A Globally Optimal Method for the PnP Problem with MRP Rotation Parameterization
Manolis Lourakis,
George Terzakis

Auto-TLDR; A Direct least squares, algebraic PnP solver with modified Rodrigues parameters
Similar papers
Minimal Solvers for Indoor UAV Positioning
Marcus Valtonen Örnhag, Patrik Persson, Mårten Wadenbäck, Kalle Åström, Anders Heyden

Auto-TLDR; Relative Pose Solvers for Visual Indoor UAV Navigation
Abstract Slides Poster Similar
Computing Stable Resultant-Based Minimal Solvers by Hiding a Variable
Snehal Bhayani, Zuzana Kukelova, Janne Heikkilä

Auto-TLDR; Sparse Permian-Based Method for Solving Minimal Systems of Polynomial Equations
A Two-Step Approach to Lidar-Camera Calibration
Yingna Su, Yaqing Ding, Jian Yang, Hui Kong

Auto-TLDR; Closed-Form Calibration of Lidar-camera System for Ego-motion Estimation and Scene Understanding
Abstract Slides Poster Similar
Camera Calibration Using Parallel Line Segments

Auto-TLDR; Closed-Form Calibration of Surveillance Cameras using Parallel 3D Line Segment Projections
Abstract Slides Poster Similar
Generic Merging of Structure from Motion Maps with a Low Memory Footprint
Gabrielle Flood, David Gillsjö, Patrik Persson, Anders Heyden, Kalle Åström

Auto-TLDR; A Low-Memory Footprint Representation for Robust Map Merge
Abstract Slides Poster Similar
Total Estimation from RGB Video: On-Line Camera Self-Calibration, Non-Rigid Shape and Motion

Auto-TLDR; Joint Auto-Calibration, Pose and 3D Reconstruction of a Non-rigid Object from an uncalibrated RGB Image Sequence
Abstract Slides Poster Similar
Rotational Adjoint Methods for Learning-Free 3D Human Pose Estimation from IMU Data
Caterina Emilia Agelide Buizza, Yiannis Demiris

Auto-TLDR; Learning-free 3D Human Pose Estimation from Inertial Measurement Unit Data
Calibration and Absolute Pose Estimation of Trinocular Linear Camera Array for Smart City Applications
Martin Ahrnbom, Mikael Nilsson, Håkan Ardö, Kalle Åström, Oksana Yastremska-Kravchenko, Aliaksei Laureshyn

Auto-TLDR; Trinocular Linear Camera Array Calibration for Traffic Surveillance Applications
Abstract Slides Poster Similar
Photometric Stereo with Twin-Fisheye Cameras
Jordan Caracotte, Fabio Morbidi, El Mustapha Mouaddib

Auto-TLDR; Photometric stereo problem for low-cost 360-degree cameras
Abstract Slides Poster Similar
Sequential Non-Rigid Factorisation for Head Pose Estimation
Stefania Cristina, Kenneth Patrick Camilleri

Auto-TLDR; Sequential Shape-and-Motion Factorisation for Head Pose Estimation in Eye-Gaze Tracking
Abstract Slides Poster Similar
3D Pots Configuration System by Optimizing Over Geometric Constraints
Jae Eun Kim, Muhammad Zeeshan Arshad, Seong Jong Yoo, Je Hyeong Hong, Jinwook Kim, Young Min Kim

Auto-TLDR; Optimizing 3D Configurations for Stable Pottery Restoration from irregular and noisy evidence
Abstract Slides Poster Similar
A Plane-Based Approach for Indoor Point Clouds Registration
Ketty Favre, Muriel Pressigout, Luce Morin, Eric Marchand

Auto-TLDR; A plane-based registration approach for indoor environments based on LiDAR data
Abstract Slides Poster Similar
Motion Segmentation with Pairwise Matches and Unknown Number of Motions
Federica Arrigoni, Tomas Pajdla, Luca Magri

Auto-TLDR; Motion Segmentation using Multi-Modelfitting andpermutation synchronization
Abstract Slides Poster Similar
Learning to Find Good Correspondences of Multiple Objects
Youye Xie, Yingheng Tang, Gongguo Tang, William Hoff

Auto-TLDR; Multi-Object Inliers and Outliers for Perspective-n-Point and Object Recognition
Abstract Slides Poster Similar
Occlusion-Tolerant and Personalized 3D Human Pose Estimation in RGB Images

