PA-FlowNet: Pose-Auxiliary Optical Flow Network for Spacecraft Relative Pose Estimation
Zhi Yu Chen,
Po-Heng Chen,
Kuan-Wen Chen,
Chen-Yu Chan

Auto-TLDR; PA-FlowNet: An End-to-End Pose-auxiliary Optical Flow Network for Space Travel and Landing
Similar papers
HMFlow: Hybrid Matching Optical Flow Network for Small and Fast-Moving Objects
Suihanjin Yu, Youmin Zhang, Chen Wang, Xiao Bai, Liang Zhang, Edwin Hancock

Auto-TLDR; Hybrid Matching Optical Flow Network with Global Matching Component
Abstract Slides Poster Similar
OmniFlowNet: A Perspective Neural Network Adaptation for Optical Flow Estimation in Omnidirectional Images
Charles-Olivier Artizzu, Haozhou Zhang, Guillaume Allibert, Cédric Demonceaux

Auto-TLDR; OmniFlowNet: A Convolutional Neural Network for Omnidirectional Optical Flow Estimation
Abstract Slides Poster Similar
Revisiting Optical Flow Estimation in 360 Videos
Keshav Bhandari, Ziliang Zong, Yan Yan
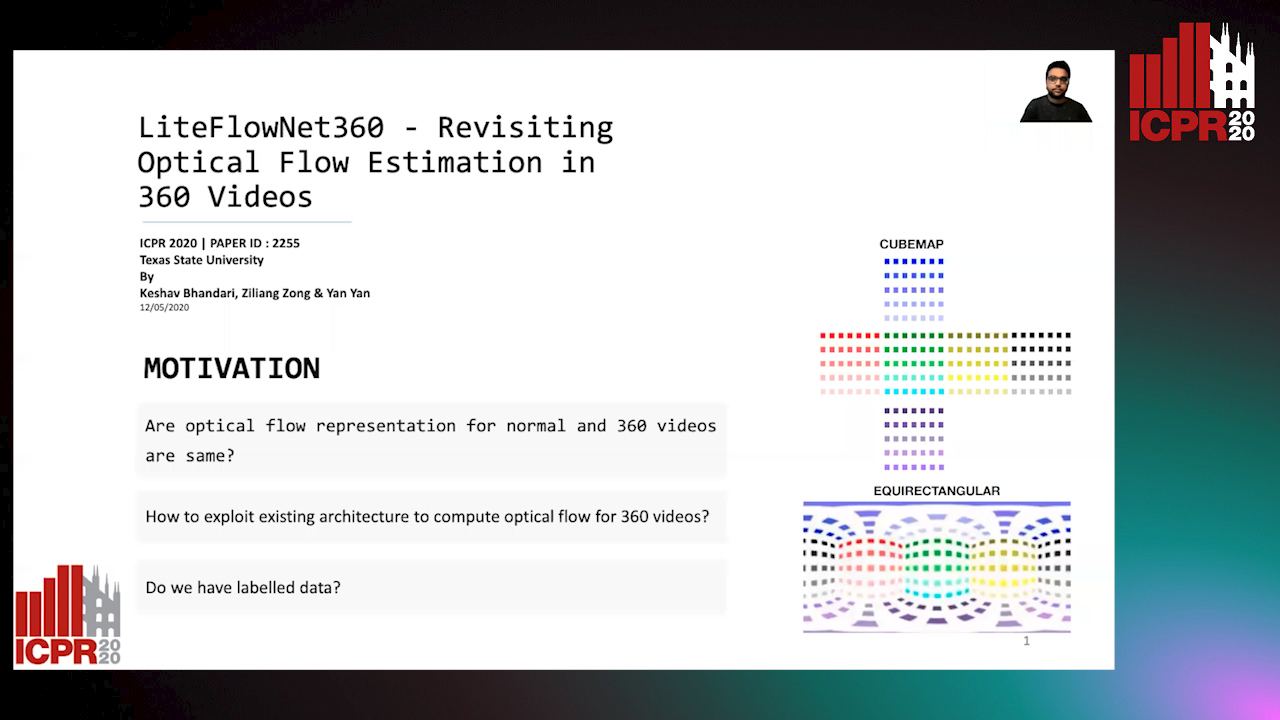
Auto-TLDR; LiteFlowNet360: A Domain Adaptation Framework for 360 Video Optical Flow Estimation
Two-Stage Adaptive Object Scene Flow Using Hybrid CNN-CRF Model
Congcong Li, Haoyu Ma, Qingmin Liao

