Fast Approximate Modelling of the Next Combination Result for Stopping the Text Recognition in a Video
Konstantin Bulatov,
Nadezhda Fedotova,
Vladimir V. Arlazarov

Auto-TLDR; Stopping Video Stream Recognition of a Text Field Using Optimized Computation Scheme
Similar papers
Approach for Document Detection by Contours and Contrasts
Daniil Tropin, Sergey Ilyuhin, Dmitry Nikolaev, Vladimir V. Arlazarov

Auto-TLDR; A countor-based method for arbitrary document detection on a mobile device
Abstract Slides Poster Similar
Automated Whiteboard Lecture Video Summarization by Content Region Detection and Representation
Bhargava Urala Kota, Alexander Stone, Kenny Davila, Srirangaraj Setlur, Venu Govindaraju

Auto-TLDR; A Framework for Summarizing Whiteboard Lecture Videos Using Feature Representations of Handwritten Content Regions
ID Documents Matching and Localization with Multi-Hypothesis Constraints
Guillaume Chiron, Nabil Ghanmi, Ahmad Montaser Awal

Auto-TLDR; Identity Document Localization in the Wild Using Multi-hypothesis Exploration
Abstract Slides Poster Similar
Fast Implementation of 4-Bit Convolutional Neural Networks for Mobile Devices
Anton Trusov, Elena Limonova, Dmitry Slugin, Dmitry Nikolaev, Vladimir V. Arlazarov

Auto-TLDR; Efficient Quantized Low-Precision Neural Networks for Mobile Devices
Abstract Slides Poster Similar
Robust Lexicon-Free Confidence Prediction for Text Recognition
Qi Song, Qianyi Jiang, Rui Zhang, Xiaolin Wei

Auto-TLDR; Confidence Measurement for Optical Character Recognition using Single-Input Multi-Output Network
Abstract Slides Poster Similar
Feature Embedding Based Text Instance Grouping for Largely Spaced and Occluded Text Detection
Pan Gao, Qi Wan, Renwu Gao, Linlin Shen

Auto-TLDR; Text Instance Embedding Based Feature Embeddings for Multiple Text Instance Grouping
Abstract Slides Poster Similar
Learning to Sort Handwritten Text Lines in Reading Order through Estimated Binary Order Relations

Auto-TLDR; Automatic Reading Order of Text Lines in Handwritten Text Documents
A Multi-Head Self-Relation Network for Scene Text Recognition
Zhou Junwei, Hongchao Gao, Jiao Dai, Dongqin Liu, Jizhong Han

Auto-TLDR; Multi-head Self-relation Network for Scene Text Recognition
Abstract Slides Poster Similar
Recognizing Multiple Text Sequences from an Image by Pure End-To-End Learning
Zhenlong Xu, Shuigeng Zhou, Fan Bai, Cheng Zhanzhan, Yi Niu, Shiliang Pu

Auto-TLDR; Pure End-to-End Learning for Multiple Text Sequences Recognition from Images
Abstract Slides Poster Similar
PICK: Processing Key Information Extraction from Documents Using Improved Graph Learning-Convolutional Networks
Wenwen Yu, Ning Lu, Xianbiao Qi, Ping Gong, Rong Xiao

Auto-TLDR; PICK: A Graph Learning Framework for Key Information Extraction from Documents
Abstract Slides Poster Similar
The HisClima Database: Historical Weather Logs for Automatic Transcription and Information Extraction
Verónica Romero, Joan Andreu Sánchez

Auto-TLDR; Automatic Handwritten Text Recognition and Information Extraction from Historical Weather Logs
Abstract Slides Poster Similar
Textual-Content Based Classification of Bundles of Untranscribed of Manuscript Images
José Ramón Prieto Fontcuberta, Enrique Vidal, Vicente Bosch, Carlos Alonso, Carmen Orcero, Lourdes Márquez

Auto-TLDR; Probabilistic Indexing for Text-based Classification of Manuscripts
Abstract Slides Poster Similar
LODENet: A Holistic Approach to Offline Handwritten Chinese and Japanese Text Line Recognition
Huu Tin Hoang, Chun-Jen Peng, Hung Tran, Hung Le, Huy Hoang Nguyen

