Motion-Supervised Co-Part Segmentation
Aliaksandr Siarohin,
Subhankar Roy,
Stéphane Lathuiliere,
Sergey Tulyakov,
Elisa Ricci,
Nicu Sebe

Auto-TLDR; Self-supervised Co-Part Segmentation Using Motion Information from Videos
Similar papers
Shape Consistent 2D Keypoint Estimation under Domain Shift
Levi Vasconcelos, Massimiliano Mancini, Davide Boscaini, Barbara Caputo, Elisa Ricci

Auto-TLDR; Deep Adaptation for Keypoint Prediction under Domain Shift
Abstract Slides Poster Similar
Unsupervised Learning of Landmarks Based on Inter-Intra Subject Consistencies
Weijian Li, Haofu Liao, Shun Miao, Le Lu, Jiebo Luo

Auto-TLDR; Unsupervised Learning for Facial Landmark Discovery using Inter-subject Landmark consistencies
Dual-MTGAN: Stochastic and Deterministic Motion Transfer for Image-To-Video Synthesis
Fu-En Yang, Jing-Cheng Chang, Yuan-Hao Lee, Yu-Chiang Frank Wang

Auto-TLDR; Dual Motion Transfer GAN for Convolutional Neural Networks
Abstract Slides Poster Similar
Future Urban Scenes Generation through Vehicles Synthesis
Alessandro Simoni, Luca Bergamini, Andrea Palazzi, Simone Calderara, Rita Cucchiara

Auto-TLDR; Predicting the Future of an Urban Scene with a Novel View Synthesis Paradigm
Abstract Slides Poster Similar
VITON-GT: An Image-Based Virtual Try-On Model with Geometric Transformations
Matteo Fincato, Federico Landi, Marcella Cornia, Fabio Cesari, Rita Cucchiara

Auto-TLDR; VITON-GT: An Image-based Virtual Try-on Architecture for Fashion Catalogs
Abstract Slides Poster Similar
Unsupervised Face Manipulation Via Hallucination
Keerthy Kusumam, Enrique Sanchez, Georgios Tzimiropoulos

Auto-TLDR; Unpaired Face Image Manipulation using Autoencoders
Abstract Slides Poster Similar
Semantic-Guided Inpainting Network for Complex Urban Scenes Manipulation
Pierfrancesco Ardino, Yahui Liu, Elisa Ricci, Bruno Lepri, Marco De Nadai

Auto-TLDR; Semantic-Guided Inpainting of Complex Urban Scene Using Semantic Segmentation and Generation
Abstract Slides Poster Similar
Learning Object Deformation and Motion Adaption for Semi-Supervised Video Object Segmentation
Xiaoyang Zheng, Xin Tan, Jianming Guo, Lizhuang Ma

Auto-TLDR; Semi-supervised Video Object Segmentation with Mask-propagation-based Model
Abstract Slides Poster Similar
Learning to Take Directions One Step at a Time
Qiyang Hu, Adrian Wälchli, Tiziano Portenier, Matthias Zwicker, Paolo Favaro

Auto-TLDR; Generating a Sequence of Motion Strokes from a Single Image
Abstract Slides Poster Similar
Multi-Domain Image-To-Image Translation with Adaptive Inference Graph
The Phuc Nguyen, Stéphane Lathuiliere, Elisa Ricci

Auto-TLDR; Adaptive Graph Structure for Multi-Domain Image-to-Image Translation
Abstract Slides Poster Similar
GarmentGAN: Photo-Realistic Adversarial Fashion Transfer
Amir Hossein Raffiee, Michael Sollami

Auto-TLDR; GarmentGAN: A Generative Adversarial Network for Image-Based Garment Transfer
Abstract Slides Poster Similar
Let's Play Music: Audio-Driven Performance Video Generation
Hao Zhu, Yi Li, Feixia Zhu, Aihua Zheng, Ran He

Auto-TLDR; APVG: Audio-driven Performance Video Generation Using Structured Temporal UNet
Abstract Slides Poster Similar
Video Semantic Segmentation Using Deep Multi-View Representation Learning
Akrem Sellami, Salvatore Tabbone

