Webly Supervised Image-Text Embedding with Noisy Tag Refinement
Niluthpol Mithun,
Ravdeep Pasricha,
Evangelos Papalexakis,
Amit Roy-Chowdhury

Auto-TLDR; Robust Joint Embedding for Image-Text Retrieval Using Web Images
Similar papers
JECL: Joint Embedding and Cluster Learning for Image-Text Pairs
Sean Yang, Kuan-Hao Huang, Bill Howe

Auto-TLDR; JECL: Clustering Image-Caption Pairs with Parallel Encoders and Regularized Clusters
A CNN-RNN Framework for Image Annotation from Visual Cues and Social Network Metadata
Tobia Tesan, Pasquale Coscia, Lamberto Ballan

Auto-TLDR; Context-Based Image Annotation with Multiple Semantic Embeddings and Recurrent Neural Networks
Abstract Slides Poster Similar
Beyond the Deep Metric Learning: Enhance the Cross-Modal Matching with Adversarial Discriminative Domain Regularization
Li Ren, Kai Li, Liqiang Wang, Kien Hua

Auto-TLDR; Adversarial Discriminative Domain Regularization for Efficient Cross-Modal Matching
Abstract Slides Poster Similar
Embedding Shared Low-Rank and Feature Correlation for Multi-View Data Analysis
Zhan Wang, Lizhi Wang, Hua Huang

Auto-TLDR; embedding shared low-rank and feature correlation for multi-view data analysis
Abstract Slides Poster Similar
Transformer Reasoning Network for Image-Text Matching and Retrieval
Nicola Messina, Fabrizio Falchi, Andrea Esuli, Giuseppe Amato

Auto-TLDR; A Transformer Encoder Reasoning Network for Image-Text Matching in Large-Scale Information Retrieval
Abstract Slides Poster Similar
VSR++: Improving Visual Semantic Reasoning for Fine-Grained Image-Text Matching
Hui Yuan, Yan Huang, Dongbo Zhang, Zerui Chen, Wenlong Cheng, Liang Wang

Auto-TLDR; Improving Visual Semantic Reasoning for Fine-Grained Image-Text Matching
Abstract Slides Poster Similar
A Novel Attention-Based Aggregation Function to Combine Vision and Language
Matteo Stefanini, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara

Auto-TLDR; Fully-Attentive Reduction for Vision and Language
Abstract Slides Poster Similar
Fast Discrete Cross-Modal Hashing Based on Label Relaxation and Matrix Factorization
Donglin Zhang, Xiaojun Wu, Zhen Liu, Jun Yu, Josef Kittler

Auto-TLDR; LRMF: Label Relaxation and Discrete Matrix Factorization for Cross-Modal Retrieval
Cross-Media Hash Retrieval Using Multi-head Attention Network
Zhixin Li, Feng Ling, Chuansheng Xu, Canlong Zhang, Huifang Ma

Auto-TLDR; Unsupervised Cross-Media Hash Retrieval Using Multi-Head Attention Network
Abstract Slides Poster Similar
Discrete Semantic Matrix Factorization Hashing for Cross-Modal Retrieval
Jianyang Qin, Lunke Fei, Shaohua Teng, Wei Zhang, Genping Zhao, Haoliang Yuan

Auto-TLDR; Discrete Semantic Matrix Factorization Hashing for Cross-Modal Retrieval
Abstract Slides Poster Similar
Tensorized Feature Spaces for Feature Explosion
Ravdeep Pasricha, Pravallika Devineni, Evangelos Papalexakis, Ramakrishnan Kannan

Auto-TLDR; Tensor Rank Decomposition for Hyperspectral Image Classification
Abstract Slides Poster Similar
T-SVD Based Non-Convex Tensor Completion and Robust Principal Component Analysis

Auto-TLDR; Non-Convex tensor rank surrogate function and non-convex sparsity measure for tensor recovery
Abstract Slides Poster Similar
Making Every Label Count: Handling Semantic Imprecision by Integrating Domain Knowledge
Clemens-Alexander Brust, Björn Barz, Joachim Denzler

Auto-TLDR; Class Hierarchies for Imprecise Label Learning and Annotation eXtrapolation
Abstract Slides Poster Similar
Enriching Video Captions with Contextual Text
Philipp Rimle, Pelin Dogan, Markus Gross

