Picture-To-Amount (PITA): Predicting Relative Ingredient Amounts from Food Images
Jiatong Li,
Fangda Han,
Ricardo Guerrero,
Vladimir Pavlovic

Auto-TLDR; PITA: A Deep Learning Architecture for Predicting the Relative Amount of Ingredients from Food Images
Similar papers
Multi-Task Learning for Calorie Prediction on a Novel Large-Scale Recipe Dataset Enriched with Nutritional Information
Robin Ruede, Verena Heusser, Lukas Frank, Monica Haurilet, Alina Roitberg, Rainer Stiefelhagen

Auto-TLDR; Pic2kcal: Learning Food Recipes from Images for Calorie Estimation
Abstract Slides Poster Similar
RWMF: A Real-World Multimodal Foodlog Database
Pengfei Zhou, Cong Bai, Kaining Ying, Jie Xia, Lixin Huang
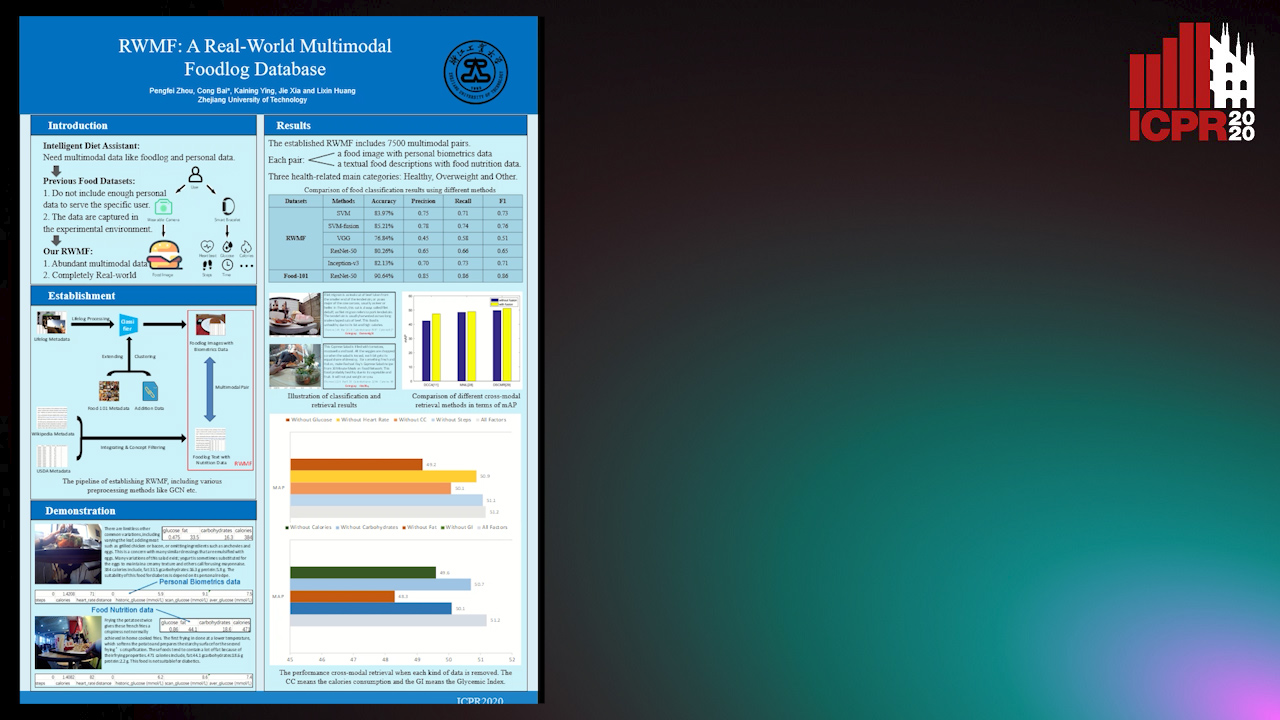
Auto-TLDR; Real-World Multimodal Foodlog: A Real-World Foodlog Database for Diet Assistant
Abstract Slides Poster Similar
Uncertainty-Aware Data Augmentation for Food Recognition
Eduardo Aguilar, Bhalaji Nagarajan, Rupali Khatun, Marc Bolaños, Petia Radeva