Auto-TLDR; Real-Time 3D Human Pose Estimation in BVH using Inverse Kinematics Solver and Neural Networks
Better Prior Knowledge Improves Human-Pose-Based Extrinsic Camera Calibration
Olivier Moliner, Sangxia Huang, Kalle Åström

Auto-TLDR; Improving Human-pose-based Extrinsic Calibration for Multi-Camera Systems
Abstract Slides Poster Similar
Hybrid Approach for 3D Head Reconstruction: Using Neural Networks and Visual Geometry
Oussema Bouafif, Bogdan Khomutenko, Mohammed Daoudi

Auto-TLDR; Recovering 3D Head Geometry from a Single Image using Deep Learning and Geometric Techniques
Abstract Slides Poster Similar
Combined Invariants to Gaussian Blur and Affine Transformation
Jitka Kostkova, Jan Flusser, Matteo Pedone

Auto-TLDR; A new theory of combined moment invariants to Gaussian blur and spatial affine transformation
Abstract Slides Poster Similar
Transferable Model for Shape Optimization subject to Physical Constraints
Lukas Harsch, Johannes Burgbacher, Stefan Riedelbauch

Auto-TLDR; U-Net with Spatial Transformer Network for Flow Simulations
Abstract Slides Poster Similar
Directionally Paired Principal Component Analysis for Bivariate Estimation Problems
Navdeep Dahiya, Yifei Fan, Samuel Bignardi, Tony Yezzi, Romeil Sandhu

Auto-TLDR; Asymmetrically-Paired Principal Component Analysis for Linear Dimension-Reduction
Abstract Slides Poster Similar
AV-SLAM: Autonomous Vehicle SLAM with Gravity Direction Initialization
Kaan Yilmaz, Baris Suslu, Sohini Roychowdhury, L. Srikar Muppirisetty

Auto-TLDR; VI-SLAM with AGI: A combination of three SLAM algorithms for autonomous vehicles
Abstract Slides Poster Similar
A New Geodesic-Based Feature for Characterization of 3D Shapes: Application to Soft Tissue Organ Temporal Deformations
Karim Makki, Amine Bohi, Augustin Ogier, Marc-Emmanuel Bellemare

Auto-TLDR; Spatio-Temporal Feature Descriptors for 3D Shape Characterization from Point Clouds
Abstract Slides Poster Similar
HP2IFS: Head Pose Estimation Exploiting Partitioned Iterated Function Systems
Carmen Bisogni, Michele Nappi, Chiara Pero, Stefano Ricciardi

Auto-TLDR; PIFS based head pose estimation using fractal coding theory and Partitioned Iterated Function Systems
Abstract Slides Poster Similar
Inner Eye Canthus Localization for Human Body Temperature Screening
Claudio Ferrari, Lorenzo Berlincioni, Marco Bertini, Alberto Del Bimbo

Auto-TLDR; Automatic Localization of the Inner Eye Canthus in Thermal Face Images using 3D Morphable Face Model
Abstract Slides Poster Similar
Generic Document Image Dewarping by Probabilistic Discretization of Vanishing Points
Gilles Simon, Salvatore Tabbone

Auto-TLDR; Robust Document Dewarping using vanishing points
Abstract Slides Poster Similar
Generalized Conics: Properties and Applications
Aysylu Gabdulkhakova, Walter Kropatsch

Auto-TLDR; A Generalized Conic Representation for Distance Fields
Abstract Slides Poster Similar
Exact and Convergent Iterative Methods to Compute the Orthogonal Point-To-Ellipse Distance
Siyu Guo, Pingping Hu, Zhigang Ling, He Wen, Min Liu, Lu Tang

Auto-TLDR; Convergent iterative algorithm for orthogonal distance based ellipse fitting
Abstract Slides Poster Similar
Unconstrained Vision Guided UAV Based Safe Helicopter Landing
Arindam Sikdar, Abhimanyu Sahu, Debajit Sen, Rohit Mahajan, Ananda Chowdhury

