Writer Identification Using Deep Neural Networks: Impact of Patch Size and Number of Patches
Akshay Punjabi,
José Ramón Prieto Fontcuberta,
Enrique Vidal

Auto-TLDR; Writer Recognition Using Deep Neural Networks for Handwritten Text Images
Similar papers
Watch Your Strokes: Improving Handwritten Text Recognition with Deformable Convolutions
Iulian Cojocaru, Silvia Cascianelli, Lorenzo Baraldi, Massimiliano Corsini, Rita Cucchiara

Auto-TLDR; Deformable Convolutional Neural Networks for Handwritten Text Recognition
Abstract Slides Poster Similar
Textual-Content Based Classification of Bundles of Untranscribed of Manuscript Images
José Ramón Prieto Fontcuberta, Enrique Vidal, Vicente Bosch, Carlos Alonso, Carmen Orcero, Lourdes Márquez

Auto-TLDR; Probabilistic Indexing for Text-based Classification of Manuscripts
Abstract Slides Poster Similar
The HisClima Database: Historical Weather Logs for Automatic Transcription and Information Extraction
Verónica Romero, Joan Andreu Sánchez

Auto-TLDR; Automatic Handwritten Text Recognition and Information Extraction from Historical Weather Logs
Abstract Slides Poster Similar
Recursive Recognition of Offline Handwritten Mathematical Expressions
Marco Cotogni, Claudio Cusano, Antonino Nocera

Auto-TLDR; Online Handwritten Mathematical Expression Recognition with Recurrent Neural Network
Abstract Slides Poster Similar
Unsupervised deep learning for text line segmentation
Berat Kurar Barakat, Ahmad Droby, Reem Alaasam, Borak Madi, Irina Rabaev, Raed Shammes, Jihad El-Sana

Auto-TLDR; Unsupervised Deep Learning for Handwritten Text Line Segmentation without Annotation
A Few-Shot Learning Approach for Historical Ciphered Manuscript Recognition
Mohamed Ali Souibgui, Alicia Fornés, Yousri Kessentini, Crina Tudor

Auto-TLDR; Handwritten Ciphers Recognition Using Few-Shot Object Detection
Text Baseline Recognition Using a Recurrent Convolutional Neural Network
Matthias Wödlinger, Robert Sablatnig

Auto-TLDR; Automatic Baseline Detection of Handwritten Text Using Recurrent Convolutional Neural Network
Abstract Slides Poster Similar
Ancient Document Layout Analysis: Autoencoders Meet Sparse Coding
Homa Davoudi, Marco Fiorucci, Arianna Traviglia

Auto-TLDR; Unsupervised Unsupervised Representation Learning for Document Layout Analysis
Abstract Slides Poster Similar
Multimodal Side-Tuning for Document Classification
Stefano Zingaro, Giuseppe Lisanti, Maurizio Gabbrielli

Auto-TLDR; Side-tuning for Multimodal Document Classification
Abstract Slides Poster Similar
Learning to Sort Handwritten Text Lines in Reading Order through Estimated Binary Order Relations

Auto-TLDR; Automatic Reading Order of Text Lines in Handwritten Text Documents
Learning Metric Features for Writer-Independent Signature Verification Using Dual Triplet Loss
Auto-TLDR; A dual triplet loss based method for offline writer-independent signature verification
Online Trajectory Recovery from Offline Handwritten Japanese Kanji Characters of Multiple Strokes
Hung Tuan Nguyen, Tsubasa Nakamura, Cuong Tuan Nguyen, Masaki Nakagawa

Auto-TLDR; Recovering Dynamic Online Trajectories from Offline Japanese Kanji Character Images for Handwritten Character Recognition
Abstract Slides Poster Similar
Vision-Based Layout Detection from Scientific Literature Using Recurrent Convolutional Neural Networks

Auto-TLDR; Transfer Learning for Scientific Literature Layout Detection Using Convolutional Neural Networks
Abstract Slides Poster Similar
Multiple Document Datasets Pre-Training Improves Text Line Detection with Deep Neural Networks
Mélodie Boillet, Christopher Kermorvant, Thierry Paquet

Auto-TLDR; A fully convolutional network for document layout analysis
Recognizing Bengali Word Images - A Zero-Shot Learning Perspective
Sukalpa Chanda, Daniël Arjen Willem Haitink, Prashant Kumar Prasad, Jochem Baas, Umapada Pal, Lambert Schomaker

