Fusion of Global-Local Features for Image Quality Inspection of Shipping Label
Sungho Suh,
Paul Lukowicz,
Yong Oh Lee

Auto-TLDR; Input Image Quality Verification for Automated Shipping Address Recognition and Verification
Similar papers
ACRM: Attention Cascade R-CNN with Mix-NMS for Metallic Surface Defect Detection
Junting Fang, Xiaoyang Tan, Yuhui Wang

Auto-TLDR; Attention Cascade R-CNN with Mix Non-Maximum Suppression for Robust Metal Defect Detection
Abstract Slides Poster Similar
Writer Identification Using Deep Neural Networks: Impact of Patch Size and Number of Patches
Akshay Punjabi, José Ramón Prieto Fontcuberta, Enrique Vidal

Auto-TLDR; Writer Recognition Using Deep Neural Networks for Handwritten Text Images
Abstract Slides Poster Similar
Scene Text Detection with Selected Anchors
Anna Zhu, Hang Du, Shengwu Xiong

Auto-TLDR; AS-RPN: Anchor Selection-based Region Proposal Network for Scene Text Detection
Abstract Slides Poster Similar
DUET: Detection Utilizing Enhancement for Text in Scanned or Captured Documents
Eun-Soo Jung, Hyeonggwan Son, Kyusam Oh, Yongkeun Yun, Soonhwan Kwon, Min Soo Kim

Auto-TLDR; Text Detection for Document Images Using Synthetic and Real Data
Abstract Slides Poster Similar
Mobile Phone Surface Defect Detection Based on Improved Faster R-CNN
Tao Wang, Can Zhang, Runwei Ding, Ge Yang

Auto-TLDR; Faster R-CNN for Mobile Phone Surface Defect Detection
Abstract Slides Poster Similar
Smart Inference for Multidigit Convolutional Neural Network Based Barcode Decoding
Duy-Thao Do, Tolcha Yalew, Tae Joon Jun, Daeyoung Kim

Auto-TLDR; Smart Inference for Barcode Decoding using Deep Convolutional Neural Network
Abstract Slides Poster Similar
2D License Plate Recognition based on Automatic Perspective Rectification
Hui Xu, Zhao-Hong Guo, Da-Han Wang, Xiang-Dong Zhou, Yu Shi

Auto-TLDR; Perspective Rectification Network for License Plate Recognition
Abstract Slides Poster Similar
Thermal Image Enhancement Using Generative Adversarial Network for Pedestrian Detection
Mohamed Amine Marnissi, Hajer Fradi, Anis Sahbani, Najoua Essoukri Ben Amara

Auto-TLDR; Improving Visual Quality of Infrared Images for Pedestrian Detection Using Generative Adversarial Network
Abstract Slides Poster Similar
Dynamic Low-Light Image Enhancement for Object Detection Via End-To-End Training
Haifeng Guo, Yirui Wu, Tong Lu

Auto-TLDR; Object Detection using Low-Light Image Enhancement for End-to-End Training
Abstract Slides Poster Similar
Stratified Multi-Task Learning for Robust Spotting of Scene Texts
Kinjal Dasgupta, Sudip Das, Ujjwal Bhattacharya

Auto-TLDR; Feature Representation Block for Multi-task Learning of Scene Text
Text Recognition - Real World Data and Where to Find Them
Klára Janoušková, Lluis Gomez, Dimosthenis Karatzas, Jiri Matas

Auto-TLDR; Exploiting Weakly Annotated Images for Text Extraction
Abstract Slides Poster Similar
A Fast and Accurate Object Detector for Handwritten Digit String Recognition
Jun Guo, Wenjing Wei, Yifeng Ma, Cong Peng

Auto-TLDR; ChipNet: An anchor-free object detector for handwritten digit string recognition
Abstract Slides Poster Similar
Feature Embedding Based Text Instance Grouping for Largely Spaced and Occluded Text Detection
Pan Gao, Qi Wan, Renwu Gao, Linlin Shen

Auto-TLDR; Text Instance Embedding Based Feature Embeddings for Multiple Text Instance Grouping
Abstract Slides Poster Similar
Local Attention and Global Representation Collaborating for Fine-Grained Classification
He Zhang, Yunming Bai, Hui Zhang, Jing Liu, Xingguang Li, Zhaofeng He

