Inception Based Deep Learning Architecture for Tuberculosis Screening of Chest X-Rays
Dipayan Das,
K.C. Santosh,
Umapada Pal

Auto-TLDR; End to End CNN-based Chest X-ray Screening for Tuberculosis positive patients in the severely resource constrained regions of the world
Similar papers
Automatic Tuberculosis Detection Using Chest X-Ray Analysis with Position Enhanced Structural Information
Hermann Jepdjio Nkouanga, Szilard Vajda

Auto-TLDR; Automatic Chest X-ray Screening for Tuberculosis in Rural Population using Localized Region on Interest
Abstract Slides Poster Similar
Dealing with Scarce Labelled Data: Semi-Supervised Deep Learning with Mix Match for Covid-19 Detection Using Chest X-Ray Images
Saúl Calderón Ramirez, Raghvendra Giri, Shengxiang Yang, Armaghan Moemeni, Mario Umaña, David Elizondo, Jordina Torrents-Barrena, Miguel A. Molina-Cabello

Auto-TLDR; Semi-supervised Deep Learning for Covid-19 Detection using Chest X-rays
Abstract Slides Poster Similar
Unsupervised Detection of Pulmonary Opacities for Computer-Aided Diagnosis of COVID-19 on CT Images
Rui Xu, Xiao Cao, Yufeng Wang, Yen-Wei Chen, Xinchen Ye, Lin Lin, Wenchao Zhu, Chao Chen, Fangyi Xu, Yong Zhou, Hongjie Hu, Shoji Kido, Noriyuki Tomiyama

Auto-TLDR; A computer-aided diagnosis of COVID-19 from CT images using unsupervised pulmonary opacity detection
Abstract Slides Poster Similar
Fine-Tuning Convolutional Neural Networks: A Comprehensive Guide and Benchmark Analysis for Glaucoma Screening
Amed Mvoulana, Rostom Kachouri, Mohamed Akil

Auto-TLDR; Fine-tuning Convolutional Neural Networks for Glaucoma Screening
Abstract Slides Poster Similar
Dual Encoder Fusion U-Net (DEFU-Net) for Cross-manufacturer Chest X-Ray Segmentation
Zhang Lipei, Aozhi Liu, Jing Xiao
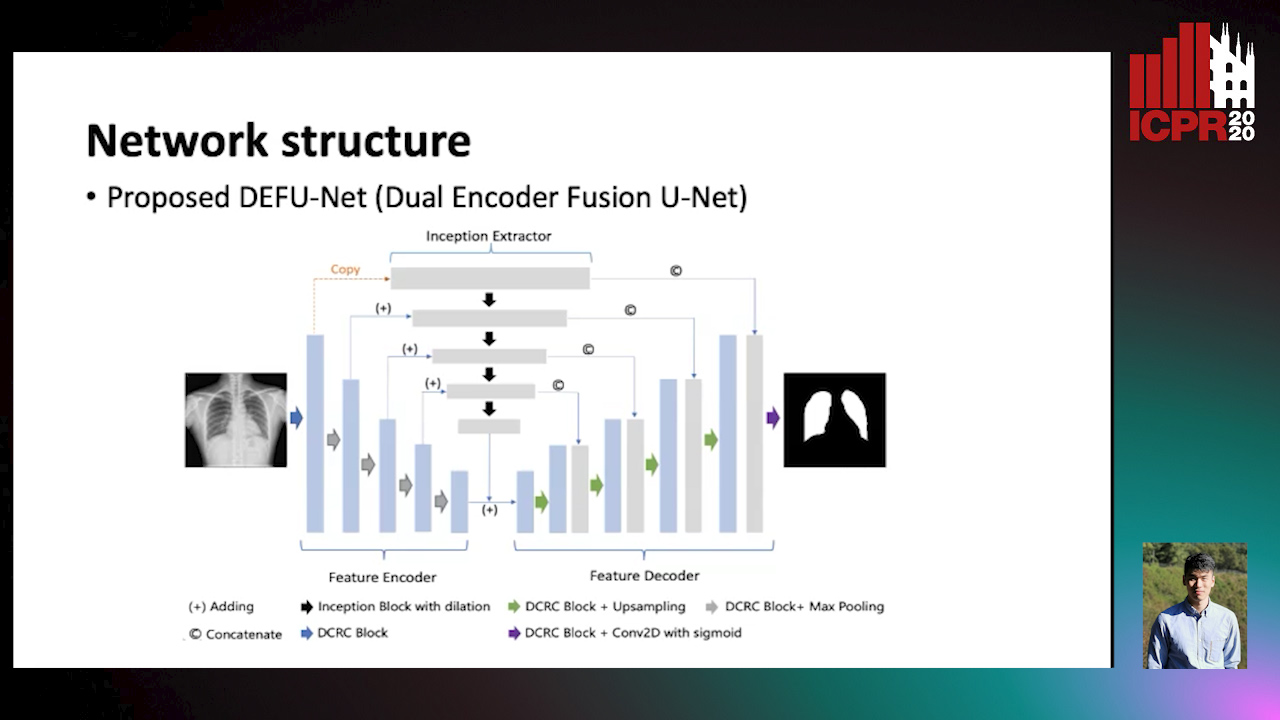
Auto-TLDR; Inception Convolutional Neural Network with Dilation for Chest X-Ray Segmentation
Documents Counterfeit Detection through a Deep Learning Approach
Darwin Danilo Saire Pilco, Salvatore Tabbone