Auto-TLDR; Zero-Shot Learning for Word Recognition in Bengali Script
Abstract Slides Poster Similar
LODENet: A Holistic Approach to Offline Handwritten Chinese and Japanese Text Line Recognition
Huu Tin Hoang, Chun-Jen Peng, Hung Tran, Hung Le, Huy Hoang Nguyen

Auto-TLDR; Logographic DEComposition Encoding for Chinese and Japanese Text Line Recognition
Abstract Slides Poster Similar
Cut and Compare: End-To-End Offline Signature Verification Network

Auto-TLDR; An End-to-End Cut-and-Compare Network for Offline Signature Verification
Abstract Slides Poster Similar
Improving Word Recognition Using Multiple Hypotheses and Deep Embeddings
Siddhant Bansal, Praveen Krishnan, C. V. Jawahar

Auto-TLDR; EmbedNet: fuse recognition-based and recognition-free approaches for word recognition using learning-based methods
Abstract Slides Poster Similar
Trainable Spectrally Initializable Matrix Transformations in Convolutional Neural Networks
Michele Alberti, Angela Botros, Schuetz Narayan, Rolf Ingold, Marcus Liwicki, Mathias Seuret

Auto-TLDR; Trainable and Spectrally Initializable Matrix Transformations for Neural Networks
Abstract Slides Poster Similar
Chebyshev-Harmonic-Fourier-Moments and Deep CNNs for Detecting Forged Handwriting
Lokesh Nandanwar, Shivakumara Palaiahnakote, Kundu Sayani, Umapada Pal, Tong Lu, Daniel Lopresti

Auto-TLDR; Chebyshev-Harmonic-Fourier-Moments and Deep Convolutional Neural Networks for forged handwriting detection
Abstract Slides Poster Similar
An Evaluation of DNN Architectures for Page Segmentation of Historical Newspapers
Manuel Burghardt, Bernhard Liebl

Auto-TLDR; Evaluation of Backbone Architectures for Optical Character Segmentation of Historical Documents
Abstract Slides Poster Similar
Fusion of Global-Local Features for Image Quality Inspection of Shipping Label
Sungho Suh, Paul Lukowicz, Yong Oh Lee

Auto-TLDR; Input Image Quality Verification for Automated Shipping Address Recognition and Verification
Abstract Slides Poster Similar
Documents Counterfeit Detection through a Deep Learning Approach
Darwin Danilo Saire Pilco, Salvatore Tabbone

Auto-TLDR; End-to-End Learning for Counterfeit Documents Detection using Deep Neural Network
Abstract Slides Poster Similar
Combining Deep and Ad-Hoc Solutions to Localize Text Lines in Ancient Arabic Document Images
Olfa Mechi, Maroua Mehri, Rolf Ingold, Najoua Essoukri Ben Amara

Auto-TLDR; Text Line Localization in Ancient Handwritten Arabic Document Images using U-Net and Topological Structural Analysis
Abstract Slides Poster Similar
An Investigation of Feature Selection and Transfer Learning for Writer-Independent Offline Handwritten Signature Verification
Victor Souza, Adriano Oliveira, Rafael Menelau Oliveira E Cruz, Robert Sabourin

Auto-TLDR; Overfitting of SigNet using Binary Particle Swarm Optimization
Abstract Slides Poster Similar
Deep Transfer Learning for Alzheimer’s Disease Detection
Nicole Cilia, Claudio De Stefano, Francesco Fontanella, Claudio Marrocco, Mario Molinara, Alessandra Scotto Di Freca

Auto-TLDR; Automatic Detection of Handwriting Alterations for Alzheimer's Disease Diagnosis using Dynamic Features
Abstract Slides Poster Similar
Multi-Task Learning Based Traditional Mongolian Words Recognition
Hongxi Wei, Hui Zhang, Jing Zhang, Kexin Liu

Auto-TLDR; Multi-task Learning for Mongolian Words Recognition
Abstract Slides Poster Similar
Enhancing Handwritten Text Recognition with N-Gram Sequencedecomposition and Multitask Learning
Vasiliki Tassopoulou, George Retsinas, Petros Maragos

Auto-TLDR; Multi-task Learning for Handwritten Text Recognition
Abstract Slides Poster Similar
Automated Whiteboard Lecture Video Summarization by Content Region Detection and Representation
Bhargava Urala Kota, Alexander Stone, Kenny Davila, Srirangaraj Setlur, Venu Govindaraju

Auto-TLDR; A Framework for Summarizing Whiteboard Lecture Videos Using Feature Representations of Handwritten Content Regions
Face Anti-Spoofing Using Spatial Pyramid Pooling
Lei Shi, Zhuo Zhou, Zhenhua Guo