Auto-TLDR; Autonomous Helicopter Landing in Hazardous Environments from Unmanned Aerial Images Using Constrained Graph Clustering
Abstract Slides Poster Similar
Local Binary Quaternion Rotation Pattern for Colour Texture Retrieval
Hela Jebali, Noel Richard, Mohamed Naouai
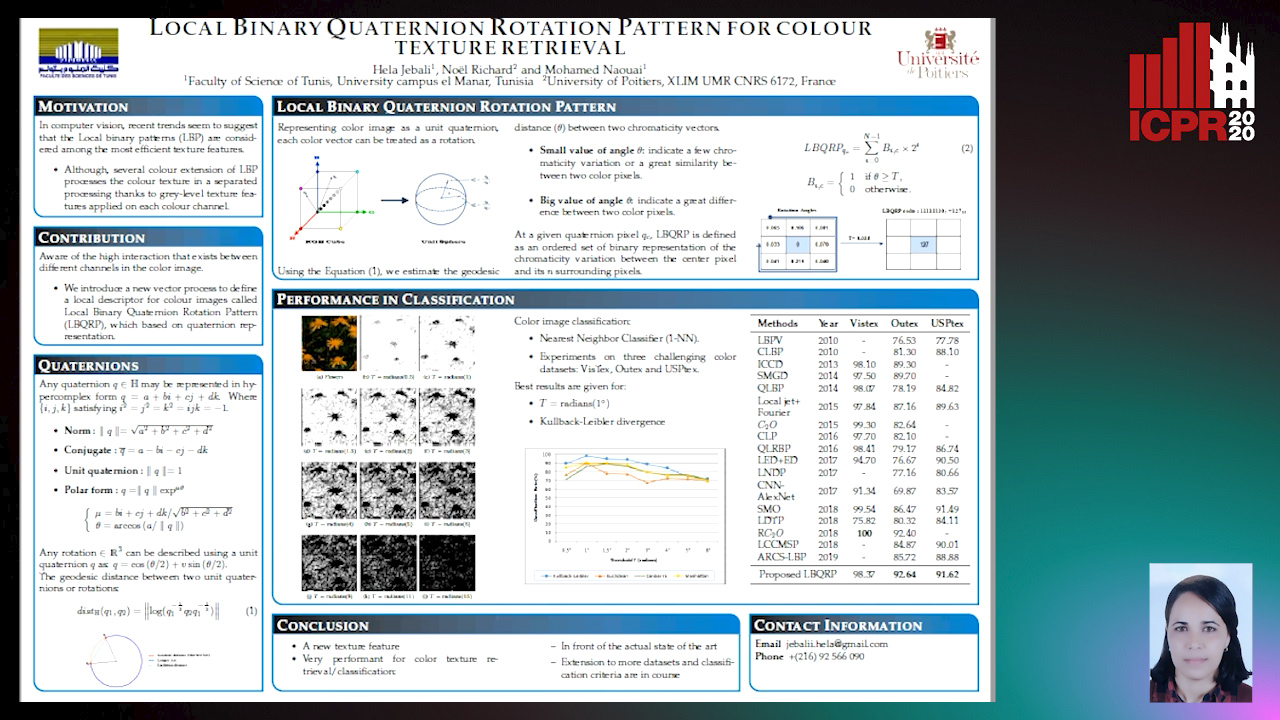
Auto-TLDR; Local Binary Quaternion Rotation Pattern for Color Texture Classification
Mobile Augmented Reality: Fast, Precise, and Smooth Planar Object Tracking
Dmitrii Matveichev, Daw-Tung Lin

Auto-TLDR; Planar Object Tracking with Sparse Optical Flow Tracking and Descriptor Matching
Abstract Slides Poster Similar
Edge-Aware Monocular Dense Depth Estimation with Morphology
Zhi Li, Xiaoyang Zhu, Haitao Yu, Qi Zhang, Yongshi Jiang

Auto-TLDR; Spatio-Temporally Smooth Dense Depth Maps Using Only a CPU
Abstract Slides Poster Similar
Learning Non-Rigid Surface Reconstruction from Spatio-Temporal Image Patches
Matteo Pedone, Abdelrahman Mostafa, Janne Heikkilä

Auto-TLDR; Dense Spatio-Temporal Depth Maps of Deformable Objects from Video Sequences
Abstract Slides Poster Similar
P2D: A Self-Supervised Method for Depth Estimation from Polarimetry
Marc Blanchon, Desire Sidibe, Olivier Morel, Ralph Seulin, Daniel Braun, Fabrice Meriaudeau

Auto-TLDR; Polarimetric Regularization for Monocular Depth Estimation
Abstract Slides Poster Similar
NetCalib: A Novel Approach for LiDAR-Camera Auto-Calibration Based on Deep Learning
Shan Wu, Amnir Hadachi, Damien Vivet, Yadu Prabhakar