Auto-TLDR; Contextualized Video Captioning Using Contextual Text
Abstract Slides Poster Similar
Cross-Supervised Joint-Event-Extraction with Heterogeneous Information Networks
Yue Wang, Zhuo Xu, Yao Wan, Lu Bai, Lixin Cui, Qian Zhao, Edwin Hancock, Philip Yu

Auto-TLDR; Joint-Event-extraction from Unstructured corpora using Structural Information Network
Abstract Slides Poster Similar
Text Synopsis Generation for Egocentric Videos
Aidean Sharghi, Niels Lobo, Mubarak Shah

Auto-TLDR; Egocentric Video Summarization Using Multi-task Learning for End-to-End Learning
RWMF: A Real-World Multimodal Foodlog Database
Pengfei Zhou, Cong Bai, Kaining Ying, Jie Xia, Lixin Huang
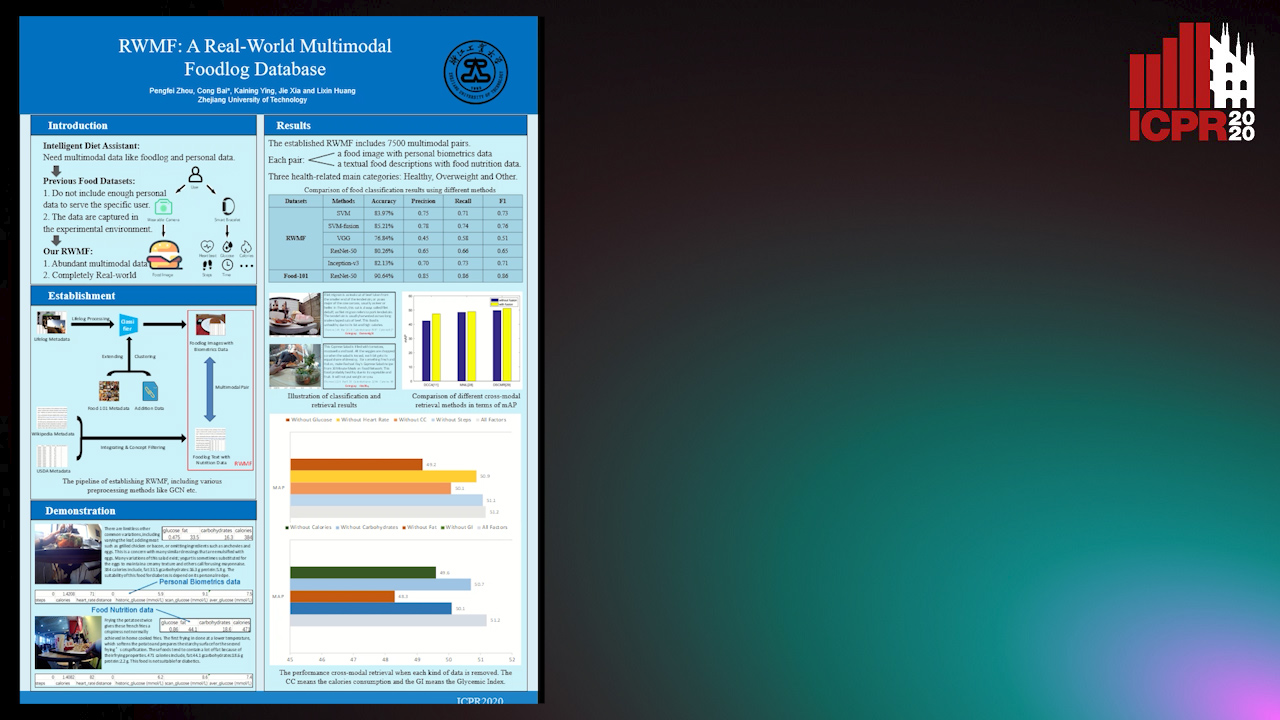
Auto-TLDR; Real-World Multimodal Foodlog: A Real-World Foodlog Database for Diet Assistant
Abstract Slides Poster Similar
Multi-Scale 2D Representation Learning for Weakly-Supervised Moment Retrieval
Ding Li, Rui Wu, Zhizhong Zhang, Yongqiang Tang, Wensheng Zhang

Auto-TLDR; Multi-scale 2D Representation Learning for Weakly Supervised Video Moment Retrieval
Abstract Slides Poster Similar
Enhanced User Interest and Expertise Modeling for Expert Recommendation
Tongze He, Caili Guo, Yunfei Chu

