Generic Document Image Dewarping by Probabilistic Discretization of Vanishing Points
Gilles Simon,
Salvatore Tabbone

Auto-TLDR; Robust Document Dewarping using vanishing points
Similar papers
A Gated and Bifurcated Stacked U-Net Module for Document Image Dewarping
Hmrishav Bandyopadhyay, Tanmoy Dasgupta, Nibaran Das, Mita Nasipuri

Auto-TLDR; Gated and Bifurcated Stacked U-Net for Dewarping Document Images
Abstract Slides Poster Similar
ID Documents Matching and Localization with Multi-Hypothesis Constraints
Guillaume Chiron, Nabil Ghanmi, Ahmad Montaser Awal

Auto-TLDR; Identity Document Localization in the Wild Using Multi-hypothesis Exploration
Abstract Slides Poster Similar
Approach for Document Detection by Contours and Contrasts
Daniil Tropin, Sergey Ilyuhin, Dmitry Nikolaev, Vladimir V. Arlazarov

Auto-TLDR; A countor-based method for arbitrary document detection on a mobile device
Abstract Slides Poster Similar
Text Baseline Recognition Using a Recurrent Convolutional Neural Network
Matthias Wödlinger, Robert Sablatnig

Auto-TLDR; Automatic Baseline Detection of Handwritten Text Using Recurrent Convolutional Neural Network
Abstract Slides Poster Similar
The HisClima Database: Historical Weather Logs for Automatic Transcription and Information Extraction
Verónica Romero, Joan Andreu Sánchez

Auto-TLDR; Automatic Handwritten Text Recognition and Information Extraction from Historical Weather Logs
Abstract Slides Poster Similar
Unsupervised deep learning for text line segmentation
Berat Kurar Barakat, Ahmad Droby, Reem Alaasam, Borak Madi, Irina Rabaev, Raed Shammes, Jihad El-Sana

Auto-TLDR; Unsupervised Deep Learning for Handwritten Text Line Segmentation without Annotation
Combining Deep and Ad-Hoc Solutions to Localize Text Lines in Ancient Arabic Document Images
Olfa Mechi, Maroua Mehri, Rolf Ingold, Najoua Essoukri Ben Amara

Auto-TLDR; Text Line Localization in Ancient Handwritten Arabic Document Images using U-Net and Topological Structural Analysis
Abstract Slides Poster Similar
Learning to Sort Handwritten Text Lines in Reading Order through Estimated Binary Order Relations

Auto-TLDR; Automatic Reading Order of Text Lines in Handwritten Text Documents
Camera Calibration Using Parallel Line Segments

Auto-TLDR; Closed-Form Calibration of Surveillance Cameras using Parallel 3D Line Segment Projections
Abstract Slides Poster Similar
An Integrated Approach of Deep Learning and Symbolic Analysis for Digital PDF Table Extraction
Mengshi Zhang, Daniel Perelman, Vu Le, Sumit Gulwani

Auto-TLDR; Deep Learning and Symbolic Reasoning for Unstructured PDF Table Extraction
Abstract Slides Poster Similar
An Evaluation of DNN Architectures for Page Segmentation of Historical Newspapers
Manuel Burghardt, Bernhard Liebl

Auto-TLDR; Evaluation of Backbone Architectures for Optical Character Segmentation of Historical Documents
Abstract Slides Poster Similar
One Step Clustering Based on A-Contrario Framework for Detection of Alterations in Historical Violins
Alireza Rezaei, Sylvie Le Hégarat-Mascle, Emanuel Aldea, Piercarlo Dondi, Marco Malagodi

Auto-TLDR; A-Contrario Clustering for the Detection of Altered Violins using UVIFL Images
Abstract Slides Poster Similar
Watch Your Strokes: Improving Handwritten Text Recognition with Deformable Convolutions
Iulian Cojocaru, Silvia Cascianelli, Lorenzo Baraldi, Massimiliano Corsini, Rita Cucchiara

Auto-TLDR; Deformable Convolutional Neural Networks for Handwritten Text Recognition
Abstract Slides Poster Similar
Photometric Stereo with Twin-Fisheye Cameras
Jordan Caracotte, Fabio Morbidi, El Mustapha Mouaddib

Auto-TLDR; Photometric stereo problem for low-cost 360-degree cameras
Abstract Slides Poster Similar
Calibration and Absolute Pose Estimation of Trinocular Linear Camera Array for Smart City Applications
Martin Ahrnbom, Mikael Nilsson, Håkan Ardö, Kalle Åström, Oksana Yastremska-Kravchenko, Aliaksei Laureshyn

