Hybrid Decomposition Convolution Neural Network and Vocabulary Forest for Image Retrieval
Djenouri Youcef,
Jon Hjelmervik
Auto-TLDR; DCNN-vForest: Convolutional Neural Network and Vocabulary Forest for Efficient Image Retrieval
Similar papers
Hierarchical Deep Hashing for Fast Large Scale Image Retrieval
Yongfei Zhang, Cheng Peng, Zhang Jingtao, Xianglong Liu, Shiliang Pu, Changhuai Chen

Auto-TLDR; Hierarchical indexed deep hashing for fast large scale image retrieval
Abstract Slides Poster Similar
Exploiting Local Indexing and Deep Feature Confidence Scores for Fast Image-To-Video Search
Savas Ozkan, Gözde Bozdağı Akar

Auto-TLDR; Fast and Robust Image-to-Video Retrieval Using Local and Global Descriptors
Abstract Slides Poster Similar
Deep Convolutional Embedding for Digitized Painting Clustering
Giovanna Castellano, Gennaro Vessio

Auto-TLDR; A Deep Convolutional Embedding Model for Clustering Artworks
Abstract Slides Poster Similar
Leveraging Quadratic Spherical Mutual Information Hashing for Fast Image Retrieval
Nikolaos Passalis, Anastasios Tefas

Auto-TLDR; Quadratic Mutual Information for Large-Scale Hashing and Information Retrieval
Abstract Slides Poster Similar
A CNN-RNN Framework for Image Annotation from Visual Cues and Social Network Metadata
Tobia Tesan, Pasquale Coscia, Lamberto Ballan

Auto-TLDR; Context-Based Image Annotation with Multiple Semantic Embeddings and Recurrent Neural Networks
Abstract Slides Poster Similar
Attention-Based Deep Metric Learning for Near-Duplicate Video Retrieval
Kuan-Hsun Wang, Chia Chun Cheng, Yi-Ling Chen, Yale Song, Shang-Hong Lai

Auto-TLDR; Attention-based Deep Metric Learning for Near-duplicate Video Retrieval
Discrete Semantic Matrix Factorization Hashing for Cross-Modal Retrieval
Jianyang Qin, Lunke Fei, Shaohua Teng, Wei Zhang, Genping Zhao, Haoliang Yuan

Auto-TLDR; Discrete Semantic Matrix Factorization Hashing for Cross-Modal Retrieval
Abstract Slides Poster Similar
Comparison of Deep Learning and Hand Crafted Features for Mining Simulation Data
Theodoros Georgiou, Sebastian Schmitt, Thomas Baeck, Nan Pu, Wei Chen, Michael Lew

Auto-TLDR; Automated Data Analysis of Flow Fields in Computational Fluid Dynamics Simulations
Abstract Slides Poster Similar
RWMF: A Real-World Multimodal Foodlog Database
Pengfei Zhou, Cong Bai, Kaining Ying, Jie Xia, Lixin Huang
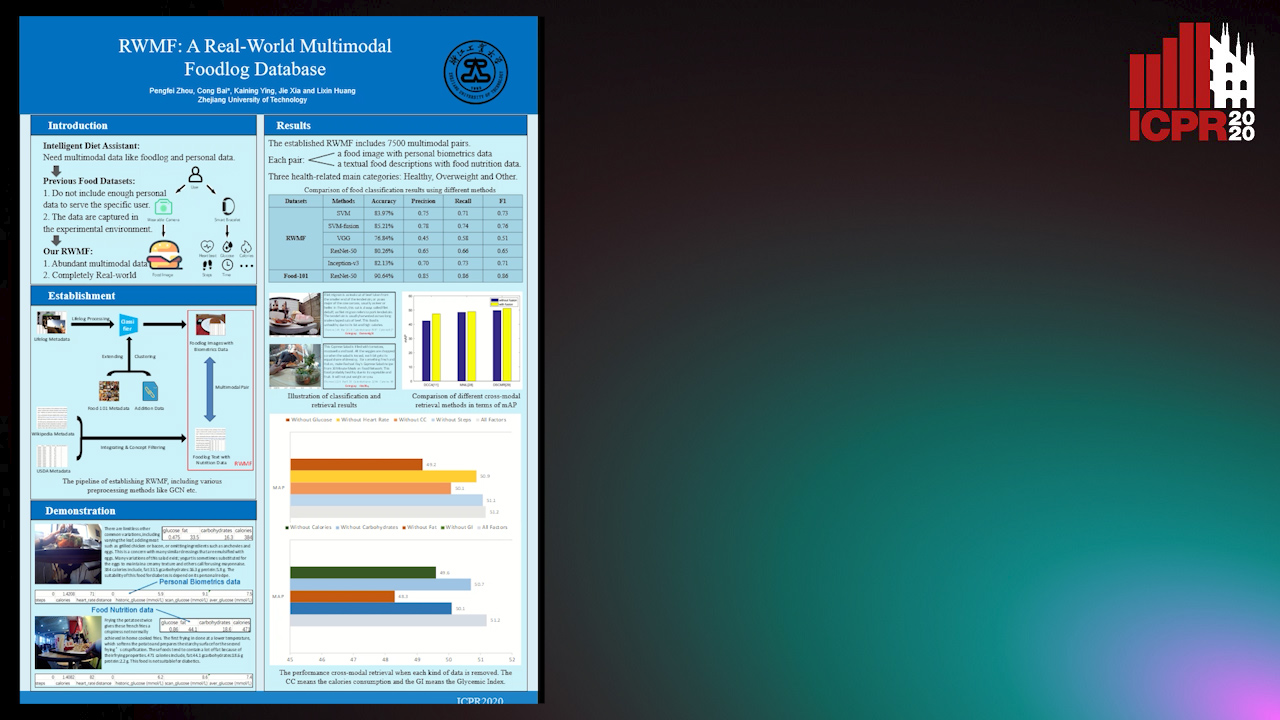
Auto-TLDR; Real-World Multimodal Foodlog: A Real-World Foodlog Database for Diet Assistant
Abstract Slides Poster Similar
Cross-Media Hash Retrieval Using Multi-head Attention Network
Zhixin Li, Feng Ling, Chuansheng Xu, Canlong Zhang, Huifang Ma

