEFU-Net) for Cross-manufacturer Chest X-Ray Segmentation
Zhang Lipei, Aozhi Liu, Jing Xiao
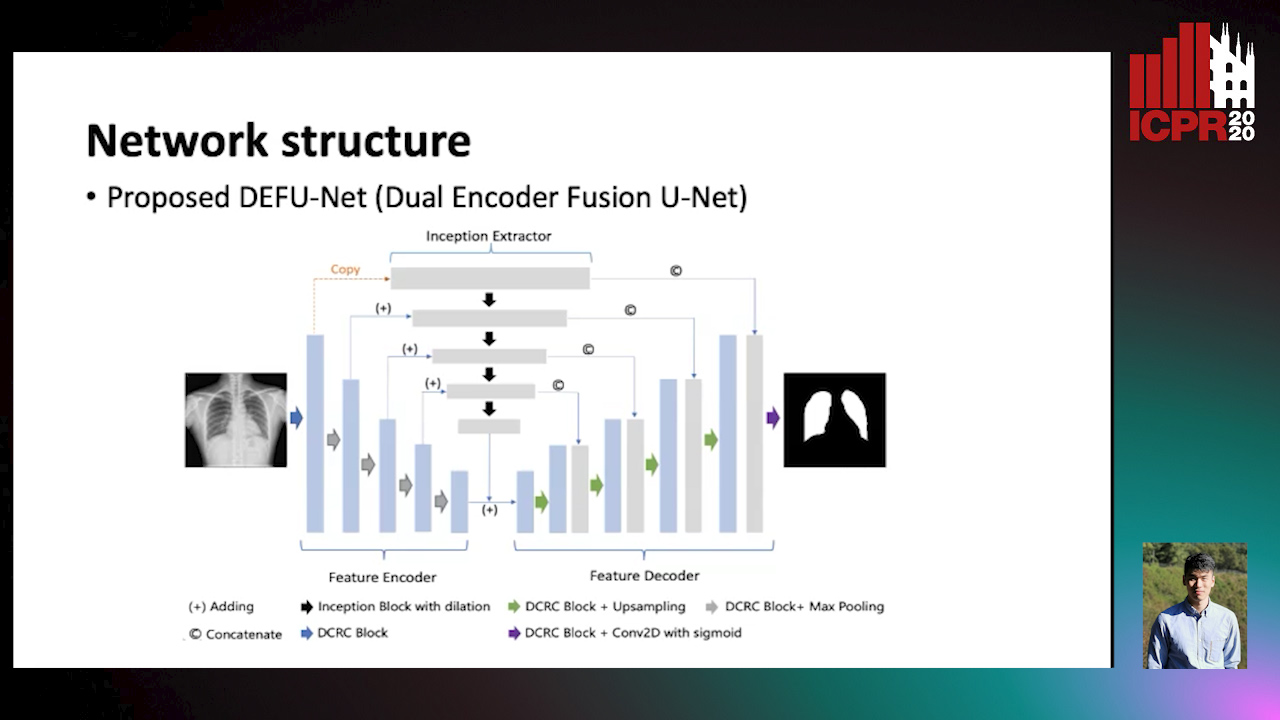
Auto-TLDR; Inception Convolutional Neural Network with Dilation for Chest X-Ray Segmentation
An Integrated Approach of Deep Learning and Symbolic Analysis for Digital PDF Table Extraction
Mengshi Zhang, Daniel Perelman, Vu Le, Sumit Gulwani

Auto-TLDR; Deep Learning and Symbolic Reasoning for Unstructured PDF Table Extraction
Abstract Slides Poster Similar
Triplet-Path Dilated Network for Detection and Segmentation of General Pathological Images
Jiaqi Luo, Zhicheng Zhao, Fei Su, Limei Guo

Auto-TLDR; Triplet-path Network for One-Stage Object Detection and Segmentation in Pathological Images
An Accurate Threshold Insensitive Kernel Detector for Arbitrary Shaped Text
Xijun Qian, Yifan Liu, Yu-Bin Yang

Auto-TLDR; TIKD: threshold insensitive kernel detector for arbitrary shaped text
Automatic Semantic Segmentation of Structural Elements related to the Spinal Cord in the Lumbar Region by Using Convolutional Neural Networks
Jhon Jairo Sáenz Gamboa, Maria De La Iglesia-Vaya, Jon Ander Gómez

Auto-TLDR; Semantic Segmentation of Lumbar Spine Using Convolutional Neural Networks
Abstract Slides Poster Similar
DE-Net: Dilated Encoder Network for Automated Tongue Segmentation
Hui Tang, Bin Wang, Jun Zhou, Yongsheng Gao

Auto-TLDR; Automated Tongue Image Segmentation using De-Net
Abstract Slides Poster Similar
Textual-Content Based Classification of Bundles of Untranscribed of Manuscript Images
José Ramón Prieto Fontcuberta, Enrique Vidal, Vicente Bosch, Carlos Alonso, Carmen Orcero, Lourdes Márquez

Auto-TLDR; Probabilistic Indexing for Text-based Classification of Manuscripts
Abstract Slides Poster Similar
Trainable Spectrally Initializable Matrix Transformations in Convolutional Neural Networks
Michele Alberti, Angela Botros, Schuetz Narayan, Rolf Ingold, Marcus Liwicki, Mathias Seuret