Auto-TLDR; Data Augmentation for Food Recognition Using Epistemic Uncertainty
Abstract Slides Poster Similar
A CNN-RNN Framework for Image Annotation from Visual Cues and Social Network Metadata
Tobia Tesan, Pasquale Coscia, Lamberto Ballan

Auto-TLDR; Context-Based Image Annotation with Multiple Semantic Embeddings and Recurrent Neural Networks
Abstract Slides Poster Similar
Partially Supervised Multi-Task Network for Single-View Dietary Assessment
Ya Lu, Thomai Stathopoulou, Stavroula Mougiakakou

Auto-TLDR; Food Volume Estimation from a Single Food Image via Geometric Understanding and Semantic Prediction
Abstract Slides Poster Similar
Price Suggestion for Online Second-Hand Items
Liang Han, Zhaozheng Yin, Zhurong Xia, Li Guo, Mingqian Tang, Rong Jin
Auto-TLDR; An Intelligent Price Suggestion System for Online Second-hand Items
Abstract Slides Poster Similar
Beyond the Deep Metric Learning: Enhance the Cross-Modal Matching with Adversarial Discriminative Domain Regularization
Li Ren, Kai Li, Liqiang Wang, Kien Hua

Auto-TLDR; Adversarial Discriminative Domain Regularization for Efficient Cross-Modal Matching
Abstract Slides Poster Similar
VSR++: Improving Visual Semantic Reasoning for Fine-Grained Image-Text Matching
Hui Yuan, Yan Huang, Dongbo Zhang, Zerui Chen, Wenlong Cheng, Liang Wang

Auto-TLDR; Improving Visual Semantic Reasoning for Fine-Grained Image-Text Matching
Abstract Slides Poster Similar
RGB-Infrared Person Re-Identification Via Image Modality Conversion
Huangpeng Dai, Qing Xie, Yanchun Ma, Yongjian Liu, Shengwu Xiong

Auto-TLDR; CE2L: A Novel Network for Cross-Modality Re-identification with Feature Alignment
Abstract Slides Poster Similar
A Novel Attention-Based Aggregation Function to Combine Vision and Language
Matteo Stefanini, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara

Auto-TLDR; Fully-Attentive Reduction for Vision and Language
Abstract Slides Poster Similar
Open-World Group Retrieval with Ambiguity Removal: A Benchmark
Ling Mei, Jian-Huang Lai, Zhanxiang Feng, Xiaohua Xie

Auto-TLDR; P2GSM-AR: Re-identifying changing groups of people under the open-world and group-ambiguity scenarios
Abstract Slides Poster Similar
Transformer Reasoning Network for Image-Text Matching and Retrieval
Nicola Messina, Fabrizio Falchi, Andrea Esuli, Giuseppe Amato

Auto-TLDR; A Transformer Encoder Reasoning Network for Image-Text Matching in Large-Scale Information Retrieval
Abstract Slides Poster Similar
Cross-Media Hash Retrieval Using Multi-head Attention Network
Zhixin Li, Feng Ling, Chuansheng Xu, Canlong Zhang, Huifang Ma

Auto-TLDR; Unsupervised Cross-Media Hash Retrieval Using Multi-Head Attention Network
Abstract Slides Poster Similar
Integrating Historical States and Co-Attention Mechanism for Visual Dialog
Tianling Jiang, Yi Ji, Chunping Liu

Auto-TLDR; Integrating Historical States and Co-attention for Visual Dialog
Abstract Slides Poster Similar
Attentive Part-Aware Networks for Partial Person Re-Identification
Lijuan Huo, Chunfeng Song, Zhengyi Liu, Zhaoxiang Zhang

