Fast Discrete Cross-Modal Hashing Based on Label Relaxation and Matrix Factorization
Donglin Zhang,
Xiaojun Wu,
Zhen Liu,
Jun Yu,
Josef Kittler

Auto-TLDR; LRMF: Label Relaxation and Discrete Matrix Factorization for Cross-Modal Retrieval
Similar papers
Discrete Semantic Matrix Factorization Hashing for Cross-Modal Retrieval
Jianyang Qin, Lunke Fei, Shaohua Teng, Wei Zhang, Genping Zhao, Haoliang Yuan

Auto-TLDR; Discrete Semantic Matrix Factorization Hashing for Cross-Modal Retrieval
Abstract Slides Poster Similar
Cross-Media Hash Retrieval Using Multi-head Attention Network
Zhixin Li, Feng Ling, Chuansheng Xu, Canlong Zhang, Huifang Ma

Auto-TLDR; Unsupervised Cross-Media Hash Retrieval Using Multi-Head Attention Network
Abstract Slides Poster Similar
Object Classification of Remote Sensing Images Based on Optimized Projection Supervised Discrete Hashing
Qianqian Zhang, Yazhou Liu, Quansen Sun

Auto-TLDR; Optimized Projection Supervised Discrete Hashing for Large-Scale Remote Sensing Image Object Classification
Abstract Slides Poster Similar
Hierarchical Deep Hashing for Fast Large Scale Image Retrieval
Yongfei Zhang, Cheng Peng, Zhang Jingtao, Xianglong Liu, Shiliang Pu, Changhuai Chen

Auto-TLDR; Hierarchical indexed deep hashing for fast large scale image retrieval
Abstract Slides Poster Similar
VSB^2-Net: Visual-Semantic Bi-Branch Network for Zero-Shot Hashing
Xin Li, Xiangfeng Wang, Bo Jin, Wenjie Zhang, Jun Wang, Hongyuan Zha

Auto-TLDR; VSB^2-Net: inductive zero-shot hashing for image retrieval
Abstract Slides Poster Similar
Label Self-Adaption Hashing for Image Retrieval
Jianglin Lu, Zhihui Lai, Hailing Wang, Jie Zhou

Auto-TLDR; Label Self-Adaption Hashing for Large-Scale Image Retrieval
Abstract Slides Poster Similar
Improved Deep Classwise Hashing with Centers Similarity Learning for Image Retrieval

Auto-TLDR; Deep Classwise Hashing for Image Retrieval Using Center Similarity Learning
Abstract Slides Poster Similar
Cross-spectrum Face Recognition Using Subspace Projection Hashing
Hanrui Wang, Xingbo Dong, Jin Zhe, Jean-Luc Dugelay, Massimo Tistarelli

Auto-TLDR; Subspace Projection Hashing for Cross-Spectrum Face Recognition
Abstract Slides Poster Similar
DFH-GAN: A Deep Face Hashing with Generative Adversarial Network
Bo Xiao, Lanxiang Zhou, Yifei Wang, Qiangfang Xu

Auto-TLDR; Deep Face Hashing with GAN for Face Image Retrieval
Abstract Slides Poster Similar
Leveraging Quadratic Spherical Mutual Information Hashing for Fast Image Retrieval
Nikolaos Passalis, Anastasios Tefas

Auto-TLDR; Quadratic Mutual Information for Large-Scale Hashing and Information Retrieval
Abstract Slides Poster Similar
Double Manifolds Regularized Non-Negative Matrix Factorization for Data Representation
Jipeng Guo, Shuai Yin, Yanfeng Sun, Yongli Hu

Auto-TLDR; Double Manifolds Regularized Non-negative Matrix Factorization for Clustering
Abstract Slides Poster Similar
Low Rank Representation on Product Grassmann Manifolds for Multi-viewSubspace Clustering
Jipeng Guo, Yanfeng Sun, Junbin Gao, Yongli Hu, Baocai Yin

Auto-TLDR; Low Rank Representation on Product Grassmann Manifold for Multi-View Data Clustering
Abstract Slides Poster Similar
Embedding Shared Low-Rank and Feature Correlation for Multi-View Data Analysis
Zhan Wang, Lizhi Wang, Hua Huang