Auto-TLDR; Weighted Region Network for Cosmetic Contact Lenses Detection
Abstract Slides Poster Similar
End-To-End Deep Learning Methods for Automated Damage Detection in Extreme Events at Various Scales
Yongsheng Bai, Alper Yilmaz, Halil Sezen

Auto-TLDR; Robust Mask R-CNN for Crack Detection in Extreme Events
Abstract Slides Poster Similar
Vision-Based Layout Detection from Scientific Literature Using Recurrent Convolutional Neural Networks

Auto-TLDR; Transfer Learning for Scientific Literature Layout Detection Using Convolutional Neural Networks
Abstract Slides Poster Similar
IBN-STR: A Robust Text Recognizer for Irregular Text in Natural Scenes
Xiaoqian Li, Jie Liu, Shuwu Zhang

Auto-TLDR; IBN-STR: A Robust Text Recognition System Based on Data and Feature Representation
Construction Worker Hardhat-Wearing Detection Based on an Improved BiFPN
Chenyang Zhang, Zhiqiang Tian, Jingyi Song, Yaoyue Zheng, Bo Xu

Auto-TLDR; A One-Stage Object Detection Method for Hardhat-Wearing in Construction Site
Abstract Slides Poster Similar
UHRSNet: A Semantic Segmentation Network Specifically for Ultra-High-Resolution Images

Auto-TLDR; Ultra-High-Resolution Segmentation with Local and Global Feature Fusion
Recognizing Multiple Text Sequences from an Image by Pure End-To-End Learning
Zhenlong Xu, Shuigeng Zhou, Fan Bai, Cheng Zhanzhan, Yi Niu, Shiliang Pu

Auto-TLDR; Pure End-to-End Learning for Multiple Text Sequences Recognition from Images
Abstract Slides Poster Similar
ReADS: A Rectified Attentional Double Supervised Network for Scene Text Recognition
Qi Song, Qianyi Jiang, Xiaolin Wei, Nan Li, Rui Zhang

Auto-TLDR; ReADS: Rectified Attentional Double Supervised Network for General Scene Text Recognition
Abstract Slides Poster Similar
TGCRBNW: A Dataset for Runner Bib Number Detection (and Recognition) in the Wild
Pablo Hernández-Carrascosa, Adrian Penate-Sanchez, Javier Lorenzo, David Freire Obregón, Modesto Castrillon

Auto-TLDR; Racing Bib Number Detection and Recognition in the Wild Using Faster R-CNN
Abstract Slides Poster Similar
Transferable Adversarial Attacks for Deep Scene Text Detection
Shudeng Wu, Tao Dai, Guanghao Meng, Bin Chen, Jian Lu, Shutao Xia

Auto-TLDR; Robustness of DNN-based STD methods against Adversarial Attacks
Face Anti-Spoofing Using Spatial Pyramid Pooling
Lei Shi, Zhuo Zhou, Zhenhua Guo

Auto-TLDR; Spatial Pyramid Pooling for Face Anti-Spoofing
Abstract Slides Poster Similar
Documents Counterfeit Detection through a Deep Learning Approach
Darwin Danilo Saire Pilco, Salvatore Tabbone

Auto-TLDR; End-to-End Learning for Counterfeit Documents Detection using Deep Neural Network
Abstract Slides Poster Similar
Dual Path Multi-Modal High-Order Features for Textual Content Based Visual Question Answering
Yanan Li, Yuetan Lin, Hongrui Zhao, Donghui Wang

Auto-TLDR; TextVQA: An End-to-End Visual Question Answering Model for Text-Based VQA
Dual Stream Network with Selective Optimization for Skin Disease Recognition in Consumer Grade Images
Krishnam Gupta, Jaiprasad Rampure, Monu Krishnan, Ajit Narayanan, Nikhil Narayan

Auto-TLDR; A Deep Network Architecture for Skin Disease Localisation and Classification on Consumer Grade Images
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
Cascade Saliency Attention Network for Object Detection in Remote Sensing Images
Dayang Yu, Rong Zhang, Shan Qin

Auto-TLDR; Cascade Saliency Attention Network for Object Detection in Remote Sensing Images
Abstract Slides Poster Similar
EDD-Net: An Efficient Defect Detection Network
Tianyu Guo, Linlin Zhang, Runwei Ding, Ge Yang