Auto-TLDR; Adaptive object scene flow estimation using a hybrid CNN-CRF model and adaptive iteration
Abstract Slides Poster Similar
ResFPN: Residual Skip Connections in Multi-Resolution Feature Pyramid Networks for Accurate Dense Pixel Matching
Rishav ., René Schuster, Ramy Battrawy, Oliver Wasenmüler, Didier Stricker

Auto-TLDR; Resolution Feature Pyramid Networks for Dense Pixel Matching
A Lightweight Network to Learn Optical Flow from Event Data

Auto-TLDR; A lightweight pyramid network with attention mechanism to learn optical flow from events data
STaRFlow: A SpatioTemporal Recurrent Cell for Lightweight Multi-Frame Optical Flow Estimation
Pierre Godet, Alexandre Boulch, Aurélien Plyer, Guy Le Besnerais

Auto-TLDR; STaRFlow: A lightweight CNN-based algorithm for optical flow estimation
Abstract Slides Poster Similar
Movement-Induced Priors for Deep Stereo
Yuxin Hou, Muhammad Kamran Janjua, Juho Kannala, Arno Solin

Auto-TLDR; Fusing Stereo Disparity Estimation with Movement-induced Prior Information
Abstract Slides Poster Similar
Orthographic Projection Linear Regression for Single Image 3D Human Pose Estimation
Yahui Zhang, Shaodi You, Theo Gevers

Auto-TLDR; A Deep Neural Network for 3D Human Pose Estimation from a Single 2D Image in the Wild
Abstract Slides Poster Similar
Extending Single Beam Lidar to Full Resolution by Fusing with Single Image Depth Estimation
Yawen Lu, Yuxing Wang, Devarth Parikh, Guoyu Lu

Auto-TLDR; Self-supervised LIDAR for Low-Cost Depth Estimation
Learning Stereo Matchability in Disparity Regression Networks
Jingyang Zhang, Yao Yao, Zixin Luo, Shiwei Li, Tianwei Shen, Tian Fang, Long Quan

Auto-TLDR; Deep Stereo Matchability for Weakly Matchable Regions
Deeply-Fused Attentive Network for Stereo Matching
Zuliu Yang, Xindong Ai, Weida Yang, Yong Zhao, Qifei Dai, Fuchi Li

Auto-TLDR; DF-Net: Deep Learning-based Network for Stereo Matching
Abstract Slides Poster Similar
HPERL: 3D Human Pose Estimastion from RGB and LiDAR
Michael Fürst, Shriya T.P. Gupta, René Schuster, Oliver Wasenmüler, Didier Stricker

Auto-TLDR; 3D Human Pose Estimation Using RGB and LiDAR Using Weakly-Supervised Approach
Abstract Slides Poster Similar
Partially Supervised Multi-Task Network for Single-View Dietary Assessment
Ya Lu, Thomai Stathopoulou, Stavroula Mougiakakou

Auto-TLDR; Food Volume Estimation from a Single Food Image via Geometric Understanding and Semantic Prediction
Abstract Slides Poster Similar
Do We Really Need Scene-Specific Pose Encoders?

Auto-TLDR; Pose Regression Using Deep Convolutional Networks for Visual Similarity
Future Urban Scenes Generation through Vehicles Synthesis
Alessandro Simoni, Luca Bergamini, Andrea Palazzi, Simone Calderara, Rita Cucchiara

Auto-TLDR; Predicting the Future of an Urban Scene with a Novel View Synthesis Paradigm
Abstract Slides Poster Similar
Hybrid Approach for 3D Head Reconstruction: Using Neural Networks and Visual Geometry
Oussema Bouafif, Bogdan Khomutenko, Mohammed Daoudi

Auto-TLDR; Recovering 3D Head Geometry from a Single Image using Deep Learning and Geometric Techniques
Abstract Slides Poster Similar
Motion-Supervised Co-Part Segmentation
Aliaksandr Siarohin, Subhankar Roy, Stéphane Lathuiliere, Sergey Tulyakov, Elisa Ricci, Nicu Sebe