Auto-TLDR; Deep Multi-view Representation Learning for Video Object Segmentation
Abstract Slides Poster Similar
Weakly Supervised Body Part Segmentation with Pose Based Part Priors
Zhengyuan Yang, Yuncheng Li, Linjie Yang, Ning Zhang, Jiebo Luo

Auto-TLDR; Weakly Supervised Body Part Segmentation Using Weak Labels
Self-Supervised Joint Encoding of Motion and Appearance for First Person Action Recognition
Mirco Planamente, Andrea Bottino, Barbara Caputo

Auto-TLDR; A Single Stream Architecture for Egocentric Action Recognition from the First-Person Point of View
Abstract Slides Poster Similar
Self-Supervised Learning of Dynamic Representations for Static Images
Siyang Song, Enrique Sanchez, Linlin Shen, Michel Valstar

Auto-TLDR; Facial Action Unit Intensity Estimation and Affect Estimation from Still Images with Multiple Temporal Scale
Abstract Slides Poster Similar
Revisiting Sequence-To-Sequence Video Object Segmentation with Multi-Task Loss and Skip-Memory
Fatemeh Azimi, Benjamin Bischke, Sebastian Palacio, Federico Raue, Jörn Hees, Andreas Dengel

Auto-TLDR; Sequence-to-Sequence Learning for Video Object Segmentation
Abstract Slides Poster Similar
Partially Supervised Multi-Task Network for Single-View Dietary Assessment
Ya Lu, Thomai Stathopoulou, Stavroula Mougiakakou

Auto-TLDR; Food Volume Estimation from a Single Food Image via Geometric Understanding and Semantic Prediction
Abstract Slides Poster Similar
Mutual Information Based Method for Unsupervised Disentanglement of Video Representation
Aditya Sreekar P, Ujjwal Tiwari, Anoop Namboodiri

Auto-TLDR; MIPAE: Mutual Information Predictive Auto-Encoder for Video Prediction
Abstract Slides Poster Similar
Reducing the Variance of Variational Estimates of Mutual Information by Limiting the Critic's Hypothesis Space to RKHS
Aditya Sreekar P, Ujjwal Tiwari, Anoop Namboodiri

Auto-TLDR; Mutual Information Estimation from Variational Lower Bounds Using a Critic's Hypothesis Space
Hybrid Approach for 3D Head Reconstruction: Using Neural Networks and Visual Geometry
Oussema Bouafif, Bogdan Khomutenko, Mohammed Daoudi

Auto-TLDR; Recovering 3D Head Geometry from a Single Image using Deep Learning and Geometric Techniques
Abstract Slides Poster Similar
Talking Face Generation Via Learning Semantic and Temporal Synchronous Landmarks
Aihua Zheng, Feixia Zhu, Hao Zhu, Mandi Luo, Ran He

Auto-TLDR; A semantic and temporal synchronous landmark learning method for talking face generation
Abstract Slides Poster Similar
What and How? Jointly Forecasting Human Action and Pose
Yanjun Zhu, Yanxia Zhang, Qiong Liu, Andreas Girgensohn

Auto-TLDR; Forecasting Human Actions and Motion Trajectories with Joint Action Classification and Pose Regression
Abstract Slides Poster Similar
Exploring Severe Occlusion: Multi-Person 3D Pose Estimation with Gated Convolution
Renshu Gu, Gaoang Wang, Jenq-Neng Hwang

Auto-TLDR; 3D Human Pose Estimation for Multi-Human Videos with Occlusion
Inner Eye Canthus Localization for Human Body Temperature Screening
Claudio Ferrari, Lorenzo Berlincioni, Marco Bertini, Alberto Del Bimbo

Auto-TLDR; Automatic Localization of the Inner Eye Canthus in Thermal Face Images using 3D Morphable Face Model
Abstract Slides Poster Similar
JUMPS: Joints Upsampling Method for Pose Sequences
Lucas Mourot, Francois Le Clerc, Cédric Thébault, Pierre Hellier