Auto-TLDR; Logographic DEComposition Encoding for Chinese and Japanese Text Line Recognition
Abstract Slides Poster Similar
Local Gradient Difference Based Mass Features for Classification of 2D-3D Natural Scene Text Images
Lokesh Nandanwar, Shivakumara Palaiahnakote, Raghavendra Ramachandra, Tong Lu, Umapada Pal, Daniel Lopresti, Nor Badrul Anuar
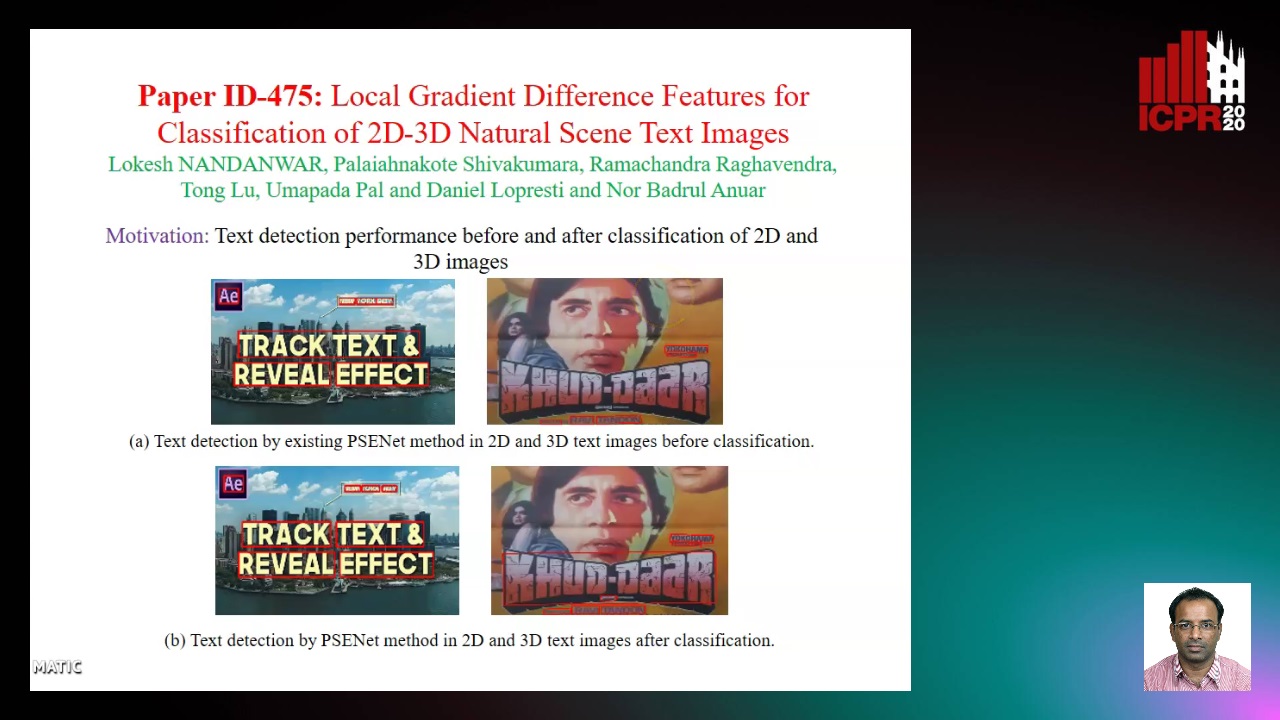
Auto-TLDR; Classification of 2D and 3D Natural Scene Images Using COLD
Abstract Slides Poster Similar
A Gated and Bifurcated Stacked U-Net Module for Document Image Dewarping
Hmrishav Bandyopadhyay, Tanmoy Dasgupta, Nibaran Das, Mita Nasipuri

Auto-TLDR; Gated and Bifurcated Stacked U-Net for Dewarping Document Images
Abstract Slides Poster Similar
Multi-Task Learning Based Traditional Mongolian Words Recognition
Hongxi Wei, Hui Zhang, Jing Zhang, Kexin Liu

Auto-TLDR; Multi-task Learning for Mongolian Words Recognition
Abstract Slides Poster Similar
Watch Your Strokes: Improving Handwritten Text Recognition with Deformable Convolutions
Iulian Cojocaru, Silvia Cascianelli, Lorenzo Baraldi, Massimiliano Corsini, Rita Cucchiara

Auto-TLDR; Deformable Convolutional Neural Networks for Handwritten Text Recognition
Abstract Slides Poster Similar
ConvMath : A Convolutional Sequence Network for Mathematical Expression Recognition
Zuoyu Yan, Xiaode Zhang, Liangcai Gao, Ke Yuan, Zhi Tang