Auto-TLDR; Self-supervised Co-Part Segmentation Using Motion Information from Videos
Exploring Severe Occlusion: Multi-Person 3D Pose Estimation with Gated Convolution
Renshu Gu, Gaoang Wang, Jenq-Neng Hwang

Auto-TLDR; 3D Human Pose Estimation for Multi-Human Videos with Occlusion
Better Prior Knowledge Improves Human-Pose-Based Extrinsic Camera Calibration
Olivier Moliner, Sangxia Huang, Kalle Åström

Auto-TLDR; Improving Human-pose-based Extrinsic Calibration for Multi-Camera Systems
Abstract Slides Poster Similar
Object Segmentation Tracking from Generic Video Cues
Amirhossein Kardoost, Sabine Müller, Joachim Weickert, Margret Keuper

Auto-TLDR; A Light-Weight Variational Framework for Video Object Segmentation in Videos
Abstract Slides Poster Similar
What and How? Jointly Forecasting Human Action and Pose
Yanjun Zhu, Yanxia Zhang, Qiong Liu, Andreas Girgensohn

Auto-TLDR; Forecasting Human Actions and Motion Trajectories with Joint Action Classification and Pose Regression
Abstract Slides Poster Similar
MixedFusion: 6D Object Pose Estimation from Decoupled RGB-Depth Features
Hangtao Feng, Lu Zhang, Xu Yang, Zhiyong Liu

Auto-TLDR; MixedFusion: Combining Color and Point Clouds for 6D Pose Estimation
Abstract Slides Poster Similar
Suppressing Features That Contain Disparity Edge for Stereo Matching
Xindong Ai, Zuliu Yang, Weida Yang, Yong Zhao, Zhengzhong Yu, Fuchi Li

Auto-TLDR; SDE-Attention: A Novel Attention Mechanism for Stereo Matching
Abstract Slides Poster Similar
Residual Learning of Video Frame Interpolation Using Convolutional LSTM

Auto-TLDR; Video Frame Interpolation Using Residual Learning and Convolutional LSTMs
Abstract Slides Poster Similar
Attention Stereo Matching Network
Doudou Zhang, Jing Cai, Yanbing Xue, Zan Gao, Hua Zhang

Auto-TLDR; ASM-Net: Attention Stereo Matching with Disparity Refinement
Abstract Slides Poster Similar
Siamese Fully Convolutional Tracker with Motion Correction
Mathew Francis, Prithwijit Guha

Auto-TLDR; A Siamese Ensemble for Visual Tracking with Appearance and Motion Components
Abstract Slides Poster Similar
Video Semantic Segmentation Using Deep Multi-View Representation Learning
Akrem Sellami, Salvatore Tabbone

Auto-TLDR; Deep Multi-view Representation Learning for Video Object Segmentation
Abstract Slides Poster Similar
A Multi-Task Neural Network for Action Recognition with 3D Key-Points
Rongxiao Tang, Wang Luyang, Zhenhua Guo

Auto-TLDR; Multi-task Neural Network for Action Recognition and 3D Human Pose Estimation
Abstract Slides Poster Similar
FC-DCNN: A Densely Connected Neural Network for Stereo Estimation
Dominik Hirner, Friedrich Fraundorfer

Auto-TLDR; FC-DCNN: A Lightweight Network for Stereo Estimation
Abstract Slides Poster Similar
PEAN: 3D Hand Pose Estimation Adversarial Network
Linhui Sun, Yifan Zhang, Jing Lu, Jian Cheng, Hanqing Lu

Auto-TLDR; PEAN: 3D Hand Pose Estimation with Adversarial Learning Framework
Abstract Slides Poster Similar
Real-Time Monocular Depth Estimation with Extremely Light-Weight Neural Network
Mian Jhong Chiu, Wei-Chen Chiu, Hua-Tsung Chen, Jen-Hui Chuang

Auto-TLDR; Real-Time Light-Weight Depth Prediction for Obstacle Avoidance and Environment Sensing with Deep Learning-based CNN
Abstract Slides Poster Similar
Robust Visual Object Tracking with Two-Stream Residual Convolutional Networks
Ning Zhang, Jingen Liu, Ke Wang, Dan Zeng, Tao Mei