Auto-TLDR; JUMPS: Increasing the Number of Joints in 2D Pose Estimation and Recovering Occluded or Missing Joints
Abstract Slides Poster Similar
STaRFlow: A SpatioTemporal Recurrent Cell for Lightweight Multi-Frame Optical Flow Estimation
Pierre Godet, Alexandre Boulch, Aurélien Plyer, Guy Le Besnerais

Auto-TLDR; STaRFlow: A lightweight CNN-based algorithm for optical flow estimation
Abstract Slides Poster Similar
The Color Out of Space: Learning Self-Supervised Representations for Earth Observation Imagery
Stefano Vincenzi, Angelo Porrello, Pietro Buzzega, Marco Cipriano, Pietro Fronte, Roberto Cuccu, Carla Ippoliti, Annamaria Conte, Simone Calderara

Auto-TLDR; Satellite Image Representation Learning for Remote Sensing
Abstract Slides Poster Similar
An Unsupervised Approach towards Varying Human Skin Tone Using Generative Adversarial Networks
Debapriya Roy, Diganta Mukherjee, Bhabatosh Chanda

Auto-TLDR; Unsupervised Skin Tone Change Using Augmented Reality Based Models
Abstract Slides Poster Similar
Joint Supervised and Self-Supervised Learning for 3D Real World Challenges
Antonio Alliegro, Davide Boscaini, Tatiana Tommasi

Auto-TLDR; Self-supervision for 3D Shape Classification and Segmentation in Point Clouds
Object Segmentation Tracking from Generic Video Cues
Amirhossein Kardoost, Sabine Müller, Joachim Weickert, Margret Keuper

Auto-TLDR; A Light-Weight Variational Framework for Video Object Segmentation in Videos
Abstract Slides Poster Similar
Coherence and Identity Learning for Arbitrary-Length Face Video Generation
Shuquan Ye, Chu Han, Jiaying Lin, Guoqiang Han, Shengfeng He

Auto-TLDR; Face Video Synthesis Using Identity-Aware GAN and Face Coherence Network
Abstract Slides Poster Similar
5D Light Field Synthesis from a Monocular Video
Kyuho Bae, Andre Ivan, Hajime Nagahara, In Kyu Park

Auto-TLDR; Synthesis of Light Field Video from Monocular Video using Deep Learning
Free-Form Image Inpainting Via Contrastive Attention Network
Xin Ma, Xiaoqiang Zhou, Huaibo Huang, Zhenhua Chai, Xiaolin Wei, Ran He

Auto-TLDR; Self-supervised Siamese inference for image inpainting
Image Representation Learning by Transformation Regression
Xifeng Guo, Jiyuan Liu, Sihang Zhou, En Zhu, Shihao Dong