Auto-TLDR; Convolutional Sequence Modeling for Mathematical Expressions Recognition
Abstract Slides Poster Similar
Improving Word Recognition Using Multiple Hypotheses and Deep Embeddings
Siddhant Bansal, Praveen Krishnan, C. V. Jawahar

Auto-TLDR; EmbedNet: fuse recognition-based and recognition-free approaches for word recognition using learning-based methods
Abstract Slides Poster Similar
Text Recognition - Real World Data and Where to Find Them
Klára Janoušková, Lluis Gomez, Dimosthenis Karatzas, Jiri Matas

Auto-TLDR; Exploiting Weakly Annotated Images for Text Extraction
Abstract Slides Poster Similar
Transferable Adversarial Attacks for Deep Scene Text Detection
Shudeng Wu, Tao Dai, Guanghao Meng, Bin Chen, Jian Lu, Shutao Xia

Auto-TLDR; Robustness of DNN-based STD methods against Adversarial Attacks
Generic Document Image Dewarping by Probabilistic Discretization of Vanishing Points
Gilles Simon, Salvatore Tabbone

Auto-TLDR; Robust Document Dewarping using vanishing points
Abstract Slides Poster Similar
Text Baseline Recognition Using a Recurrent Convolutional Neural Network
Matthias Wödlinger, Robert Sablatnig

Auto-TLDR; Automatic Baseline Detection of Handwritten Text Using Recurrent Convolutional Neural Network
Abstract Slides Poster Similar
ReADS: A Rectified Attentional Double Supervised Network for Scene Text Recognition
Qi Song, Qianyi Jiang, Xiaolin Wei, Nan Li, Rui Zhang

Auto-TLDR; ReADS: Rectified Attentional Double Supervised Network for General Scene Text Recognition
Abstract Slides Poster Similar
2D License Plate Recognition based on Automatic Perspective Rectification
Hui Xu, Zhao-Hong Guo, Da-Han Wang, Xiang-Dong Zhou, Yu Shi

Auto-TLDR; Perspective Rectification Network for License Plate Recognition
Abstract Slides Poster Similar
RLST: A Reinforcement Learning Approach to Scene Text Detection Refinement
Xuan Peng, Zheng Huang, Kai Chen, Jie Guo, Weidong Qiu

Auto-TLDR; Saccadic Eye Movements and Peripheral Vision for Scene Text Detection using Reinforcement Learning
Abstract Slides Poster Similar
On-Device Text Image Super Resolution
Dhruval Jain, Arun Prabhu, Gopi Ramena, Manoj Goyal, Debi Mohanty, Naresh Purre, Sukumar Moharana

Auto-TLDR; A Novel Deep Neural Network for Super-Resolution on Low Resolution Text Images
Abstract Slides Poster Similar
Sample-Aware Data Augmentor for Scene Text Recognition
Guanghao Meng, Tao Dai, Shudeng Wu, Bin Chen, Jian Lu, Yong Jiang, Shutao Xia

Auto-TLDR; Sample-Aware Data Augmentation for Scene Text Recognition
Abstract Slides Poster Similar
Cost-Effective Adversarial Attacks against Scene Text Recognition
Mingkun Yang, Haitian Zheng, Xiang Bai, Jiebo Luo

Auto-TLDR; Adversarial Attacks on Scene Text Recognition
Abstract Slides Poster Similar
Multimodal Side-Tuning for Document Classification
Stefano Zingaro, Giuseppe Lisanti, Maurizio Gabbrielli

Auto-TLDR; Side-tuning for Multimodal Document Classification
Abstract Slides Poster Similar
Handwritten Digit String Recognition Using Deep Autoencoder Based Segmentation and ResNet Based Recognition Approach
Anuran Chakraborty, Rajonya De, Samir Malakar, Friedhelm Schwenker, Ram Sarkar

Auto-TLDR; Handwritten Digit Strings Recognition Using Residual Network and Deep Autoencoder Based Segmentation
Abstract Slides Poster Similar
Scene Text Detection with Selected Anchors
Anna Zhu, Hang Du, Shengwu Xiong

Auto-TLDR; AS-RPN: Anchor Selection-based Region Proposal Network for Scene Text Detection
Abstract Slides Poster Similar
Text Recognition in Real Scenarios with a Few Labeled Samples
Jinghuang Lin, Cheng Zhanzhan, Fan Bai, Yi Niu, Shiliang Pu, Shuigeng Zhou