Auto-TLDR; Spatial Pyramid Pooling for Face Anti-Spoofing
Abstract Slides Poster Similar
On-Device Text Image Super Resolution
Dhruval Jain, Arun Prabhu, Gopi Ramena, Manoj Goyal, Debi Mohanty, Naresh Purre, Sukumar Moharana

Auto-TLDR; A Novel Deep Neural Network for Super-Resolution on Low Resolution Text Images
Abstract Slides Poster Similar
A Gated and Bifurcated Stacked U-Net Module for Document Image Dewarping
Hmrishav Bandyopadhyay, Tanmoy Dasgupta, Nibaran Das, Mita Nasipuri

Auto-TLDR; Gated and Bifurcated Stacked U-Net for Dewarping Document Images
Abstract Slides Poster Similar
Named Entity Recognition and Relation Extraction with Graph Neural Networks in Semi Structured Documents
Manuel Carbonell, Pau Riba, Mauricio Villegas, Alicia Fornés, Josep Llados

Auto-TLDR; Graph Neural Network for Entity Recognition and Relation Extraction in Semi-Structured Documents
ID Documents Matching and Localization with Multi-Hypothesis Constraints
Guillaume Chiron, Nabil Ghanmi, Ahmad Montaser Awal

Auto-TLDR; Identity Document Localization in the Wild Using Multi-hypothesis Exploration
Abstract Slides Poster Similar
Handwritten Digit String Recognition Using Deep Autoencoder Based Segmentation and ResNet Based Recognition Approach
Anuran Chakraborty, Rajonya De, Samir Malakar, Friedhelm Schwenker, Ram Sarkar

Auto-TLDR; Handwritten Digit Strings Recognition Using Residual Network and Deep Autoencoder Based Segmentation
Abstract Slides Poster Similar
ReADS: A Rectified Attentional Double Supervised Network for Scene Text Recognition
Qi Song, Qianyi Jiang, Xiaolin Wei, Nan Li, Rui Zhang

Auto-TLDR; ReADS: Rectified Attentional Double Supervised Network for General Scene Text Recognition
Abstract Slides Poster Similar
Automatic Tuberculosis Detection Using Chest X-Ray Analysis with Position Enhanced Structural Information
Hermann Jepdjio Nkouanga, Szilard Vajda

Auto-TLDR; Automatic Chest X-ray Screening for Tuberculosis in Rural Population using Localized Region on Interest
Abstract Slides Poster Similar
Comparison of Deep Learning and Hand Crafted Features for Mining Simulation Data
Theodoros Georgiou, Sebastian Schmitt, Thomas Baeck, Nan Pu, Wei Chen, Michael Lew

Auto-TLDR; Automated Data Analysis of Flow Fields in Computational Fluid Dynamics Simulations
Abstract Slides Poster Similar
Cross-People Mobile-Phone Based Airwriting Character Recognition
Yunzhe Li, Hui Zheng, He Zhu, Haojun Ai, Xiaowei Dong