Auto-TLDR; Unsupervised Cross-Media Hash Retrieval Using Multi-Head Attention Network
Abstract Slides Poster Similar
Supporting Skin Lesion Diagnosis with Content-Based Image Retrieval
Stefano Allegretti, Federico Bolelli, Federico Pollastri, Sabrina Longhitano, Giovanni Pellacani, Costantino Grana

Auto-TLDR; Skin Images Retrieval Using Convolutional Neural Networks for Skin Lesion Classification and Segmentation
Abstract Slides Poster Similar
VSB^2-Net: Visual-Semantic Bi-Branch Network for Zero-Shot Hashing
Xin Li, Xiangfeng Wang, Bo Jin, Wenjie Zhang, Jun Wang, Hongyuan Zha

Auto-TLDR; VSB^2-Net: inductive zero-shot hashing for image retrieval
Abstract Slides Poster Similar
Self-Supervised Learning with Graph Neural Networks for Region of Interest Retrieval in Histopathology
Yigit Ozen, Selim Aksoy, Kemal Kosemehmetoglu, Sevgen Onder, Aysegul Uner

Auto-TLDR; Self-supervised Contrastive Learning for Deep Representation Learning of Histopathology Images
Abstract Slides Poster Similar
Fast Discrete Cross-Modal Hashing Based on Label Relaxation and Matrix Factorization
Donglin Zhang, Xiaojun Wu, Zhen Liu, Jun Yu, Josef Kittler

Auto-TLDR; LRMF: Label Relaxation and Discrete Matrix Factorization for Cross-Modal Retrieval
Multimodal Side-Tuning for Document Classification
Stefano Zingaro, Giuseppe Lisanti, Maurizio Gabbrielli

Auto-TLDR; Side-tuning for Multimodal Document Classification
Abstract Slides Poster Similar
Visual Localization for Autonomous Driving: Mapping the Accurate Location in the City Maze
Dongfang Liu, Yiming Cui, Xiaolei Guo, Wei Ding, Baijian Yang, Yingjie Chen

Auto-TLDR; Feature Voting for Robust Visual Localization in Urban Settings
Abstract Slides Poster Similar
Audio-Based Near-Duplicate Video Retrieval with Audio Similarity Learning
Pavlos Avgoustinakis, Giorgos Kordopatis-Zilos, Symeon Papadopoulos, Andreas L. Symeonidis, Ioannis Kompatsiaris

Auto-TLDR; AuSiL: Audio Similarity Learning for Near-duplicate Video Retrieval
Abstract Slides Poster Similar
One Step Clustering Based on A-Contrario Framework for Detection of Alterations in Historical Violins
Alireza Rezaei, Sylvie Le Hégarat-Mascle, Emanuel Aldea, Piercarlo Dondi, Marco Malagodi