Auto-TLDR; Trinocular Linear Camera Array Calibration for Traffic Surveillance Applications
Abstract Slides Poster Similar
P2D: A Self-Supervised Method for Depth Estimation from Polarimetry
Marc Blanchon, Desire Sidibe, Olivier Morel, Ralph Seulin, Daniel Braun, Fabrice Meriaudeau

Auto-TLDR; Polarimetric Regularization for Monocular Depth Estimation
Abstract Slides Poster Similar
Fast Approximate Modelling of the Next Combination Result for Stopping the Text Recognition in a Video
Konstantin Bulatov, Nadezhda Fedotova, Vladimir V. Arlazarov

Auto-TLDR; Stopping Video Stream Recognition of a Text Field Using Optimized Computation Scheme
Abstract Slides Poster Similar
Textual-Content Based Classification of Bundles of Untranscribed of Manuscript Images
José Ramón Prieto Fontcuberta, Enrique Vidal, Vicente Bosch, Carlos Alonso, Carmen Orcero, Lourdes Márquez

Auto-TLDR; Probabilistic Indexing for Text-based Classification of Manuscripts
Abstract Slides Poster Similar
3D Pots Configuration System by Optimizing Over Geometric Constraints
Jae Eun Kim, Muhammad Zeeshan Arshad, Seong Jong Yoo, Je Hyeong Hong, Jinwook Kim, Young Min Kim

Auto-TLDR; Optimizing 3D Configurations for Stable Pottery Restoration from irregular and noisy evidence
Abstract Slides Poster Similar
Total Estimation from RGB Video: On-Line Camera Self-Calibration, Non-Rigid Shape and Motion

Auto-TLDR; Joint Auto-Calibration, Pose and 3D Reconstruction of a Non-rigid Object from an uncalibrated RGB Image Sequence
Abstract Slides Poster Similar
Feature Embedding Based Text Instance Grouping for Largely Spaced and Occluded Text Detection
Pan Gao, Qi Wan, Renwu Gao, Linlin Shen

Auto-TLDR; Text Instance Embedding Based Feature Embeddings for Multiple Text Instance Grouping
Abstract Slides Poster Similar
A Two-Step Approach to Lidar-Camera Calibration
Yingna Su, Yaqing Ding, Jian Yang, Hui Kong

Auto-TLDR; Closed-Form Calibration of Lidar-camera System for Ego-motion Estimation and Scene Understanding
Abstract Slides Poster Similar
Minimal Solvers for Indoor UAV Positioning
Marcus Valtonen Örnhag, Patrik Persson, Mårten Wadenbäck, Kalle Åström, Anders Heyden

Auto-TLDR; Relative Pose Solvers for Visual Indoor UAV Navigation
Abstract Slides Poster Similar
Better Prior Knowledge Improves Human-Pose-Based Extrinsic Camera Calibration
Olivier Moliner, Sangxia Huang, Kalle Åström

Auto-TLDR; Improving Human-pose-based Extrinsic Calibration for Multi-Camera Systems
Abstract Slides Poster Similar
Quantization in Relative Gradient Angle Domain for Building Polygon Estimation
Yuhao Chen, Yifan Wu, Linlin Xu, Alexander Wong

Auto-TLDR; Relative Gradient Angle Transform for Building Footprint Extraction from Remote Sensing Data
Abstract Slides Poster Similar
An Accurate Threshold Insensitive Kernel Detector for Arbitrary Shaped Text
Xijun Qian, Yifan Liu, Yu-Bin Yang

Auto-TLDR; TIKD: threshold insensitive kernel detector for arbitrary shaped text
Multimodal Side-Tuning for Document Classification
Stefano Zingaro, Giuseppe Lisanti, Maurizio Gabbrielli

Auto-TLDR; Side-tuning for Multimodal Document Classification
Abstract Slides Poster Similar
Uncertainty Guided Recognition of Tiny Craters on the Moon
Thorsten Wilhelm, Christian Wöhler

Auto-TLDR; Accurately Detecting Tiny Craters in Remote Sensed Images Using Deep Neural Networks
Abstract Slides Poster Similar
Recognizing Multiple Text Sequences from an Image by Pure End-To-End Learning
Zhenlong Xu, Shuigeng Zhou, Fan Bai, Cheng Zhanzhan, Yi Niu, Shiliang Pu