Auto-TLDR; Cross-People Airwriting Recognition via Motion Sensor Signal via Deep Neural Network
Abstract Slides Poster Similar
Local Gradient Difference Based Mass Features for Classification of 2D-3D Natural Scene Text Images
Lokesh Nandanwar, Shivakumara Palaiahnakote, Raghavendra Ramachandra, Tong Lu, Umapada Pal, Daniel Lopresti, Nor Badrul Anuar
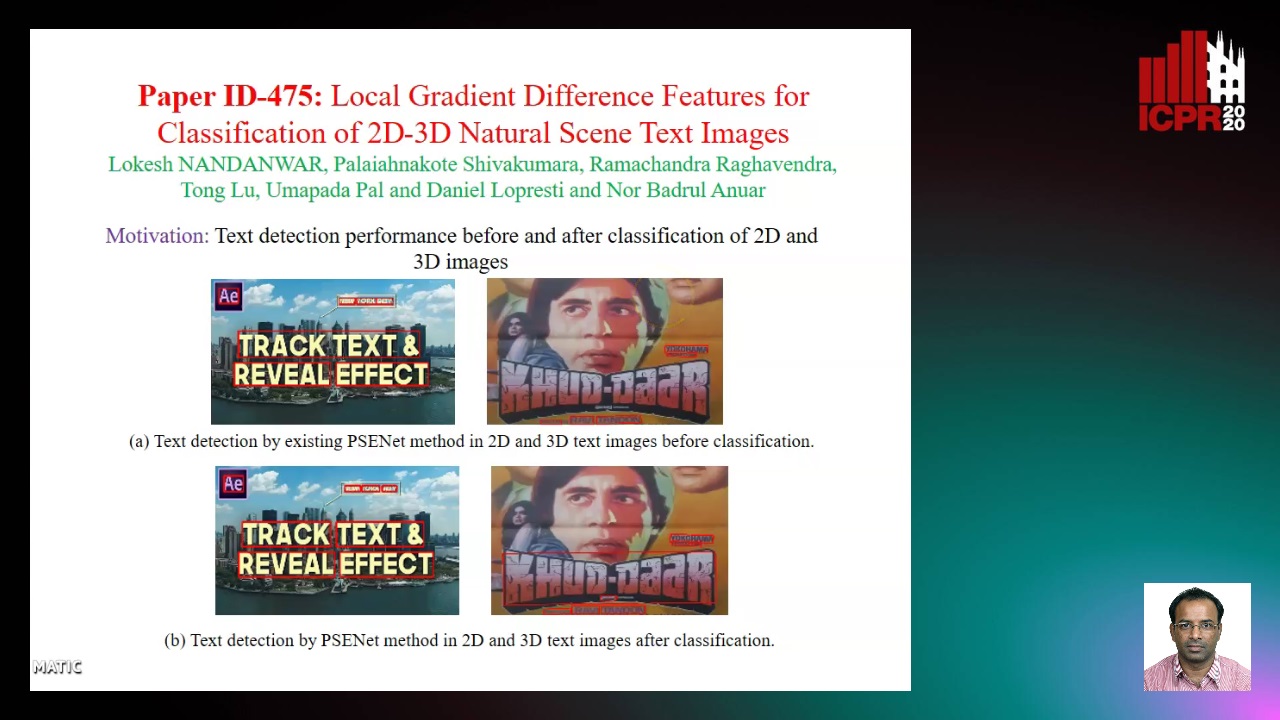
Auto-TLDR; Classification of 2D and 3D Natural Scene Images Using COLD
Abstract Slides Poster Similar
ConvMath : A Convolutional Sequence Network for Mathematical Expression Recognition
Zuoyu Yan, Xiaode Zhang, Liangcai Gao, Ke Yuan, Zhi Tang

Auto-TLDR; Convolutional Sequence Modeling for Mathematical Expressions Recognition
Abstract Slides Poster Similar
Feature Embedding Based Text Instance Grouping for Largely Spaced and Occluded Text Detection
Pan Gao, Qi Wan, Renwu Gao, Linlin Shen

Auto-TLDR; Text Instance Embedding Based Feature Embeddings for Multiple Text Instance Grouping
Abstract Slides Poster Similar
On Identification and Retrieval of Near-Duplicate Biological Images: A New Dataset and Protocol
Thomas E. Koker, Sai Spandana Chintapalli, San Wang, Blake A. Talbot, Daniel Wainstock, Marcelo Cicconet, Mary C. Walsh

Auto-TLDR; BINDER: Bio-Image Near-Duplicate Examples Repository for Image Identification and Retrieval
Approach for Document Detection by Contours and Contrasts
Daniil Tropin, Sergey Ilyuhin, Dmitry Nikolaev, Vladimir V. Arlazarov

Auto-TLDR; A countor-based method for arbitrary document detection on a mobile device
Abstract Slides Poster Similar
Image-Based Table Cell Detection: A New Dataset and an Improved Detection Method
Dafeng Wei, Hongtao Lu, Yi Zhou, Kai Chen

Auto-TLDR; TableCell: A Semi-supervised Dataset for Table-wise Detection and Recognition
Abstract Slides Poster Similar
Large-Scale Historical Watermark Recognition: Dataset and a New Consistency-Based Approach
Xi Shen, Ilaria Pastrolin, Oumayma Bounou, Spyros Gidaris, Marc Smith, Olivier Poncet, Mathieu Aubry

Auto-TLDR; Historical Watermark Recognition with Fine-Grained Cross-Domain One-Shot Instance Recognition
Abstract Slides Poster Similar
Generalized Iris Presentation Attack Detection Algorithm under Cross-Database Settings
Mehak Gupta, Vishal Singh, Akshay Agarwal, Mayank Vatsa, Richa Singh

Auto-TLDR; MVNet: A Deep Learning-based PAD Network for Iris Recognition against Presentation Attacks
Abstract Slides Poster Similar
UDBNET: Unsupervised Document Binarization Network Via Adversarial Game
Amandeep Kumar, Shuvozit Ghose, Pinaki Nath Chowdhury, Partha Pratim Roy, Umapada Pal

Auto-TLDR; Three-player Min-max Adversarial Game for Unsupervised Document Binarization
Abstract Slides Poster Similar