Auto-TLDR; embedding shared low-rank and feature correlation for multi-view data analysis
Abstract Slides Poster Similar
Webly Supervised Image-Text Embedding with Noisy Tag Refinement
Niluthpol Mithun, Ravdeep Pasricha, Evangelos Papalexakis, Amit Roy-Chowdhury

Auto-TLDR; Robust Joint Embedding for Image-Text Retrieval Using Web Images
Exploiting Local Indexing and Deep Feature Confidence Scores for Fast Image-To-Video Search
Savas Ozkan, Gözde Bozdağı Akar

Auto-TLDR; Fast and Robust Image-to-Video Retrieval Using Local and Global Descriptors
Abstract Slides Poster Similar
Joint Learning Multiple Curvature Descriptor for 3D Palmprint Recognition
Lunke Fei, Bob Zhang, Jie Wen, Chunwei Tian, Peng Liu, Shuping Zhao

Auto-TLDR; Joint Feature Learning for 3D palmprint recognition using curvature data vectors
Abstract Slides Poster Similar
A Spectral Clustering on Grassmann Manifold Via Double Low Rank Constraint
Xinglin Piao, Yongli Hu, Junbin Gao, Yanfeng Sun, Xin Yang, Baocai Yin

Auto-TLDR; Double Low Rank Representation for High-Dimensional Data Clustering on Grassmann Manifold
Fast Subspace Clustering Based on the Kronecker Product
Lei Zhou, Xiao Bai, Liang Zhang, Jun Zhou, Edwin Hancock

Auto-TLDR; Subspace Clustering with Kronecker Product for Large Scale Datasets
Abstract Slides Poster Similar
Feature Extraction by Joint Robust Discriminant Analysis and Inter-Class Sparsity

Auto-TLDR; Robust Discriminant Analysis with Feature Selection and Inter-class Sparsity (RDA_FSIS)
RGB-Infrared Person Re-Identification Via Image Modality Conversion
Huangpeng Dai, Qing Xie, Yanchun Ma, Yongjian Liu, Shengwu Xiong

Auto-TLDR; CE2L: A Novel Network for Cross-Modality Re-identification with Feature Alignment
Abstract Slides Poster Similar
JECL: Joint Embedding and Cluster Learning for Image-Text Pairs
Sean Yang, Kuan-Hao Huang, Bill Howe

Auto-TLDR; JECL: Clustering Image-Caption Pairs with Parallel Encoders and Regularized Clusters
Subspace Clustering Via Joint Unsupervised Feature Selection
Wenhua Dong, Xiaojun Wu, Hui Li, Zhenhua Feng, Josef Kittler

Auto-TLDR; Unsupervised Feature Selection for Subspace Clustering
Deep Composer: A Hash-Based Duplicative Neural Network for Generating Multi-Instrument Songs
Jacob Galajda, Brandon Royal, Kien Hua

Auto-TLDR; Deep Composer for Intelligence Duplication
Probabilistic Latent Factor Model for Collaborative Filtering with Bayesian Inference
Jiansheng Fang, Xiaoqing Zhang, Yan Hu, Yanwu Xu, Ming Yang, Jiang Liu

Auto-TLDR; Bayesian Latent Factor Model for Collaborative Filtering
More Correlations Better Performance: Fully Associative Networks for Multi-Label Image Classification

Auto-TLDR; Fully Associative Network for Fully Exploiting Correlation Information in Multi-Label Classification
Abstract Slides Poster Similar
Soft Label and Discriminant Embedding Estimation for Semi-Supervised Classification
Fadi Dornaika, Abdullah Baradaaji, Youssof El Traboulsi

Auto-TLDR; Semi-supervised Semi-Supervised Learning for Linear Feature Extraction and Label Propagation
Abstract Slides Poster Similar
Beyond the Deep Metric Learning: Enhance the Cross-Modal Matching with Adversarial Discriminative Domain Regularization
Li Ren, Kai Li, Liqiang Wang, Kien Hua

Auto-TLDR; Adversarial Discriminative Domain Regularization for Efficient Cross-Modal Matching
Abstract Slides Poster Similar
Feature Extraction and Selection Via Robust Discriminant Analysis and Class Sparsity

Auto-TLDR; Hybrid Linear Discriminant Embedding for supervised multi-class classification
Abstract Slides Poster Similar
Learning Sign-Constrained Support Vector Machines
Kenya Tajima, Kouhei Tsuchida, Esmeraldo Ronnie Rey Zara, Naoya Ohta, Tsuyoshi Kato