Auto-TLDR; End-to-End Learning for Counterfeit Documents Detection using Deep Neural Network
Abstract Slides Poster Similar
A Comparison of Neural Network Approaches for Melanoma Classification
Maria Frasca, Michele Nappi, Michele Risi, Genoveffa Tortora, Alessia Auriemma Citarella

Auto-TLDR; Classification of Melanoma Using Deep Neural Network Methodologies
Abstract Slides Poster Similar
Influence of Event Duration on Automatic Wheeze Classification
Bruno M Rocha, Diogo Pessoa, Alda Marques, Paulo Carvalho, Rui Pedro Paiva

Auto-TLDR; Experimental Design of the Non-wheeze Class for Wheeze Classification
Abstract Slides Poster Similar
Bridging the Gap between Natural and Medical Images through Deep Colorization
Lia Morra, Luca Piano, Fabrizio Lamberti, Tatiana Tommasi

Auto-TLDR; Transfer Learning for Diagnosis on X-ray Images Using Color Adaptation
Abstract Slides Poster Similar
A Systematic Investigation on Deep Architectures for Automatic Skin Lesions Classification
Pierluigi Carcagni, Marco Leo, Andrea Cuna, Giuseppe Celeste, Cosimo Distante

Auto-TLDR; RegNet: Deep Investigation of Convolutional Neural Networks for Automatic Classification of Skin Lesions
Abstract Slides Poster Similar
Multi-Scale and Attention Based ResNet for Heartbeat Classification
Haojie Zhang, Gongping Yang, Yuwen Huang, Feng Yuan, Yilong Yin

Auto-TLDR; A Multi-Scale and Attention based ResNet for ECG heartbeat classification in intra-patient and inter-patient paradigms
Abstract Slides Poster Similar
Robust Localization of Retinal Lesions Via Weakly-Supervised Learning

Auto-TLDR; Weakly Learning of Lesions in Fundus Images Using Multi-level Feature Maps and Classification Score
Abstract Slides Poster Similar
Prediction of Obstructive Coronary Artery Disease from Myocardial Perfusion Scintigraphy using Deep Neural Networks
Ida Arvidsson, Niels Christian Overgaard, Miguel Ochoa Figueroa, Jeronimo Rose, Anette Davidsson, Kalle Åström, Anders Heyden

Auto-TLDR; A Deep Learning Algorithm for Multi-label Classification of Myocardial Perfusion Scintigraphy for Stable Ischemic Heart Disease
Abstract Slides Poster Similar
Dual Stream Network with Selective Optimization for Skin Disease Recognition in Consumer Grade Images
Krishnam Gupta, Jaiprasad Rampure, Monu Krishnan, Ajit Narayanan, Nikhil Narayan