Auto-TLDR; Self-supervised Image Representation Learning using Continuous Parameter Prediction
Abstract Slides Poster Similar
Revisiting Optical Flow Estimation in 360 Videos
Keshav Bhandari, Ziliang Zong, Yan Yan
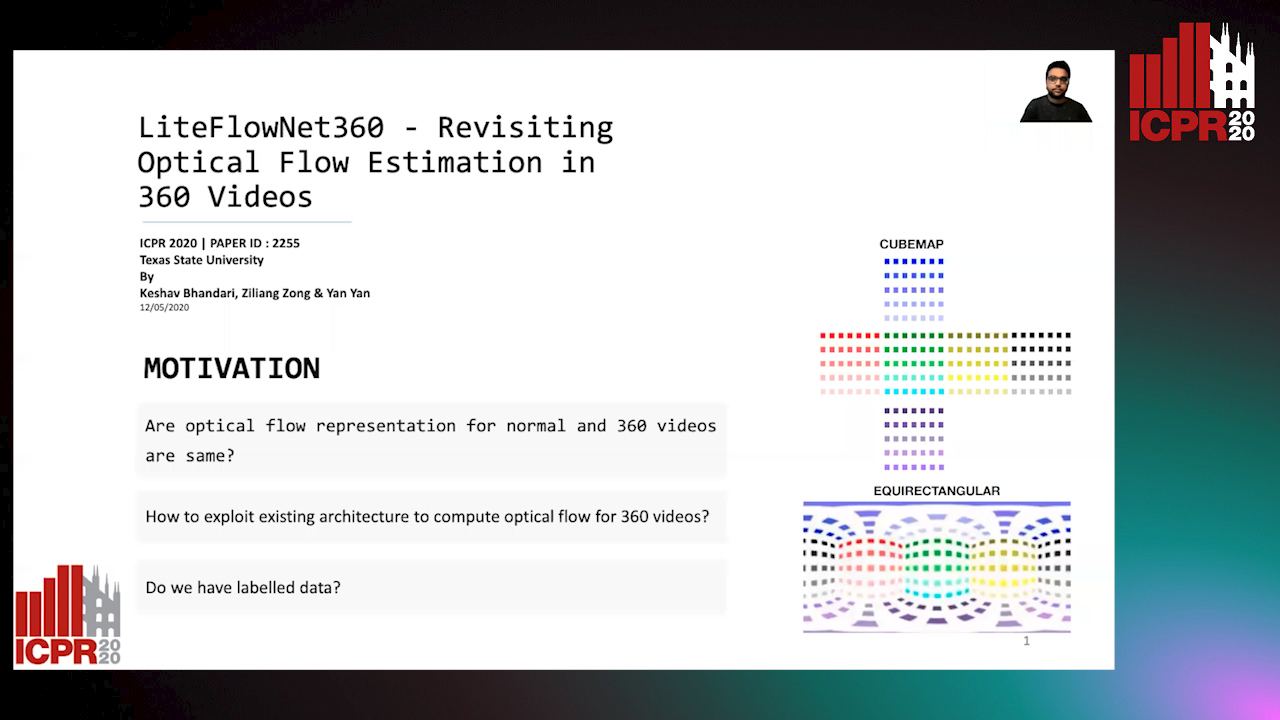
Auto-TLDR; LiteFlowNet360: A Domain Adaptation Framework for 360 Video Optical Flow Estimation
Learning Semantic Representations Via Joint 3D Face Reconstruction and Facial Attribute Estimation
Zichun Weng, Youjun Xiang, Xianfeng Li, Juntao Liang, Wanliang Huo, Yuli Fu

Auto-TLDR; Joint Framework for 3D Face Reconstruction with Facial Attribute Estimation
Abstract Slides Poster Similar
PA-FlowNet: Pose-Auxiliary Optical Flow Network for Spacecraft Relative Pose Estimation
Zhi Yu Chen, Po-Heng Chen, Kuan-Wen Chen, Chen-Yu Chan

Auto-TLDR; PA-FlowNet: An End-to-End Pose-auxiliary Optical Flow Network for Space Travel and Landing
Abstract Slides Poster Similar
SECI-GAN: Semantic and Edge Completion for Dynamic Objects Removal
Francesco Pinto, Andrea Romanoni, Matteo Matteucci, Phil Torr

Auto-TLDR; SECI-GAN: Semantic and Edge Conditioned Inpainting Generative Adversarial Network
Abstract Slides Poster Similar
The Role of Cycle Consistency for Generating Better Human Action Videos from a Single Frame