Auto-TLDR; Constrained Sign Constraints for Learning Linear Support Vector Machine
Multi-Scale Cascading Network with Compact Feature Learning for RGB-Infrared Person Re-Identification
Can Zhang, Hong Liu, Wei Guo, Mang Ye

Auto-TLDR; Multi-Scale Part-Aware Cascading for RGB-Infrared Person Re-identification
Abstract Slides Poster Similar
Hybrid Decomposition Convolution Neural Network and Vocabulary Forest for Image Retrieval
Djenouri Youcef, Jon Hjelmervik
Auto-TLDR; DCNN-vForest: Convolutional Neural Network and Vocabulary Forest for Efficient Image Retrieval
Abstract Slides Poster Similar
SoftmaxOut Transformation-Permutation Network for Facial Template Protection
Hakyoung Lee, Cheng Yaw Low, Andrew Teoh

Auto-TLDR; SoftmaxOut Transformation-Permutation Network for C cancellable Biometrics
Abstract Slides Poster Similar
Attention-Based Deep Metric Learning for Near-Duplicate Video Retrieval
Kuan-Hsun Wang, Chia Chun Cheng, Yi-Ling Chen, Yale Song, Shang-Hong Lai

Auto-TLDR; Attention-based Deep Metric Learning for Near-duplicate Video Retrieval
Price Suggestion for Online Second-Hand Items
Liang Han, Zhaozheng Yin, Zhurong Xia, Li Guo, Mingqian Tang, Rong Jin
Auto-TLDR; An Intelligent Price Suggestion System for Online Second-hand Items
Abstract Slides Poster Similar
A Base-Derivative Framework for Cross-Modality RGB-Infrared Person Re-Identification
Hong Liu, Ziling Miao, Bing Yang, Runwei Ding

Auto-TLDR; Cross-modality RGB-Infrared Person Re-identification with Auxiliary Modalities
Abstract Slides Poster Similar
Edge-Aware Graph Attention Network for Ratio of Edge-User Estimation in Mobile Networks
Jiehui Deng, Sheng Wan, Xiang Wang, Enmei Tu, Xiaolin Huang, Jie Yang, Chen Gong

Auto-TLDR; EAGAT: Edge-Aware Graph Attention Network for Automatic REU Estimation in Mobile Networks
Abstract Slides Poster Similar
RWMF: A Real-World Multimodal Foodlog Database
Pengfei Zhou, Cong Bai, Kaining Ying, Jie Xia, Lixin Huang
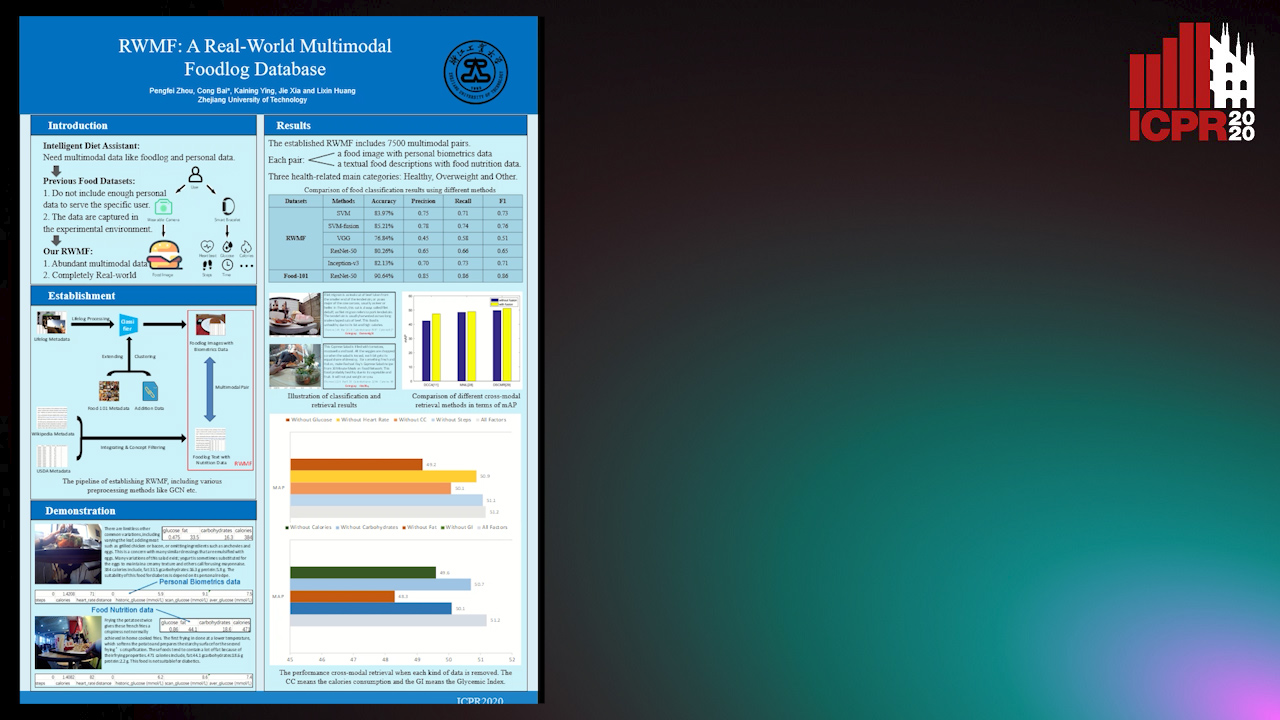
Auto-TLDR; Real-World Multimodal Foodlog: A Real-World Foodlog Database for Diet Assistant
Abstract Slides Poster Similar
Sketch-Based Community Detection Via Representative Node Sampling
Mahlagha Sedghi, Andre Beckus, George Atia