Auto-TLDR; A Deep Network Architecture for Skin Disease Localisation and Classification on Consumer Grade Images
Abstract Slides Poster Similar
A Lumen Segmentation Method in Ureteroscopy Images Based on a Deep Residual U-Net Architecture
Jorge Lazo, Marzullo Aldo, Sara Moccia, Michele Catellani, Benoit Rosa, Elena De Momi, Michel De Mathelin, Francesco Calimeri

Auto-TLDR; A Deep Neural Network for Ureteroscopy with Residual Units
Abstract Slides Poster Similar
Automatic Semantic Segmentation of Structural Elements related to the Spinal Cord in the Lumbar Region by Using Convolutional Neural Networks
Jhon Jairo Sáenz Gamboa, Maria De La Iglesia-Vaya, Jon Ander Gómez

Auto-TLDR; Semantic Segmentation of Lumbar Spine Using Convolutional Neural Networks
Abstract Slides Poster Similar
MTGAN: Mask and Texture-Driven Generative Adversarial Network for Lung Nodule Segmentation
Wei Chen, Qiuli Wang, Kun Wang, Dan Yang, Xiaohong Zhang, Chen Liu, Yucong Li

Auto-TLDR; Mask and Texture-driven Generative Adversarial Network for Lung Nodule Segmentation
Abstract Slides Poster Similar
Deep Transfer Learning for Alzheimer’s Disease Detection
Nicole Cilia, Claudio De Stefano, Francesco Fontanella, Claudio Marrocco, Mario Molinara, Alessandra Scotto Di Freca

Auto-TLDR; Automatic Detection of Handwriting Alterations for Alzheimer's Disease Diagnosis using Dynamic Features
Abstract Slides Poster Similar
Using Machine Learning to Refer Patients with Chronic Kidney Disease to Secondary Care
Lee Au-Yeung, Xianghua Xie, Timothy Marcus Scale, James Anthony Chess

Auto-TLDR; A Machine Learning Approach for Chronic Kidney Disease Prediction using Blood Test Data
Abstract Slides Poster Similar
End-To-End Training of a Two-Stage Neural Network for Defect Detection
Jakob Božič, Domen Tabernik, Danijel Skocaj

Auto-TLDR; End-to-End Training of Segmentation-based Neural Network for Surface Defect Detection
Abstract Slides Poster Similar
End-To-End Multi-Task Learning for Lung Nodule Segmentation and Diagnosis
Wei Chen, Qiuli Wang, Dan Yang, Xiaohong Zhang, Chen Liu, Yucong Li

Auto-TLDR; A novel multi-task framework for lung nodule diagnosis based on deep learning and medical features
Planar 3D Transfer Learning for End to End Unimodal MRI Unbalanced Data Segmentation
Martin Kolarik, Radim Burget, Carlos M. Travieso-Gonzalez, Jan Kocica

Auto-TLDR; Planar 3D Res-U-Net Network for Unbalanced 3D Image Segmentation using Fluid Attenuation Inversion Recover
A Deep Learning Approach for the Segmentation of Myocardial Diseases
Khawala Brahim, Abdull Qayyum, Alain Lalande, Arnaud Boucher, Anis Sakly, Fabrice Meriaudeau

Auto-TLDR; Segmentation of Myocardium Infarction Using Late GADEMRI and SegU-Net
Abstract Slides Poster Similar
Investigating and Exploiting Image Resolution for Transfer Learning-Based Skin Lesion Classification
Amirreza Mahbod, Gerald Schaefer, Chunliang Wang, Rupert Ecker, Georg Dorffner, Isabella Ellinger

Auto-TLDR; Fine-tuned Neural Networks for Skin Lesion Classification Using Dermoscopic Images
Abstract Slides Poster Similar
A Benchmark Dataset for Segmenting Liver, Vasculature and Lesions from Large-Scale Computed Tomography Data
Bo Wang, Zhengqing Xu, Wei Xu, Qingsen Yan, Liang Zhang, Zheng You