Auto-TLDR; Few-shot Adversarial Sequence Domain Adaptation for Scene Text Recognition
Abstract Slides Poster Similar
Exploiting the Logits: Joint Sign Language Recognition and Spell-Correction
Christina Runkel, Stefan Dorenkamp, Hartmut Bauermeister, Michael Möller

Auto-TLDR; A Convolutional Neural Network for Spell-correction in Sign Language Videos
Abstract Slides Poster Similar
Recursive Recognition of Offline Handwritten Mathematical Expressions
Marco Cotogni, Claudio Cusano, Antonino Nocera

Auto-TLDR; Online Handwritten Mathematical Expression Recognition with Recurrent Neural Network
Abstract Slides Poster Similar
Stratified Multi-Task Learning for Robust Spotting of Scene Texts
Kinjal Dasgupta, Sudip Das, Ujjwal Bhattacharya

Auto-TLDR; Feature Representation Block for Multi-task Learning of Scene Text
IBN-STR: A Robust Text Recognizer for Irregular Text in Natural Scenes
Xiaoqian Li, Jie Liu, Shuwu Zhang

Auto-TLDR; IBN-STR: A Robust Text Recognition System Based on Data and Feature Representation
Generation of Hypergraphs from the N-Best Parsing of 2D-Probabilistic Context-Free Grammars for Mathematical Expression Recognition
Noya Ernesto, Joan Andreu Sánchez, Jose Miguel Benedi

Auto-TLDR; Hypergraphs: A Compact Representation of the N-best parse trees from 2D-PCFGs
Abstract Slides Poster Similar
Vision-Based Layout Detection from Scientific Literature Using Recurrent Convolutional Neural Networks

Auto-TLDR; Transfer Learning for Scientific Literature Layout Detection Using Convolutional Neural Networks
Abstract Slides Poster Similar
Enhancing Handwritten Text Recognition with N-Gram Sequencedecomposition and Multitask Learning
Vasiliki Tassopoulou, George Retsinas, Petros Maragos

Auto-TLDR; Multi-task Learning for Handwritten Text Recognition
Abstract Slides Poster Similar
MEAN: A Multi-Element Attention Based Network for Scene Text Recognition
Ruijie Yan, Liangrui Peng, Shanyu Xiao, Gang Yao, Jaesik Min

Auto-TLDR; Multi-element Attention Network for Scene Text Recognition
Abstract Slides Poster Similar
A Few-Shot Learning Approach for Historical Ciphered Manuscript Recognition
Mohamed Ali Souibgui, Alicia Fornés, Yousri Kessentini, Crina Tudor

Auto-TLDR; Handwritten Ciphers Recognition Using Few-Shot Object Detection
Fusion of Global-Local Features for Image Quality Inspection of Shipping Label
Sungho Suh, Paul Lukowicz, Yong Oh Lee

Auto-TLDR; Input Image Quality Verification for Automated Shipping Address Recognition and Verification
Abstract Slides Poster Similar
Object Segmentation Tracking from Generic Video Cues
Amirhossein Kardoost, Sabine Müller, Joachim Weickert, Margret Keuper

Auto-TLDR; A Light-Weight Variational Framework for Video Object Segmentation in Videos
Abstract Slides Poster Similar
Label or Message: A Large-Scale Experimental Survey of Texts and Objects Co-Occurrence
Koki Takeshita, Juntaro Shioyama, Seiichi Uchida

Auto-TLDR; Large-scale Survey of Co-occurrence between Objects and Scene Text with a State-of-the-art Scene Text detector and Recognizer
Writer Identification Using Deep Neural Networks: Impact of Patch Size and Number of Patches
Akshay Punjabi, José Ramón Prieto Fontcuberta, Enrique Vidal

Auto-TLDR; Writer Recognition Using Deep Neural Networks for Handwritten Text Images
Abstract Slides Poster Similar
Named Entity Recognition and Relation Extraction with Graph Neural Networks in Semi Structured Documents
Manuel Carbonell, Pau Riba, Mauricio Villegas, Alicia Fornés, Josep Llados

Auto-TLDR; Graph Neural Network for Entity Recognition and Relation Extraction in Semi-Structured Documents
Weakly Supervised Attention Rectification for Scene Text Recognition
Chengyu Gu, Shilin Wang, Yiwei Zhu, Zheng Huang, Kai Chen

Auto-TLDR; An auxiliary supervision branch for attention-based scene text recognition
Abstract Slides Poster Similar