MEG: Multi-Evidence GNN for Multimodal Semantic Forensics
Ekraam Sabir,
Ayush Jaiswal,
Wael Abdalmageed,
Prem Natarajan

Auto-TLDR; Scalable Image Repurposing Detection with Graph Neural Network Based Model
Similar papers
Equation Attention Relationship Network (EARN) : A Geometric Deep Metric Framework for Learning Similar Math Expression Embedding
Saleem Ahmed, Kenny Davila, Srirangaraj Setlur, Venu Govindaraju

Auto-TLDR; Representational Learning for Similarity Based Retrieval of Mathematical Expressions
Abstract Slides Poster Similar
Region and Relations Based Multi Attention Network for Graph Classification
Manasvi Aggarwal, M. Narasimha Murty

Auto-TLDR; R2POOL: A Graph Pooling Layer for Non-euclidean Structures
Abstract Slides Poster Similar
Classification of Intestinal Gland Cell-Graphs Using Graph Neural Networks
Linda Studer, Jannis Wallau, Heather Dawson, Inti Zlobec, Andreas Fischer

Auto-TLDR; Graph Neural Networks for Classification of Dysplastic Gland Glands using Graph Neural Networks
Abstract Slides Poster Similar
A CNN-RNN Framework for Image Annotation from Visual Cues and Social Network Metadata
Tobia Tesan, Pasquale Coscia, Lamberto Ballan

Auto-TLDR; Context-Based Image Annotation with Multiple Semantic Embeddings and Recurrent Neural Networks
Abstract Slides Poster Similar
Visual Oriented Encoder: Integrating Multimodal and Multi-Scale Contexts for Video Captioning

Auto-TLDR; Visual Oriented Encoder for Video Captioning
Abstract Slides Poster Similar
Named Entity Recognition and Relation Extraction with Graph Neural Networks in Semi Structured Documents
Manuel Carbonell, Pau Riba, Mauricio Villegas, Alicia Fornés, Josep Llados

Auto-TLDR; Graph Neural Network for Entity Recognition and Relation Extraction in Semi-Structured Documents
Detecting Manipulated Facial Videos: A Time Series Solution
Zhang Zhewei, Ma Can, Gao Meilin, Ding Bowen

Auto-TLDR; Face-Alignment Based Bi-LSTM for Fake Video Detection
Abstract Slides Poster Similar
Privacy Attributes-Aware Message Passing Neural Network for Visual Privacy Attributes Classification
Hanbin Hong, Wentao Bao, Yuan Hong, Yu Kong

Auto-TLDR; Privacy Attributes-Aware Message Passing Neural Network for Visual Privacy Attribute Classification
Abstract Slides Poster Similar
Self-Supervised Learning with Graph Neural Networks for Region of Interest Retrieval in Histopathology
Yigit Ozen, Selim Aksoy, Kemal Kosemehmetoglu, Sevgen Onder, Aysegul Uner

Auto-TLDR; Self-supervised Contrastive Learning for Deep Representation Learning of Histopathology Images
Abstract Slides Poster Similar
Zero-Shot Text Classification with Semantically Extended Graph Convolutional Network
Tengfei Liu, Yongli Hu, Junbin Gao, Yanfeng Sun, Baocai Yin

Auto-TLDR; Semantically Extended Graph Convolutional Network for Zero-shot Text Classification
Abstract Slides Poster Similar
A Novel Attention-Based Aggregation Function to Combine Vision and Language
Matteo Stefanini, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara

Auto-TLDR; Fully-Attentive Reduction for Vision and Language
Abstract Slides Poster Similar
Temporal Collaborative Filtering with Graph Convolutional Neural Networks
Esther Rodrigo-Bonet, Minh Duc Nguyen, Nikos Deligiannis

Auto-TLDR; Temporal Collaborative Filtering with Graph-Neural-Network-based Neural Networks
Abstract Slides Poster Similar
VSR++: Improving Visual Semantic Reasoning for Fine-Grained Image-Text Matching
Hui Yuan, Yan Huang, Dongbo Zhang, Zerui Chen, Wenlong Cheng, Liang Wang

Auto-TLDR; Improving Visual Semantic Reasoning for Fine-Grained Image-Text Matching
Abstract Slides Poster Similar
A General Model for Learning Node and Graph Representations Jointly