Auto-TLDR; The Biggest Treatment-Oriented Liver Cancer Dataset for Segmentation
Abstract Slides Poster Similar
Explainable Feature Embedding Using Convolutional Neural Networks for Pathological Image Analysis
Kazuki Uehara, Masahiro Murakawa, Hirokazu Nosato, Hidenori Sakanashi

Auto-TLDR; Explainable Diagnosis Using Convolutional Neural Networks for Pathological Image Analysis
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
BG-Net: Boundary-Guided Network for Lung Segmentation on Clinical CT Images
Rui Xu, Yi Wang, Tiantian Liu, Xinchen Ye, Lin Lin, Yen-Wei Chen, Shoji Kido, Noriyuki Tomiyama

Auto-TLDR; Boundary-Guided Network for Lung Segmentation on CT Images
Abstract Slides Poster Similar
Deep Learning in the Ultrasound Evaluation of Neonatal Respiratory Status
Michela Gravina, Diego Gragnaniello, Giovanni Poggi, Luisa Verdoliva, Carlo Sansone, Iuri Corsini, Carlo Dani, Fabio Meneghin, Gianluca Lista, Salvatore Aversa, Migliaro Migliaro, Raimondi Francesco

Auto-TLDR; Lung Ultrasound Imaging with Deep Learning Networks and Training Strategies: An Analysis and Adaptation
Abstract Slides Poster Similar
Confidence Calibration for Deep Renal Biopsy Immunofluorescence Image Classification
Federico Pollastri, Juan Maroñas, Federico Bolelli, Giulia Ligabue, Roberto Paredes, Riccardo Magistroni, Costantino Grana

Auto-TLDR; A Probabilistic Convolutional Neural Network for Immunofluorescence Classification in Renal Biopsy
Abstract Slides Poster Similar
BAT Optimized CNN Model Identifies Water Stress in Chickpea Plant Shoot Images
Shiva Azimi, Taranjit Kaur, Tapan Gandhi

Auto-TLDR; BAT Optimized ResNet-18 for Stress Classification of chickpea shoot images under water deficiency
Abstract Slides Poster Similar
AdaFilter: Adaptive Filter Design with Local Image Basis Decomposition for Optimizing Image Recognition Preprocessing
Aiga Suzuki, Keiichi Ito, Takahide Ibe, Nobuyuki Otsu

Auto-TLDR; Optimal Preprocessing Filtering for Pattern Recognition Using Higher-Order Local Auto-Correlation
Abstract Slides Poster Similar
BiLuNet: A Multi-Path Network for Semantic Segmentation on X-Ray Images
Van Luan Tran, Huei-Yung Lin, Rachel Liu, Chun-Han Tseng, Chun-Han Tseng

Auto-TLDR; BiLuNet: Multi-path Convolutional Neural Network for Semantic Segmentation of Lumbar vertebrae, sacrum,
Merged 1D-2D Deep Convolutional Neural Networks for Nerve Detection in Ultrasound Images
Mohammad Alkhatib, Adel Hafiane, Pierre Vieyres

Auto-TLDR; A Deep Neural Network for Deep Neural Networks to Detect Median Nerve in Ultrasound-Guided Regional Anesthesia
Abstract Slides Poster Similar
On Identification and Retrieval of Near-Duplicate Biological Images: A New Dataset and Protocol
Thomas E. Koker, Sai Spandana Chintapalli, San Wang, Blake A. Talbot, Daniel Wainstock, Marcelo Cicconet, Mary C. Walsh

Auto-TLDR; BINDER: Bio-Image Near-Duplicate Examples Repository for Image Identification and Retrieval
Segmentation of Intracranial Aneurysm Remnant in MRA Using Dual-Attention Atrous Net
Subhashis Banerjee, Ashis Kumar Dhara, Johan Wikström, Robin Strand

Auto-TLDR; Dual-Attention Atrous Net for Segmentation of Intracranial Aneurysm Remnant from MRA Images
Abstract Slides Poster Similar
Supporting Skin Lesion Diagnosis with Content-Based Image Retrieval
Stefano Allegretti, Federico Bolelli, Federico Pollastri, Sabrina Longhitano, Giovanni Pellacani, Costantino Grana