Auto-TLDR; Trainable and Spectrally Initializable Matrix Transformations for Neural Networks
Abstract Slides Poster Similar
KoreALBERT: Pretraining a Lite BERT Model for Korean Language Understanding
Hyunjae Lee, Jaewoong Yun, Bongkyu Hwang, Seongho Joe, Seungjai Min, Youngjune Gwon

Auto-TLDR; KoreALBERT: A monolingual ALBERT model for Korean language understanding
Abstract Slides Poster Similar
RescueNet: Joint Building Segmentation and Damage Assessment from Satellite Imagery

Auto-TLDR; RescueNet: End-to-End Building Segmentation and Damage Classification for Humanitarian Aid and Disaster Response
Abstract Slides Poster Similar
EdgeNet: Semantic Scene Completion from a Single RGB-D Image
Aloisio Dourado, Teofilo De Campos, Adrian Hilton, Hansung Kim

Auto-TLDR; Semantic Scene Completion using 3D Depth and RGB Information
Abstract Slides Poster Similar
ConvMath : A Convolutional Sequence Network for Mathematical Expression Recognition
Zuoyu Yan, Xiaode Zhang, Liangcai Gao, Ke Yuan, Zhi Tang

Auto-TLDR; Convolutional Sequence Modeling for Mathematical Expressions Recognition
Abstract Slides Poster Similar
Global-Local Attention Network for Semantic Segmentation in Aerial Images
Minglong Li, Lianlei Shan, Weiqiang Wang

Auto-TLDR; GLANet: Global-Local Attention Network for Semantic Segmentation
Abstract Slides Poster Similar
Handwritten Digit String Recognition Using Deep Autoencoder Based Segmentation and ResNet Based Recognition Approach
Anuran Chakraborty, Rajonya De, Samir Malakar, Friedhelm Schwenker, Ram Sarkar

Auto-TLDR; Handwritten Digit Strings Recognition Using Residual Network and Deep Autoencoder Based Segmentation
Abstract Slides Poster Similar
Online Trajectory Recovery from Offline Handwritten Japanese Kanji Characters of Multiple Strokes
Hung Tuan Nguyen, Tsubasa Nakamura, Cuong Tuan Nguyen, Masaki Nakagawa

Auto-TLDR; Recovering Dynamic Online Trajectories from Offline Japanese Kanji Character Images for Handwritten Character Recognition
Abstract Slides Poster Similar
Aerial Road Segmentation in the Presence of Topological Label Noise
Corentin Henry, Friedrich Fraundorfer, Eleonora Vig

Auto-TLDR; Improving Road Segmentation with Noise-Aware U-Nets for Fine-Grained Topology delineation
Abstract Slides Poster Similar
Robust Lexicon-Free Confidence Prediction for Text Recognition
Qi Song, Qianyi Jiang, Rui Zhang, Xiaolin Wei

Auto-TLDR; Confidence Measurement for Optical Character Recognition using Single-Input Multi-Output Network
Abstract Slides Poster Similar
Multi-Direction Convolution for Semantic Segmentation
Dehui Li, Zhiguo Cao, Ke Xian, Xinyuan Qi, Chao Zhang, Hao Lu

Auto-TLDR; Multi-Direction Convolution for Contextual Segmentation
ReADS: A Rectified Attentional Double Supervised Network for Scene Text Recognition
Qi Song, Qianyi Jiang, Xiaolin Wei, Nan Li, Rui Zhang

Auto-TLDR; ReADS: Rectified Attentional Double Supervised Network for General Scene Text Recognition
Abstract Slides Poster Similar
A Fast and Accurate Object Detector for Handwritten Digit String Recognition
Jun Guo, Wenjing Wei, Yifeng Ma, Cong Peng

Auto-TLDR; ChipNet: An anchor-free object detector for handwritten digit string recognition
Abstract Slides Poster Similar
Improving Word Recognition Using Multiple Hypotheses and Deep Embeddings
Siddhant Bansal, Praveen Krishnan, C. V. Jawahar

Auto-TLDR; EmbedNet: fuse recognition-based and recognition-free approaches for word recognition using learning-based methods
Abstract Slides Poster Similar
Documents Counterfeit Detection through a Deep Learning Approach
Darwin Danilo Saire Pilco, Salvatore Tabbone

Auto-TLDR; End-to-End Learning for Counterfeit Documents Detection using Deep Neural Network
Abstract Slides Poster Similar
DUET: Detection Utilizing Enhancement for Text in Scanned or Captured Documents
Eun-Soo Jung, Hyeonggwan Son, Kyusam Oh, Yongkeun Yun, Soonhwan Kwon, Min Soo Kim

Auto-TLDR; Text Detection for Document Images Using Synthetic and Real Data
Abstract Slides Poster Similar
Planar 3D Transfer Learning for End to End Unimodal MRI Unbalanced Data Segmentation
Martin Kolarik, Radim Burget, Carlos M. Travieso-Gonzalez, Jan Kocica

Auto-TLDR; Planar 3D Res-U-Net Network for Unbalanced 3D Image Segmentation using Fluid Attenuation Inversion Recover
Recursive Recognition of Offline Handwritten Mathematical Expressions
Marco Cotogni, Claudio Cusano, Antonino Nocera

Auto-TLDR; Online Handwritten Mathematical Expression Recognition with Recurrent Neural Network
Abstract Slides Poster Similar
Multiscale Attention-Based Prototypical Network for Few-Shot Semantic Segmentation
Yifei Zhang, Desire Sidibe, Olivier Morel, Fabrice Meriaudeau

Auto-TLDR; Few-shot Semantic Segmentation with Multiscale Feature Attention