Auto-TLDR; Joint Community Detection/Dynamic Routing for Graph Classification
Abstract Slides Poster Similar
Transformer Reasoning Network for Image-Text Matching and Retrieval
Nicola Messina, Fabrizio Falchi, Andrea Esuli, Giuseppe Amato

Auto-TLDR; A Transformer Encoder Reasoning Network for Image-Text Matching in Large-Scale Information Retrieval
Abstract Slides Poster Similar
ESResNet: Environmental Sound Classification Based on Visual Domain Models
Andrey Guzhov, Federico Raue, Jörn Hees, Andreas Dengel

Auto-TLDR; Environmental Sound Classification with Short-Time Fourier Transform Spectrograms
Abstract Slides Poster Similar
Information Graphic Summarization Using a Collection of Multimodal Deep Neural Networks
Edward Kim, Connor Onweller, Kathleen F. Mccoy

Auto-TLDR; A multimodal deep learning framework that can generate summarization text supporting the main idea of an information graphic for presentation to blind or visually impaired
Dual Path Multi-Modal High-Order Features for Textual Content Based Visual Question Answering
Yanan Li, Yuetan Lin, Hongrui Zhao, Donghui Wang

Auto-TLDR; TextVQA: An End-to-End Visual Question Answering Model for Text-Based VQA
Directional Graph Networks with Hard Weight Assignments
Miguel Dominguez, Raymond Ptucha

Auto-TLDR; Hard Directional Graph Networks for Point Cloud Analysis
Abstract Slides Poster Similar
Edge-Aware Graph Attention Network for Ratio of Edge-User Estimation in Mobile Networks
Jiehui Deng, Sheng Wan, Xiang Wang, Enmei Tu, Xiaolin Huang, Jie Yang, Chen Gong

Auto-TLDR; EAGAT: Edge-Aware Graph Attention Network for Automatic REU Estimation in Mobile Networks
Abstract Slides Poster Similar
Enriching Video Captions with Contextual Text
Philipp Rimle, Pelin Dogan, Markus Gross

Auto-TLDR; Contextualized Video Captioning Using Contextual Text
Abstract Slides Poster Similar
Label Incorporated Graph Neural Networks for Text Classification
Yuan Xin, Linli Xu, Junliang Guo, Jiquan Li, Xin Sheng, Yuanyuan Zhou

Auto-TLDR; Graph Neural Networks for Semi-supervised Text Classification
Abstract Slides Poster Similar
3D Facial Matching by Spiral Convolutional Metric Learning and a Biometric Fusion-Net of Demographic Properties
Soha Sadat Mahdi, Nele Nauwelaers, Philip Joris, Giorgos Bouritsas, Imperial London, Sergiy Bokhnyak, Susan Walsh, Mark Shriver, Michael Bronstein, Peter Claes

Auto-TLDR; Multi-biometric Fusion for Biometric Verification using 3D Facial Mesures
Video Face Manipulation Detection through Ensemble of CNNs
Nicolo Bonettini, Edoardo Daniele Cannas, Sara Mandelli, Luca Bondi, Paolo Bestagini, Stefano Tubaro

Auto-TLDR; Face Manipulation Detection in Video Sequences Using Convolutional Neural Networks
Trajectory-User Link with Attention Recurrent Networks
Tao Sun, Yongjun Xu, Fei Wang, Lin Wu, 塘文 钱, Zezhi Shao

Auto-TLDR; TULAR: Trajectory-User Link with Attention Recurrent Neural Networks
Abstract Slides Poster Similar
Multi-Modal Contextual Graph Neural Network for Text Visual Question Answering
Yaoyuan Liang, Xin Wang, Xuguang Duan, Wenwu Zhu

Auto-TLDR; Multi-modal Contextual Graph Neural Network for Text Visual Question Answering
Abstract Slides Poster Similar
GCNs-Based Context-Aware Short Text Similarity Model

Auto-TLDR; Context-Aware Graph Convolutional Network for Text Similarity
Abstract Slides Poster Similar
Multi-Modal Identification of State-Sponsored Propaganda on Social Media

Auto-TLDR; A balanced dataset for detecting state-sponsored Internet propaganda
Abstract Slides Poster Similar
FatNet: A Feature-Attentive Network for 3D Point Cloud Processing
Chaitanya Kaul, Nick Pears, Suresh Manandhar