Auto-TLDR; Generating Videos with Human Action Semantics using Cycle Constraints
Abstract Slides Poster Similar
Vacant Parking Space Detection Based on Task Consistency and Reinforcement Learning
Manh Hung Nguyen, Tzu-Yin Chao, Ching-Chun Huang
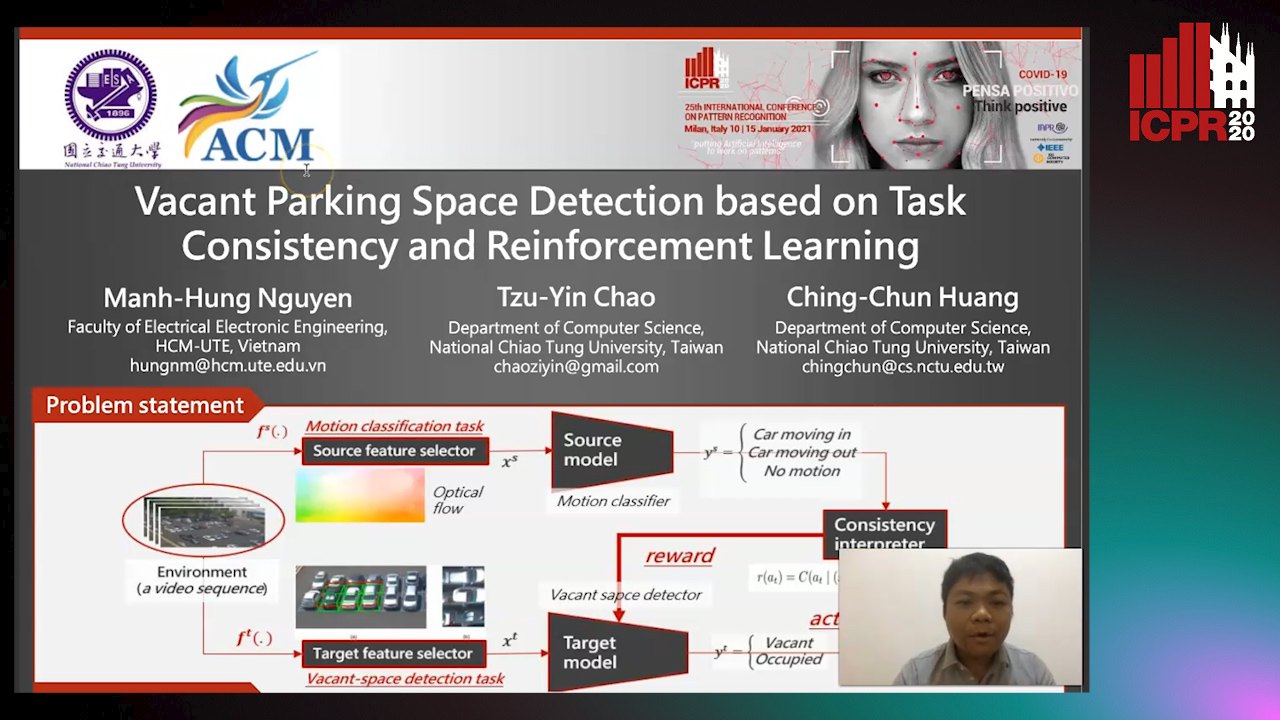
Auto-TLDR; Vacant Space Detection via Semantic Consistency Learning
Abstract Slides Poster Similar
SynDHN: Multi-Object Fish Tracker Trained on Synthetic Underwater Videos
Mygel Andrei Martija, Prospero Naval

Auto-TLDR; Underwater Multi-Object Tracking in the Wild with Deep Hungarian Network
Abstract Slides Poster Similar
Modeling Long-Term Interactions to Enhance Action Recognition
Alejandro Cartas, Petia Radeva, Mariella Dimiccoli

Auto-TLDR; A Hierarchical Long Short-Term Memory Network for Action Recognition in Egocentric Videos
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
Learning Visual Voice Activity Detection with an Automatically Annotated Dataset
Stéphane Lathuiliere, Pablo Mesejo, Radu Horaud

Auto-TLDR; Deep Visual Voice Activity Detection with Optical Flow
Motion U-Net: Multi-Cue Encoder-Decoder Network for Motion Segmentation
Gani Rahmon, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; Motion U-Net: A Deep Learning Framework for Robust Moving Object Detection under Challenging Conditions
Abstract Slides Poster Similar
TinyVIRAT: Low-Resolution Video Action Recognition
Ugur Demir, Yogesh Rawat, Mubarak Shah

Auto-TLDR; TinyVIRAT: A Progressive Generative Approach for Action Recognition in Videos
Abstract Slides Poster Similar
A GAN-Based Blind Inpainting Method for Masonry Wall Images
Yahya Ibrahim, Balázs Nagy, Csaba Benedek

Auto-TLDR; An End-to-End Blind Inpainting Algorithm for Masonry Wall Images
Abstract Slides Poster Similar