Auto-TLDR; Sketch-based Clustering of Community Detection Using a Small Sketch
Abstract Slides Poster Similar
Scalable Direction-Search-Based Approach to Subspace Clustering

Auto-TLDR; Fast Direction-Search-Based Subspace Clustering
A Multi-Task Multi-View Based Multi-Objective Clustering Algorithm

Auto-TLDR; MTMV-MO: Multi-task multi-view multi-objective optimization for multi-task clustering
Abstract Slides Poster Similar
Video Episode Boundary Detection with Joint Episode-Topic Model
Shunyao Wang, Ye Tian, Ruidong Wang, Yang Du, Han Yan, Ruilin Yang, Jian Ma

Auto-TLDR; Unsupervised Video Episode Boundary Detection for Bullet Screen Comment Video
Abstract Slides Poster Similar
Interactive Style Space of Deep Features and Style Innovation

Auto-TLDR; Interactive Style Space of Convolutional Neural Network Features
Abstract Slides Poster Similar
Audio-Based Near-Duplicate Video Retrieval with Audio Similarity Learning
Pavlos Avgoustinakis, Giorgos Kordopatis-Zilos, Symeon Papadopoulos, Andreas L. Symeonidis, Ioannis Kompatsiaris

Auto-TLDR; AuSiL: Audio Similarity Learning for Near-duplicate Video Retrieval
Abstract Slides Poster Similar
Deep Convolutional Embedding for Digitized Painting Clustering
Giovanna Castellano, Gennaro Vessio

Auto-TLDR; A Deep Convolutional Embedding Model for Clustering Artworks
Abstract Slides Poster Similar
Context Visual Information-Based Deliberation Network for Video Captioning
Min Lu, Xueyong Li, Caihua Liu

Auto-TLDR; Context visual information-based deliberation network for video captioning
Abstract Slides Poster Similar
Supporting Skin Lesion Diagnosis with Content-Based Image Retrieval
Stefano Allegretti, Federico Bolelli, Federico Pollastri, Sabrina Longhitano, Giovanni Pellacani, Costantino Grana

Auto-TLDR; Skin Images Retrieval Using Convolutional Neural Networks for Skin Lesion Classification and Segmentation
Abstract Slides Poster Similar
A Unified Framework for Distance-Aware Domain Adaptation
Fei Wang, Youdong Ding, Huan Liang, Yuzhen Gao, Wenqi Che

Auto-TLDR; distance-aware domain adaptation
Abstract Slides Poster Similar
Cancelable Biometrics Vault: A Secure Key-Binding Biometric Cryptosystem Based on Chaffing and Winnowing
Osama Ouda, Karthik Nandakumar, Arun Ross

Auto-TLDR; Cancelable Biometrics Vault for Key-binding Biometric Cryptosystem Framework
Abstract Slides Poster Similar