Auto-TLDR; Feature-Attentive Neural Networks for Point Cloud Classification and Segmentation
Feature Engineering and Stacked Echo State Networks for Musical Onset Detection
Peter Steiner, Azarakhsh Jalalvand, Simon Stone, Peter Birkholz

Auto-TLDR; Echo State Networks for Onset Detection in Music Analysis
Abstract Slides Poster Similar
TreeRNN: Topology-Preserving Deep Graph Embedding and Learning
Yecheng Lyu, Ming Li, Xinming Huang, Ulkuhan Guler, Patrick Schaumont, Ziming Zhang

Auto-TLDR; TreeRNN: Recurrent Neural Network for General Graph Classification
Abstract Slides Poster Similar
Text Synopsis Generation for Egocentric Videos
Aidean Sharghi, Niels Lobo, Mubarak Shah

Auto-TLDR; Egocentric Video Summarization Using Multi-task Learning for End-to-End Learning
Evaluation of Anomaly Detection Algorithms for the Real-World Applications
Marija Ivanovska, Domen Tabernik, Danijel Skocaj, Janez Pers

Auto-TLDR; Evaluating Anomaly Detection Algorithms for Practical Applications
Abstract Slides Poster Similar
Beyond the Deep Metric Learning: Enhance the Cross-Modal Matching with Adversarial Discriminative Domain Regularization
Li Ren, Kai Li, Liqiang Wang, Kien Hua

Auto-TLDR; Adversarial Discriminative Domain Regularization for Efficient Cross-Modal Matching
Abstract Slides Poster Similar
Multi-Stage Attention Based Visual Question Answering
Aakansha Mishra, Ashish Anand, Prithwijit Guha

Auto-TLDR; Alternative Bi-directional Attention for Visual Question Answering
FashionGraph: Understanding Fashion Data Using Scene Graph Generation
Shabnam Sadegharmaki, Marc A. Kastner, Shin'Ichi Satoh
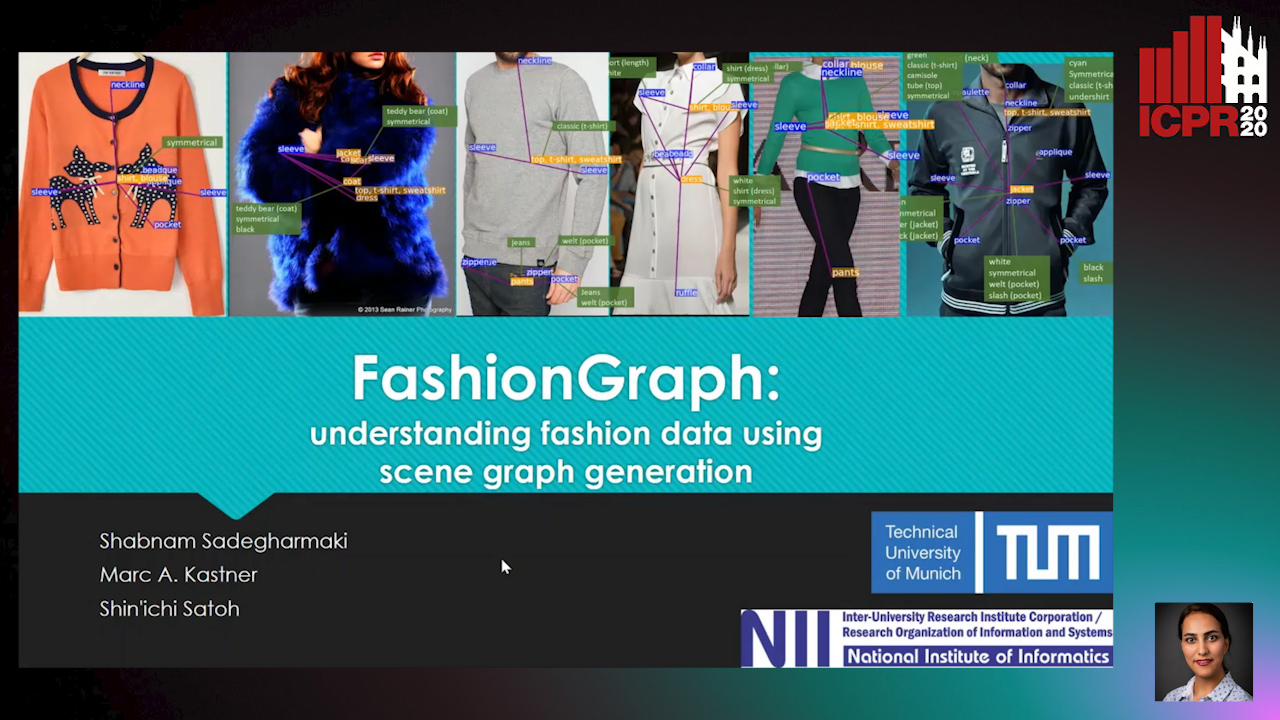
Auto-TLDR; Exploiting Scene Graph Knowledge for Fashion Applications
KoreALBERT: Pretraining a Lite BERT Model for Korean Language Understanding
Hyunjae Lee, Jaewoong Yun, Bongkyu Hwang, Seongho Joe, Seungjai Min, Youngjune Gwon