Auto-TLDR; EfficientNet: Efficient Network for Mobile Phone Surface defect Detection
Abstract Slides Poster Similar
Local Gradient Difference Based Mass Features for Classification of 2D-3D Natural Scene Text Images
Lokesh Nandanwar, Shivakumara Palaiahnakote, Raghavendra Ramachandra, Tong Lu, Umapada Pal, Daniel Lopresti, Nor Badrul Anuar
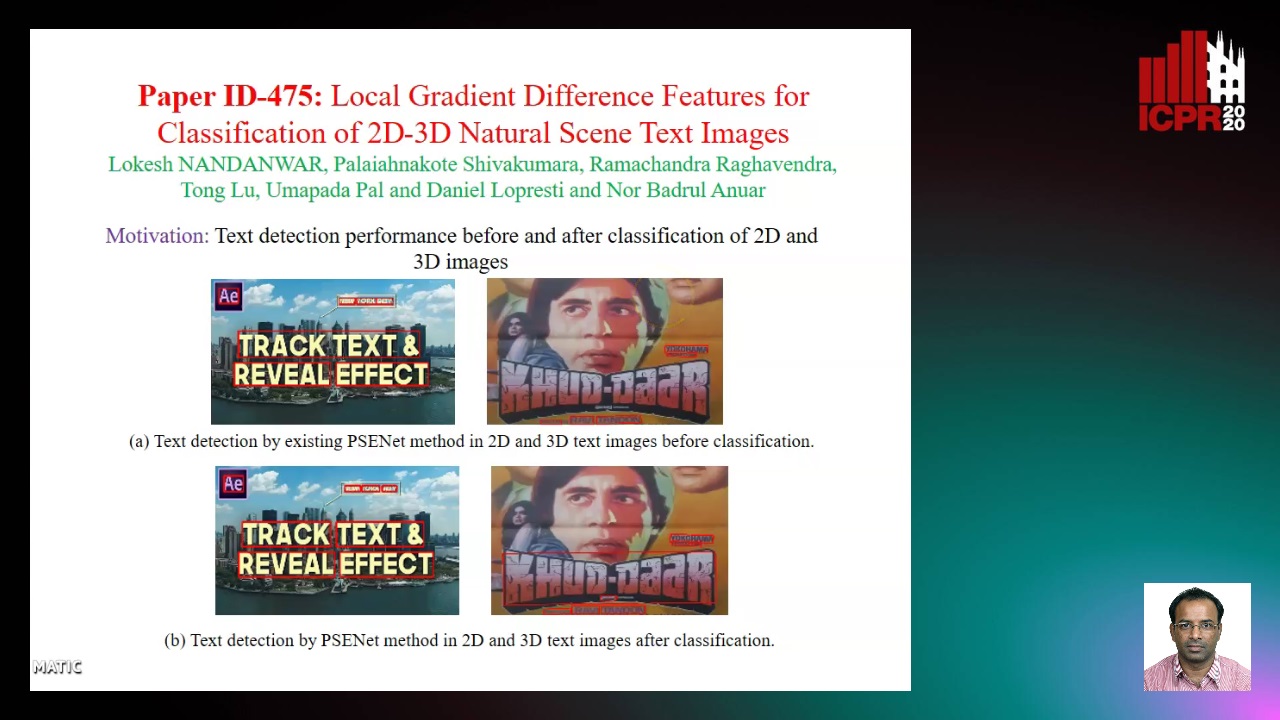
Auto-TLDR; Classification of 2D and 3D Natural Scene Images Using COLD
Abstract Slides Poster Similar
Approach for Document Detection by Contours and Contrasts
Daniil Tropin, Sergey Ilyuhin, Dmitry Nikolaev, Vladimir V. Arlazarov

Auto-TLDR; A countor-based method for arbitrary document detection on a mobile device
Abstract Slides Poster Similar
Gaussian Constrained Attention Network for Scene Text Recognition
Zhi Qiao, Xugong Qin, Yu Zhou, Fei Yang, Weiping Wang

Auto-TLDR; Gaussian Constrained Attention Network for Scene Text Recognition
Abstract Slides Poster Similar
On-Device Text Image Super Resolution
Dhruval Jain, Arun Prabhu, Gopi Ramena, Manoj Goyal, Debi Mohanty, Naresh Purre, Sukumar Moharana