Auto-TLDR; Skin Images Retrieval Using Convolutional Neural Networks for Skin Lesion Classification and Segmentation
Abstract Slides Poster Similar
Automatic Classification of Human Granulosa Cells in Assisted Reproductive Technology Using Vibrational Spectroscopy Imaging
Marina Paolanti, Emanuele Frontoni, Giorgia Gioacchini, Giorgini Elisabetta, Notarstefano Valentina, Zacà Carlotta, Carnevali Oliana, Andrea Borini, Marco Mameli

Auto-TLDR; Predicting Oocyte Quality in Assisted Reproductive Technology Using Machine Learning Techniques
Abstract Slides Poster Similar
PCANet: Pyramid Context-Aware Network for Retinal Vessel Segmentation
Yi Zhang, Yixuan Chen, Kai Zhang

Auto-TLDR; PCANet: Adaptive Context-Aware Network for Automated Retinal Vessel Segmentation
Abstract Slides Poster Similar
A Novel Computer-Aided Diagnostic System for Early Assessment of Hepatocellular Carcinoma
Ahmed Alksas, Mohamed Shehata, Gehad Saleh, Ahmed Shaffie, Ahmed Soliman, Mohammed Ghazal, Hadil Abukhalifeh, Abdel Razek Ahmed, Ayman El-Baz

Auto-TLDR; Classification of Liver Tumor Lesions from CE-MRI Using Structured Structural Features and Functional Features
Abstract Slides Poster Similar
Deep Multiple Instance Learning with Spatial Attention for ROP Case Classification, Instance Selection and Abnormality Localization
Xirong Li, Wencui Wan, Yang Zhou, Jianchun Zhao, Qijie Wei, Junbo Rong, Pengyi Zhou, Limin Xu, Lijuan Lang, Yuying Liu, Chengzhi Niu, Dayong Ding, Xuemin Jin

Auto-TLDR; MIL-SA: Deep Multiple Instance Learning for Automated Screening of Retinopathy of Prematurity
EM-Net: Deep Learning for Electron Microscopy Image Segmentation
Afshin Khadangi, Thomas Boudier, Vijay Rajagopal

Auto-TLDR; EM-net: Deep Convolutional Neural Network for Electron Microscopy Image Segmentation
Skin Lesion Classification Using Weakly-Supervised Fine-Grained Method
Xi Xue, Sei-Ichiro Kamata, Daming Luo

Auto-TLDR; Different Region proposal module for skin lesion classification
Abstract Slides Poster Similar
Epileptic Seizure Prediction: A Semi-Dilated Convolutional Neural Network Architecture
Ramy Hussein, Rabab K. Ward, Soojin Lee, Martin Mckeown

Auto-TLDR; Semi-Dilated Convolutional Network for Seizure Prediction using EEG Scalograms
Evaluation of Anomaly Detection Algorithms for the Real-World Applications
Marija Ivanovska, Domen Tabernik, Danijel Skocaj, Janez Pers

Auto-TLDR; Evaluating Anomaly Detection Algorithms for Practical Applications
Abstract Slides Poster Similar
DE-Net: Dilated Encoder Network for Automated Tongue Segmentation
Hui Tang, Bin Wang, Jun Zhou, Yongsheng Gao

Auto-TLDR; Automated Tongue Image Segmentation using De-Net
Abstract Slides Poster Similar
Fusion of Global-Local Features for Image Quality Inspection of Shipping Label
Sungho Suh, Paul Lukowicz, Yong Oh Lee

Auto-TLDR; Input Image Quality Verification for Automated Shipping Address Recognition and Verification
Abstract Slides Poster Similar
Generalized Iris Presentation Attack Detection Algorithm under Cross-Database Settings
Mehak Gupta, Vishal Singh, Akshay Agarwal, Mayank Vatsa, Richa Singh

Auto-TLDR; MVNet: A Deep Learning-based PAD Network for Iris Recognition against Presentation Attacks
Abstract Slides Poster Similar