Auto-TLDR; A Unified Framework for Expert Recommendation in Community Question Answering
Abstract Slides Poster Similar
Dual Path Multi-Modal High-Order Features for Textual Content Based Visual Question Answering
Yanan Li, Yuetan Lin, Hongrui Zhao, Donghui Wang

Auto-TLDR; TextVQA: An End-to-End Visual Question Answering Model for Text-Based VQA
Probabilistic Latent Factor Model for Collaborative Filtering with Bayesian Inference
Jiansheng Fang, Xiaoqing Zhang, Yan Hu, Yanwu Xu, Ming Yang, Jiang Liu

Auto-TLDR; Bayesian Latent Factor Model for Collaborative Filtering
MEG: Multi-Evidence GNN for Multimodal Semantic Forensics
Ekraam Sabir, Ayush Jaiswal, Wael Abdalmageed, Prem Natarajan

Auto-TLDR; Scalable Image Repurposing Detection with Graph Neural Network Based Model
Abstract Slides Poster Similar
Context Visual Information-Based Deliberation Network for Video Captioning
Min Lu, Xueyong Li, Caihua Liu

Auto-TLDR; Context visual information-based deliberation network for video captioning
Abstract Slides Poster Similar
Picture-To-Amount (PITA): Predicting Relative Ingredient Amounts from Food Images
Jiatong Li, Fangda Han, Ricardo Guerrero, Vladimir Pavlovic

Auto-TLDR; PITA: A Deep Learning Architecture for Predicting the Relative Amount of Ingredients from Food Images
Abstract Slides Poster Similar
MAGNet: Multi-Region Attention-Assisted Grounding of Natural Language Queries at Phrase Level
Amar Shrestha, Krittaphat Pugdeethosapol, Haowen Fang, Qinru Qiu

Auto-TLDR; MAGNet: A Multi-Region Attention-Aware Grounding Network for Free-form Textual Queries
Abstract Slides Poster Similar
Double Manifolds Regularized Non-Negative Matrix Factorization for Data Representation
Jipeng Guo, Shuai Yin, Yanfeng Sun, Yongli Hu

Auto-TLDR; Double Manifolds Regularized Non-negative Matrix Factorization for Clustering
Abstract Slides Poster Similar
Information Graphic Summarization Using a Collection of Multimodal Deep Neural Networks
Edward Kim, Connor Onweller, Kathleen F. Mccoy

Auto-TLDR; A multimodal deep learning framework that can generate summarization text supporting the main idea of an information graphic for presentation to blind or visually impaired
RGB-Infrared Person Re-Identification Via Image Modality Conversion
Huangpeng Dai, Qing Xie, Yanchun Ma, Yongjian Liu, Shengwu Xiong

Auto-TLDR; CE2L: A Novel Network for Cross-Modality Re-identification with Feature Alignment
Abstract Slides Poster Similar
More Correlations Better Performance: Fully Associative Networks for Multi-Label Image Classification

Auto-TLDR; Fully Associative Network for Fully Exploiting Correlation Information in Multi-Label Classification
Abstract Slides Poster Similar
Attentive Visual Semantic Specialized Network for Video Captioning
Jesus Perez-Martin, Benjamin Bustos, Jorge Pérez

Auto-TLDR; Adaptive Visual Semantic Specialized Network for Video Captioning
Abstract Slides Poster Similar
Unsupervised Co-Segmentation for Athlete Movements and Live Commentaries Using Crossmodal Temporal Proximity
Yasunori Ohishi, Yuki Tanaka, Kunio Kashino

Auto-TLDR; A guided attention scheme for audio-visual co-segmentation
Abstract Slides Poster Similar
Soft Label and Discriminant Embedding Estimation for Semi-Supervised Classification
Fadi Dornaika, Abdullah Baradaaji, Youssof El Traboulsi

Auto-TLDR; Semi-supervised Semi-Supervised Learning for Linear Feature Extraction and Label Propagation
Abstract Slides Poster Similar
Exploiting Elasticity in Tensor Ranks for Compressing Neural Networks
Jie Ran, Rui Lin, Hayden Kwok-Hay So, Graziano Chesi, Ngai Wong

Auto-TLDR; Nuclear-Norm Rank Minimization Factorization for Deep Neural Networks
Abstract Slides Poster Similar
Multi-Task Learning for Calorie Prediction on a Novel Large-Scale Recipe Dataset Enriched with Nutritional Information
Robin Ruede, Verena Heusser, Lukas Frank, Monica Haurilet, Alina Roitberg, Rainer Stiefelhagen