Auto-TLDR; Automatic Calibration of LiDAR and Cameras using Deep Neural Network
Abstract Slides Poster Similar
Adaptive Estimation of Optimal Color Transformations for Deep Convolutional Network Based Homography Estimation
Miguel A. Molina-Cabello, Jorge García-González, Rafael Marcos Luque-Baena, Karl Thurnhofer-Hemsi, Ezequiel López-Rubio

Auto-TLDR; Improving Homography Estimation from a Pair of Natural Images Using Deep Convolutional Neural Networks
Abstract Slides Poster Similar
Fast Multi-Level Foreground Estimation
Thomas Germer, Tobias Uelwer, Stefan Conrad, Stefan Harmeling

Auto-TLDR; Fur foreground estimation given the alpha matte
Abstract Slides Poster Similar
Inferring Functional Properties from Fluid Dynamics Features
Andrea Schillaci, Maurizio Quadrio, Carlotta Pipolo, Marcello Restelli, Giacomo Boracchi

Auto-TLDR; Exploiting Convective Properties of Computational Fluid Dynamics for Medical Diagnosis
Abstract Slides Poster Similar
Effective Deployment of CNNs for 3DoF Pose Estimation and Grasping in Industrial Settings
Daniele De Gregorio, Riccardo Zanella, Gianluca Palli, Luigi Di Stefano

Auto-TLDR; Automated Deep Learning for Robotic Grasping Applications
Abstract Slides Poster Similar
Polarimetric Image Augmentation
Marc Blanchon, Fabrice Meriaudeau, Olivier Morel, Ralph Seulin, Desire Sidibe

Auto-TLDR; Polarimetric Augmentation for Deep Learning in Robotics Applications
Movement-Induced Priors for Deep Stereo
Yuxin Hou, Muhammad Kamran Janjua, Juho Kannala, Arno Solin

Auto-TLDR; Fusing Stereo Disparity Estimation with Movement-induced Prior Information
Abstract Slides Poster Similar
3D Point Cloud Registration Based on Cascaded Mutual Information Attention Network

Auto-TLDR; Cascaded Mutual Information Attention Network for 3D Point Cloud Registration
Abstract Slides Poster Similar
PROPEL: Probabilistic Parametric Regression Loss for Convolutional Neural Networks
Muhammad Asad, Rilwan Basaru, S M Masudur Rahman Al Arif, Greg Slabaugh

Auto-TLDR; PRObabilistic Parametric rEgression Loss for Probabilistic Regression Using Convolutional Neural Networks
Are Multiple Cross-Correlation Identities Better Than Just Two? Improving the Estimate of Time Differences-Of-Arrivals from Blind Audio Signals
Danilo Greco, Jacopo Cavazza, Alessio Del Bue

Auto-TLDR; Improving Blind Channel Identification Using Cross-Correlation Identity for Time Differences-of-Arrivals Estimation
Abstract Slides Poster Similar
Quaternion Capsule Networks
Barış Özcan, Furkan Kınlı, Mustafa Furkan Kirac

Auto-TLDR; Quaternion Capsule Networks for Object Recognition
Abstract Slides Poster Similar
Recovery of 2D and 3D Layout Information through an Advanced Image Stitching Algorithm Using Scanning Electron Microscope Images
Aayush Singla, Bernhard Lippmann, Helmut Graeb

Auto-TLDR; Image Stitching for True Geometrical Layout Recovery in Nanoscale Dimension
Abstract Slides Poster Similar
Benchmarking Cameras for OpenVSLAM Indoors
Kevin Chappellet, Guillaume Caron, Fumio Kanehiro, Ken Sakurada, Abderrahmane Kheddar

Auto-TLDR; OpenVSLAM: Benchmarking Camera Types for Visual Simultaneous Localization and Mapping
Abstract Slides Poster Similar
Self-Supervised Detection and Pose Estimation of Logistical Objects in 3D Sensor Data
Nikolas Müller, Jonas Stenzel, Jian-Jia Chen

Auto-TLDR; A self-supervised and fully automated deep learning approach for object pose estimation using simulated 3D data
Abstract Slides Poster Similar
User-Independent Gaze Estimation by Extracting Pupil Parameter and Its Mapping to the Gaze Angle

Auto-TLDR; Gaze Point Estimation using Pupil Shape for Generalization
Abstract Slides Poster Similar