Auto-TLDR; Pure End-to-End Learning for Multiple Text Sequences Recognition from Images
Abstract Slides Poster Similar
Distortion-Adaptive Grape Bunch Counting for Omnidirectional Images
Ryota Akai, Yuzuko Utsumi, Yuka Miwa, Masakazu Iwamura, Koichi Kise

Auto-TLDR; Object Counting for Omnidirectional Images Using Stereographic Projection
Ancient Document Layout Analysis: Autoencoders Meet Sparse Coding
Homa Davoudi, Marco Fiorucci, Arianna Traviglia

Auto-TLDR; Unsupervised Unsupervised Representation Learning for Document Layout Analysis
Abstract Slides Poster Similar
DUET: Detection Utilizing Enhancement for Text in Scanned or Captured Documents
Eun-Soo Jung, Hyeonggwan Son, Kyusam Oh, Yongkeun Yun, Soonhwan Kwon, Min Soo Kim

Auto-TLDR; Text Detection for Document Images Using Synthetic and Real Data
Abstract Slides Poster Similar
End-To-End Hierarchical Relation Extraction for Generic Form Understanding
Tuan Anh Nguyen Dang, Duc-Thanh Hoang, Quang Bach Tran, Chih-Wei Pan, Thanh-Dat Nguyen

Auto-TLDR; Joint Entity Labeling and Link Prediction for Form Understanding in Noisy Scanned Documents
Abstract Slides Poster Similar
Local Gradient Difference Based Mass Features for Classification of 2D-3D Natural Scene Text Images
Lokesh Nandanwar, Shivakumara Palaiahnakote, Raghavendra Ramachandra, Tong Lu, Umapada Pal, Daniel Lopresti, Nor Badrul Anuar
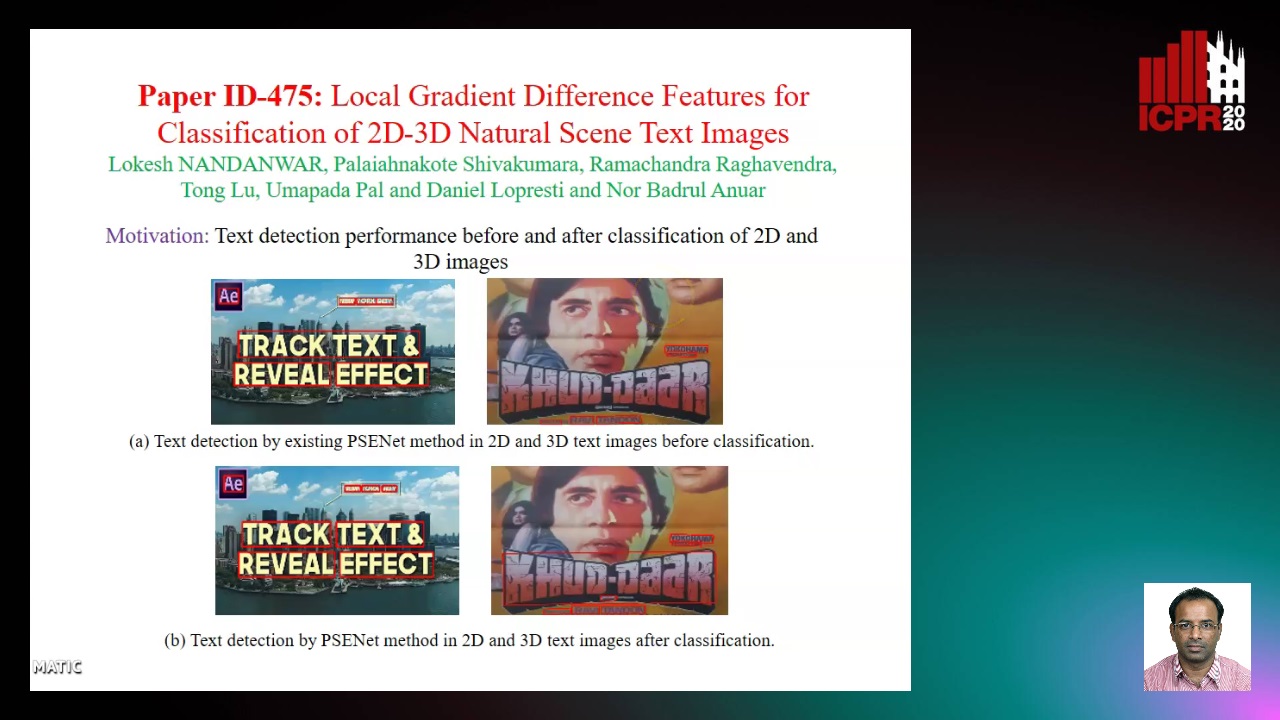
Auto-TLDR; Classification of 2D and 3D Natural Scene Images Using COLD
Abstract Slides Poster Similar
Vision-Based Layout Detection from Scientific Literature Using Recurrent Convolutional Neural Networks