Auto-TLDR; A-Contrario Clustering for the Detection of Altered Violins using UVIFL Images
Abstract Slides Poster Similar
Improved Deep Classwise Hashing with Centers Similarity Learning for Image Retrieval

Auto-TLDR; Deep Classwise Hashing for Image Retrieval Using Center Similarity Learning
Abstract Slides Poster Similar
Aggregating Object Features Based on Attention Weights for Fine-Grained Image Retrieval
Hongli Lin, Yongqi Song, Zixuan Zeng, Weisheng Wang

Auto-TLDR; DSAW: Unsupervised Dual-selection for Fine-Grained Image Retrieval
Creating Classifier Ensembles through Meta-Heuristic Algorithms for Aerial Scene Classification
Álvaro Roberto Ferreira Jr., Gustavo Gustavo Henrique De Rosa, Joao Paulo Papa, Gustavo Carneiro, Fabio Augusto Faria

Auto-TLDR; Univariate Marginal Distribution Algorithm for Aerial Scene Classification Using Meta-Heuristic Optimization
Abstract Slides Poster Similar
ILS-SUMM: Iterated Local Search for Unsupervised Video Summarization
Yair Shemer, Daniel Rotman, Nahum Shimkin

Auto-TLDR; ILS-SUMM: Iterated Local Search for Video Summarization
A Multi-Task Multi-View Based Multi-Objective Clustering Algorithm

Auto-TLDR; MTMV-MO: Multi-task multi-view multi-objective optimization for multi-task clustering
Abstract Slides Poster Similar
More Correlations Better Performance: Fully Associative Networks for Multi-Label Image Classification

Auto-TLDR; Fully Associative Network for Fully Exploiting Correlation Information in Multi-Label Classification
Abstract Slides Poster Similar
JECL: Joint Embedding and Cluster Learning for Image-Text Pairs
Sean Yang, Kuan-Hao Huang, Bill Howe

Auto-TLDR; JECL: Clustering Image-Caption Pairs with Parallel Encoders and Regularized Clusters
Multi-Modal Deep Clustering: Unsupervised Partitioning of Images

Auto-TLDR; Multi-Modal Deep Clustering for Unlabeled Images
Abstract Slides Poster Similar
RGB-Infrared Person Re-Identification Via Image Modality Conversion
Huangpeng Dai, Qing Xie, Yanchun Ma, Yongjian Liu, Shengwu Xiong

Auto-TLDR; CE2L: A Novel Network for Cross-Modality Re-identification with Feature Alignment
Abstract Slides Poster Similar
Rotation Invariant Aerial Image Retrieval with Group Convolutional Metric Learning
Hyunseung Chung, Woo-Jeoung Nam, Seong-Whan Lee

Auto-TLDR; Robust Remote Sensing Image Retrieval Using Group Convolution with Attention Mechanism and Metric Learning
Abstract Slides Poster Similar
Writer Identification Using Deep Neural Networks: Impact of Patch Size and Number of Patches
Akshay Punjabi, José Ramón Prieto Fontcuberta, Enrique Vidal

Auto-TLDR; Writer Recognition Using Deep Neural Networks for Handwritten Text Images
Abstract Slides Poster Similar
Enhancing Deep Semantic Segmentation of RGB-D Data with Entangled Forests
Matteo Terreran, Elia Bonetto, Stefano Ghidoni

Auto-TLDR; FuseNet: A Lighter Deep Learning Model for Semantic Segmentation
Abstract Slides Poster Similar
Price Suggestion for Online Second-Hand Items
Liang Han, Zhaozheng Yin, Zhurong Xia, Li Guo, Mingqian Tang, Rong Jin
Auto-TLDR; An Intelligent Price Suggestion System for Online Second-hand Items
Abstract Slides Poster Similar
Picture-To-Amount (PITA): Predicting Relative Ingredient Amounts from Food Images
Jiatong Li, Fangda Han, Ricardo Guerrero, Vladimir Pavlovic

Auto-TLDR; PITA: A Deep Learning Architecture for Predicting the Relative Amount of Ingredients from Food Images
Abstract Slides Poster Similar
ClusterFace: Joint Clustering and Classification for Set-Based Face Recognition
Samadhi Poornima Kumarasinghe Wickrama Arachchilage, Ebroul Izquierdo

Auto-TLDR; Joint Clustering and Classification for Face Recognition in the Wild
Abstract Slides Poster Similar
On Identification and Retrieval of Near-Duplicate Biological Images: A New Dataset and Protocol
Thomas E. Koker, Sai Spandana Chintapalli, San Wang, Blake A. Talbot, Daniel Wainstock, Marcelo Cicconet, Mary C. Walsh