Auto-TLDR; KoreALBERT: A monolingual ALBERT model for Korean language understanding
Abstract Slides Poster Similar
What Nodes Vote To? Graph Classification without Readout Phase
Yuxing Tian, Zheng Liu, Weiding Liu, Zeyu Zhang, Yanwen Qu

Auto-TLDR; node voting based graph classification with convolutional operator
Abstract Slides Poster Similar
Malware Detection by Exploiting Deep Learning over Binary Programs
Panpan Qi, Zhaoqi Zhang, Wei Wang, Chang Yao

Auto-TLDR; End-to-End Malware Detection without Feature Engineering
Abstract Slides Poster Similar
Revisiting Graph Neural Networks: Graph Filtering Perspective
Hoang Nguyen-Thai, Takanori Maehara, Tsuyoshi Murata

Auto-TLDR; Two-Layers Graph Convolutional Network with Graph Filters Neural Network
Abstract Slides Poster Similar
Improving Visual Relation Detection Using Depth Maps
Sahand Sharifzadeh, Sina Moayed Baharlou, Max Berrendorf, Rajat Koner, Volker Tresp

Auto-TLDR; Exploiting Depth Maps for Visual Relation Detection
Abstract Slides Poster Similar
Webly Supervised Image-Text Embedding with Noisy Tag Refinement
Niluthpol Mithun, Ravdeep Pasricha, Evangelos Papalexakis, Amit Roy-Chowdhury

Auto-TLDR; Robust Joint Embedding for Image-Text Retrieval Using Web Images
SECI-GAN: Semantic and Edge Completion for Dynamic Objects Removal
Francesco Pinto, Andrea Romanoni, Matteo Matteucci, Phil Torr

Auto-TLDR; SECI-GAN: Semantic and Edge Conditioned Inpainting Generative Adversarial Network
Abstract Slides Poster Similar
Assessing the Severity of Health States Based on Social Media Posts
Shweta Yadav, Joy Prakash Sain, Amit Sheth, Asif Ekbal, Sriparna Saha, Pushpak Bhattacharyya

Auto-TLDR; A Multiview Learning Framework for Assessment of Health State in Online Health Communities
Abstract Slides Poster Similar
Multi-Scale 2D Representation Learning for Weakly-Supervised Moment Retrieval
Ding Li, Rui Wu, Zhizhong Zhang, Yongqiang Tang, Wensheng Zhang

Auto-TLDR; Multi-scale 2D Representation Learning for Weakly Supervised Video Moment Retrieval
Abstract Slides Poster Similar
A Novel Actor Dual-Critic Model for Remote Sensing Image Captioning
Ruchika Chavhan, Biplab Banerjee, Xiao Xiang Zhu, Subhasis Chaudhuri

Auto-TLDR; Actor Dual-Critic Training for Remote Sensing Image Captioning Using Deep Reinforcement Learning
Abstract Slides Poster Similar
On Identification and Retrieval of Near-Duplicate Biological Images: A New Dataset and Protocol
Thomas E. Koker, Sai Spandana Chintapalli, San Wang, Blake A. Talbot, Daniel Wainstock, Marcelo Cicconet, Mary C. Walsh

Auto-TLDR; BINDER: Bio-Image Near-Duplicate Examples Repository for Image Identification and Retrieval
Picture-To-Amount (PITA): Predicting Relative Ingredient Amounts from Food Images
Jiatong Li, Fangda Han, Ricardo Guerrero, Vladimir Pavlovic

Auto-TLDR; PITA: A Deep Learning Architecture for Predicting the Relative Amount of Ingredients from Food Images
Abstract Slides Poster Similar