Auto-TLDR; Two-Stream Residual Convolutional Network for Visual Tracking
Abstract Slides Poster Similar
Holistic Grid Fusion Based Stop Line Estimation
Runsheng Xu, Faezeh Tafazzoli, Li Zhang, Timo Rehfeld, Gunther Krehl, Arunava Seal

Auto-TLDR; Fused Multi-Sensory Data for Stop Lines Detection in Intersection Scenarios
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
Learning to Find Good Correspondences of Multiple Objects
Youye Xie, Yingheng Tang, Gongguo Tang, William Hoff

Auto-TLDR; Multi-Object Inliers and Outliers for Perspective-n-Point and Object Recognition
Abstract Slides Poster Similar
Estimation of Clinical Tremor Using Spatio-Temporal Adversarial AutoEncoder
Li Zhang, Vidya Koesmahargyo, Isaac Galatzer-Levy

Auto-TLDR; ST-AAE: Spatio-temporal Adversarial Autoencoder for Clinical Assessment of Hand Tremor Frequency and Severity
Abstract Slides Poster Similar
6D Pose Estimation with Correlation Fusion
Yi Cheng, Hongyuan Zhu, Ying Sun, Cihan Acar, Wei Jing, Yan Wu, Liyuan Li, Cheston Tan, Joo-Hwee Lim

Auto-TLDR; Intra- and Inter-modality Fusion for 6D Object Pose Estimation with Attention Mechanism
Abstract Slides Poster Similar
P2D: A Self-Supervised Method for Depth Estimation from Polarimetry
Marc Blanchon, Desire Sidibe, Olivier Morel, Ralph Seulin, Daniel Braun, Fabrice Meriaudeau

Auto-TLDR; Polarimetric Regularization for Monocular Depth Estimation
Abstract Slides Poster Similar
Joint Face Alignment and 3D Face Reconstruction with Efficient Convolution Neural Networks
Keqiang Li, Huaiyu Wu, Xiuqin Shang, Zhen Shen, Gang Xiong, Xisong Dong, Bin Hu, Fei-Yue Wang

Auto-TLDR; Mobile-FRNet: Efficient 3D Morphable Model Alignment and 3D Face Reconstruction from a Single 2D Facial Image
Abstract Slides Poster Similar
NetCalib: A Novel Approach for LiDAR-Camera Auto-Calibration Based on Deep Learning
Shan Wu, Amnir Hadachi, Damien Vivet, Yadu Prabhakar

Auto-TLDR; Automatic Calibration of LiDAR and Cameras using Deep Neural Network
Abstract Slides Poster Similar
Revisiting Sequence-To-Sequence Video Object Segmentation with Multi-Task Loss and Skip-Memory
Fatemeh Azimi, Benjamin Bischke, Sebastian Palacio, Federico Raue, Jörn Hees, Andreas Dengel

Auto-TLDR; Sequence-to-Sequence Learning for Video Object Segmentation
Abstract Slides Poster Similar
Point In: Counting Trees with Weakly Supervised Segmentation Network
Pinmo Tong, Shuhui Bu, Pengcheng Han

Auto-TLDR; Weakly Tree counting using Deep Segmentation Network with Localization and Mask Prediction
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
Motion Complementary Network for Efficient Action Recognition
Ke Cheng, Yifan Zhang, Chenghua Li, Jian Cheng, Hanqing Lu

Auto-TLDR; Efficient Motion Complementary Network for Action Recognition
Abstract Slides Poster Similar
Wavelet Attention Embedding Networks for Video Super-Resolution
Young-Ju Choi, Young-Woon Lee, Byung-Gyu Kim

Auto-TLDR; Wavelet Attention Embedding Network for Video Super-Resolution
Abstract Slides Poster Similar
Can You Trust Your Pose? Confidence Estimation in Visual Localization
Luca Ferranti, Xiaotian Li, Jani Boutellier, Juho Kannala

Auto-TLDR; Pose Confidence Estimation in Large-Scale Environments: A Light-weight Approach to Improving Pose Estimation Pipeline
Abstract Slides Poster Similar
Adaptive Feature Fusion Network for Gaze Tracking in Mobile Tablets
Yiwei Bao, Yihua Cheng, Yunfei Liu, Feng Lu

Auto-TLDR; Adaptive Feature Fusion Network for Multi-stream Gaze Estimation in Mobile Tablets
Abstract Slides Poster Similar