Auto-TLDR; A Novel Deep Neural Network for Super-Resolution on Low Resolution Text Images
Abstract Slides Poster Similar
An Accurate Threshold Insensitive Kernel Detector for Arbitrary Shaped Text
Xijun Qian, Yifan Liu, Yu-Bin Yang

Auto-TLDR; TIKD: threshold insensitive kernel detector for arbitrary shaped text
Detecting Objects with High Object Region Percentage
Fen Fang, Qianli Xu, Liyuan Li, Ying Gu, Joo-Hwee Lim

Auto-TLDR; Faster R-CNN for High-ORP Object Detection
Abstract Slides Poster Similar
A Multi-Head Self-Relation Network for Scene Text Recognition
Zhou Junwei, Hongchao Gao, Jiao Dai, Dongqin Liu, Jizhong Han

Auto-TLDR; Multi-head Self-relation Network for Scene Text Recognition
Abstract Slides Poster Similar
TCATD: Text Contour Attention for Scene Text Detection
Ziling Hu, Wu Xingjiao, Jing Yang

Auto-TLDR; Text Contour Attention Text Detector
Abstract Slides Poster Similar
ID Documents Matching and Localization with Multi-Hypothesis Constraints
Guillaume Chiron, Nabil Ghanmi, Ahmad Montaser Awal

Auto-TLDR; Identity Document Localization in the Wild Using Multi-hypothesis Exploration
Abstract Slides Poster Similar
Weakly Supervised Attention Rectification for Scene Text Recognition
Chengyu Gu, Shilin Wang, Yiwei Zhu, Zheng Huang, Kai Chen

Auto-TLDR; An auxiliary supervision branch for attention-based scene text recognition
Abstract Slides Poster Similar
Object Detection Model Based on Scene-Level Region Proposal Self-Attention
Yu Quan, Zhixin Li, Canlong Zhang, Huifang Ma

Auto-TLDR; Exploiting Semantic Informations for Object Detection
Abstract Slides Poster Similar
Super-Resolution Guided Pore Detection for Fingerprint Recognition
Syeda Nyma Ferdous, Ali Dabouei, Jeremy Dawson, Nasser M. Nasarabadi

Auto-TLDR; Super-Resolution Generative Adversarial Network for Fingerprint Recognition Using Pore Features
Abstract Slides Poster Similar
Watch Your Strokes: Improving Handwritten Text Recognition with Deformable Convolutions
Iulian Cojocaru, Silvia Cascianelli, Lorenzo Baraldi, Massimiliano Corsini, Rita Cucchiara

Auto-TLDR; Deformable Convolutional Neural Networks for Handwritten Text Recognition
Abstract Slides Poster Similar
A Versatile Crack Inspection Portable System Based on Classifier Ensemble and Controlled Illumination
Milind Gajanan Padalkar, Carlos Beltran-Gonzalez, Matteo Bustreo, Alessio Del Bue, Vittorio Murino

Auto-TLDR; Lighting Conditions for Crack Detection in Ceramic Tile
Abstract Slides Poster Similar
Yolo+FPN: 2D and 3D Fused Object Detection with an RGB-D Camera

Auto-TLDR; Yolo+FPN: Combining 2D and 3D Object Detection for Real-Time Object Detection
Abstract Slides Poster Similar
Which Airline Is This? Airline Logo Detection in Real-World Weather Conditions
Christian Wilms, Rafael Heid, Mohammad Araf Sadeghi, Andreas Ribbrock, Simone Frintrop

Auto-TLDR; Airlines logo detection on airplane tails using data augmentation
Abstract Slides Poster Similar
Inception Based Deep Learning Architecture for Tuberculosis Screening of Chest X-Rays
Dipayan Das, K.C. Santosh, Umapada Pal

Auto-TLDR; End to End CNN-based Chest X-ray Screening for Tuberculosis positive patients in the severely resource constrained regions of the world
Abstract Slides Poster Similar
Pose-Aware Multi-Feature Fusion Network for Driver Distraction Recognition
Mingyan Wu, Xi Zhang, Linlin Shen, Hang Yu

Auto-TLDR; Multi-Feature Fusion Network for Distracted Driving Detection using Pose Estimation
Abstract Slides Poster Similar