Auto-TLDR; Transfer Learning for Scientific Literature Layout Detection Using Convolutional Neural Networks
Abstract Slides Poster Similar
Recursive Recognition of Offline Handwritten Mathematical Expressions
Marco Cotogni, Claudio Cusano, Antonino Nocera

Auto-TLDR; Online Handwritten Mathematical Expression Recognition with Recurrent Neural Network
Abstract Slides Poster Similar
OmniFlowNet: A Perspective Neural Network Adaptation for Optical Flow Estimation in Omnidirectional Images
Charles-Olivier Artizzu, Haozhou Zhang, Guillaume Allibert, Cédric Demonceaux

Auto-TLDR; OmniFlowNet: A Convolutional Neural Network for Omnidirectional Optical Flow Estimation
Abstract Slides Poster Similar
A Heuristic-Based Decision Tree for Connected Components Labeling of 3D Volumes
Maximilian Söchting, Stefano Allegretti, Federico Bolelli, Costantino Grana

Auto-TLDR; Entropy Partitioning Decision Tree for Connected Components Labeling
Abstract Slides Poster Similar
Unconstrained Vision Guided UAV Based Safe Helicopter Landing
Arindam Sikdar, Abhimanyu Sahu, Debajit Sen, Rohit Mahajan, Ananda Chowdhury

Auto-TLDR; Autonomous Helicopter Landing in Hazardous Environments from Unmanned Aerial Images Using Constrained Graph Clustering
Abstract Slides Poster Similar
Multiple Document Datasets Pre-Training Improves Text Line Detection with Deep Neural Networks
Mélodie Boillet, Christopher Kermorvant, Thierry Paquet

Auto-TLDR; A fully convolutional network for document layout analysis
Writer Identification Using Deep Neural Networks: Impact of Patch Size and Number of Patches
Akshay Punjabi, José Ramón Prieto Fontcuberta, Enrique Vidal

Auto-TLDR; Writer Recognition Using Deep Neural Networks for Handwritten Text Images
Abstract Slides Poster Similar
PIF: Anomaly detection via preference embedding
Filippo Leveni, Luca Magri, Giacomo Boracchi, Cesare Alippi

Auto-TLDR; PIF: Anomaly Detection with Preference Embedding for Structured Patterns
Abstract Slides Poster Similar
Generic Merging of Structure from Motion Maps with a Low Memory Footprint
Gabrielle Flood, David Gillsjö, Patrik Persson, Anders Heyden, Kalle Åström

Auto-TLDR; A Low-Memory Footprint Representation for Robust Map Merge
Abstract Slides Poster Similar
Automated Whiteboard Lecture Video Summarization by Content Region Detection and Representation
Bhargava Urala Kota, Alexander Stone, Kenny Davila, Srirangaraj Setlur, Venu Govindaraju

Auto-TLDR; A Framework for Summarizing Whiteboard Lecture Videos Using Feature Representations of Handwritten Content Regions
A Globally Optimal Method for the PnP Problem with MRP Rotation Parameterization
Manolis Lourakis, George Terzakis

Auto-TLDR; A Direct least squares, algebraic PnP solver with modified Rodrigues parameters
Generation of Hypergraphs from the N-Best Parsing of 2D-Probabilistic Context-Free Grammars for Mathematical Expression Recognition
Noya Ernesto, Joan Andreu Sánchez, Jose Miguel Benedi

Auto-TLDR; Hypergraphs: A Compact Representation of the N-best parse trees from 2D-PCFGs
Abstract Slides Poster Similar
Documents Counterfeit Detection through a Deep Learning Approach
Darwin Danilo Saire Pilco, Salvatore Tabbone

Auto-TLDR; End-to-End Learning for Counterfeit Documents Detection using Deep Neural Network
Abstract Slides Poster Similar
On Morphological Hierarchies for Image Sequences
Caglayan Tuna, Alain Giros, François Merciol, Sébastien Lefèvre

Auto-TLDR; Comparison of Hierarchies for Image Sequences
Abstract Slides Poster Similar