Auto-TLDR; Pic2kcal: Learning Food Recipes from Images for Calorie Estimation
Abstract Slides Poster Similar
Temporal Collaborative Filtering with Graph Convolutional Neural Networks
Esther Rodrigo-Bonet, Minh Duc Nguyen, Nikos Deligiannis

Auto-TLDR; Temporal Collaborative Filtering with Graph-Neural-Network-based Neural Networks
Abstract Slides Poster Similar
Low Rank Representation on Product Grassmann Manifolds for Multi-viewSubspace Clustering
Jipeng Guo, Yanfeng Sun, Junbin Gao, Yongli Hu, Baocai Yin

Auto-TLDR; Low Rank Representation on Product Grassmann Manifold for Multi-View Data Clustering
Abstract Slides Poster Similar
VSB^2-Net: Visual-Semantic Bi-Branch Network for Zero-Shot Hashing
Xin Li, Xiangfeng Wang, Bo Jin, Wenjie Zhang, Jun Wang, Hongyuan Zha

Auto-TLDR; VSB^2-Net: inductive zero-shot hashing for image retrieval
Abstract Slides Poster Similar
Equation Attention Relationship Network (EARN) : A Geometric Deep Metric Framework for Learning Similar Math Expression Embedding
Saleem Ahmed, Kenny Davila, Srirangaraj Setlur, Venu Govindaraju

Auto-TLDR; Representational Learning for Similarity Based Retrieval of Mathematical Expressions
Abstract Slides Poster Similar
Label Incorporated Graph Neural Networks for Text Classification
Yuan Xin, Linli Xu, Junliang Guo, Jiquan Li, Xin Sheng, Yuanyuan Zhou

Auto-TLDR; Graph Neural Networks for Semi-supervised Text Classification
Abstract Slides Poster Similar
Supervised Domain Adaptation Using Graph Embedding
Lukas Hedegaard, Omar Ali Sheikh-Omar, Alexandros Iosifidis

Auto-TLDR; Domain Adaptation from the Perspective of Multi-view Graph Embedding and Dimensionality Reduction
Abstract Slides Poster Similar
Multi-Modal Deep Clustering: Unsupervised Partitioning of Images

Auto-TLDR; Multi-Modal Deep Clustering for Unlabeled Images
Abstract Slides Poster Similar
Transformer Networks for Trajectory Forecasting
Francesco Giuliari, Hasan Irtiza, Marco Cristani, Fabio Galasso

Auto-TLDR; TransformerNetworks for Trajectory Prediction of People Interactions
Abstract Slides Poster Similar
Joint Supervised and Self-Supervised Learning for 3D Real World Challenges
Antonio Alliegro, Davide Boscaini, Tatiana Tommasi

Auto-TLDR; Self-supervision for 3D Shape Classification and Segmentation in Point Clouds
PICK: Processing Key Information Extraction from Documents Using Improved Graph Learning-Convolutional Networks
Wenwen Yu, Ning Lu, Xianbiao Qi, Ping Gong, Rong Xiao

Auto-TLDR; PICK: A Graph Learning Framework for Key Information Extraction from Documents
Abstract Slides Poster Similar
Adaptive L2 Regularization in Person Re-Identification
Xingyang Ni, Liang Fang, Heikki Juhani Huttunen

Auto-TLDR; AdaptiveReID: Adaptive L2 Regularization for Person Re-identification
Abstract Slides Poster Similar
Deep Convolutional Embedding for Digitized Painting Clustering
Giovanna Castellano, Gennaro Vessio

Auto-TLDR; A Deep Convolutional Embedding Model for Clustering Artworks
Abstract Slides Poster Similar
Person Recognition with HGR Maximal Correlation on Multimodal Data
Yihua Liang, Fei Ma, Yang Li, Shao-Lun Huang

Auto-TLDR; A correlation-based multimodal person recognition framework that learns discriminative embeddings of persons by joint learning visual features and audio features
Abstract Slides Poster Similar
Text Recognition - Real World Data and Where to Find Them
Klára Janoušková, Lluis Gomez, Dimosthenis Karatzas, Jiri Matas

Auto-TLDR; Exploiting Weakly Annotated Images for Text Extraction
Abstract Slides Poster Similar