Auto-TLDR; BINDER: Bio-Image Near-Duplicate Examples Repository for Image Identification and Retrieval
GuCNet: A Guided Clustering-Based Network for Improved Classification
Ushasi Chaudhuri, Syomantak Chaudhuri, Subhasis Chaudhuri

Auto-TLDR; Semantic Classification of Challenging Dataset Using Guide Datasets
Abstract Slides Poster Similar
Motion Segmentation with Pairwise Matches and Unknown Number of Motions
Federica Arrigoni, Tomas Pajdla, Luca Magri

Auto-TLDR; Motion Segmentation using Multi-Modelfitting andpermutation synchronization
Abstract Slides Poster Similar
Learning Embeddings for Image Clustering: An Empirical Study of Triplet Loss Approaches
Kalun Ho, Janis Keuper, Franz-Josef Pfreundt, Margret Keuper

Auto-TLDR; Clustering Objectives for K-means and Correlation Clustering Using Triplet Loss
Abstract Slides Poster Similar
Expectation-Maximization for Scheduling Problems in Satellite Communication
Werner Bailer, Martin Winter, Johannes Ebert, Joel Flavio, Karin Plimon

Auto-TLDR; Unsupervised Machine Learning for Satellite Communication Using Expectation-Maximization
Abstract Slides Poster Similar
Large-Scale Historical Watermark Recognition: Dataset and a New Consistency-Based Approach
Xi Shen, Ilaria Pastrolin, Oumayma Bounou, Spyros Gidaris, Marc Smith, Olivier Poncet, Mathieu Aubry

Auto-TLDR; Historical Watermark Recognition with Fine-Grained Cross-Domain One-Shot Instance Recognition
Abstract Slides Poster Similar
Transformer Reasoning Network for Image-Text Matching and Retrieval
Nicola Messina, Fabrizio Falchi, Andrea Esuli, Giuseppe Amato

Auto-TLDR; A Transformer Encoder Reasoning Network for Image-Text Matching in Large-Scale Information Retrieval
Abstract Slides Poster Similar
A Systematic Investigation on Deep Architectures for Automatic Skin Lesions Classification
Pierluigi Carcagni, Marco Leo, Andrea Cuna, Giuseppe Celeste, Cosimo Distante

Auto-TLDR; RegNet: Deep Investigation of Convolutional Neural Networks for Automatic Classification of Skin Lesions
Abstract Slides Poster Similar
MEG: Multi-Evidence GNN for Multimodal Semantic Forensics
Ekraam Sabir, Ayush Jaiswal, Wael Abdalmageed, Prem Natarajan

Auto-TLDR; Scalable Image Repurposing Detection with Graph Neural Network Based Model
Abstract Slides Poster Similar
Deep Composer: A Hash-Based Duplicative Neural Network for Generating Multi-Instrument Songs
Jacob Galajda, Brandon Royal, Kien Hua

Auto-TLDR; Deep Composer for Intelligence Duplication
Progressive Learning Algorithm for Efficient Person Re-Identification
Zhen Li, Hanyang Shao, Liang Niu, Nian Xue

Auto-TLDR; Progressive Learning Algorithm for Large-Scale Person Re-Identification
Abstract Slides Poster Similar
Siamese Graph Convolution Network for Face Sketch Recognition
Liang Fan, Xianfang Sun, Paul Rosin

Auto-TLDR; A novel Siamese graph convolution network for face sketch recognition
Abstract Slides Poster Similar
N2D: (Not Too) Deep Clustering Via Clustering the Local Manifold of an Autoencoded Embedding
Ryan Mcconville, Raul Santos-Rodriguez, Robert Piechocki, Ian Craddock

Auto-TLDR; Local Manifold Learning for Deep Clustering on Autoencoded Embeddings
DFH-GAN: A Deep Face Hashing with Generative Adversarial Network
Bo Xiao, Lanxiang Zhou, Yifei Wang, Qiangfang Xu

Auto-TLDR; Deep Face Hashing with GAN for Face Image Retrieval
Abstract Slides Poster Similar
Object Classification of Remote Sensing Images Based on Optimized Projection Supervised Discrete Hashing
Qianqian Zhang, Yazhou Liu, Quansen Sun

Auto-TLDR; Optimized Projection Supervised Discrete Hashing for Large-Scale Remote Sensing Image Object Classification
Abstract Slides Poster Similar