Auto-TLDR; Part-Aware Learning for Partial Person Re-identification
Abstract Slides Poster Similar
Webly Supervised Image-Text Embedding with Noisy Tag Refinement
Niluthpol Mithun, Ravdeep Pasricha, Evangelos Papalexakis, Amit Roy-Chowdhury

Auto-TLDR; Robust Joint Embedding for Image-Text Retrieval Using Web Images
PrivAttNet: Predicting Privacy Risks in Images Using Visual Attention
Chen Zhang, Thivya Kandappu, Vigneshwaran Subbaraju

Auto-TLDR; PrivAttNet: A Visual Attention Based Approach for Privacy Sensitivity in Images
Abstract Slides Poster Similar
Using Scene Graphs for Detecting Visual Relationships
Anurag Tripathi, Siddharth Srivastava, Brejesh Lall, Santanu Chaudhury

Auto-TLDR; Relationship Detection using Context Aligned Scene Graph Embeddings
Abstract Slides Poster Similar
SL-DML: Signal Level Deep Metric Learning for Multimodal One-Shot Action Recognition
Raphael Memmesheimer, Nick Theisen, Dietrich Paulus

Auto-TLDR; One-Shot Action Recognition using Metric Learning
Multi-Label Contrastive Focal Loss for Pedestrian Attribute Recognition
Xiaoqiang Zheng, Zhenxia Yu, Lin Chen, Fan Zhu, Shilong Wang

Auto-TLDR; Multi-label Contrastive Focal Loss for Pedestrian Attribute Recognition
Abstract Slides Poster Similar
MEG: Multi-Evidence GNN for Multimodal Semantic Forensics
Ekraam Sabir, Ayush Jaiswal, Wael Abdalmageed, Prem Natarajan

Auto-TLDR; Scalable Image Repurposing Detection with Graph Neural Network Based Model
Abstract Slides Poster Similar
Progressive Learning Algorithm for Efficient Person Re-Identification
Zhen Li, Hanyang Shao, Liang Niu, Nian Xue

Auto-TLDR; Progressive Learning Algorithm for Large-Scale Person Re-Identification
Abstract Slides Poster Similar
VSB^2-Net: Visual-Semantic Bi-Branch Network for Zero-Shot Hashing
Xin Li, Xiangfeng Wang, Bo Jin, Wenjie Zhang, Jun Wang, Hongyuan Zha

Auto-TLDR; VSB^2-Net: inductive zero-shot hashing for image retrieval
Abstract Slides Poster Similar
Multi-Stage Attention Based Visual Question Answering
Aakansha Mishra, Ashish Anand, Prithwijit Guha

Auto-TLDR; Alternative Bi-directional Attention for Visual Question Answering
On Identification and Retrieval of Near-Duplicate Biological Images: A New Dataset and Protocol
Thomas E. Koker, Sai Spandana Chintapalli, San Wang, Blake A. Talbot, Daniel Wainstock, Marcelo Cicconet, Mary C. Walsh

Auto-TLDR; BINDER: Bio-Image Near-Duplicate Examples Repository for Image Identification and Retrieval
Deep Convolutional Embedding for Digitized Painting Clustering
Giovanna Castellano, Gennaro Vessio

Auto-TLDR; A Deep Convolutional Embedding Model for Clustering Artworks
Abstract Slides Poster Similar
Future Urban Scenes Generation through Vehicles Synthesis
Alessandro Simoni, Luca Bergamini, Andrea Palazzi, Simone Calderara, Rita Cucchiara

Auto-TLDR; Predicting the Future of an Urban Scene with a Novel View Synthesis Paradigm
Abstract Slides Poster Similar
Hierarchical Multimodal Attention for Deep Video Summarization
Melissa Sanabria, Frederic Precioso, Thomas Menguy

Auto-TLDR; Automatic Summarization of Professional Soccer Matches Using Event-Stream Data and Multi- Instance Learning
Abstract Slides Poster Similar
Multi-Modal Deep Clustering: Unsupervised Partitioning of Images

Auto-TLDR; Multi-Modal Deep Clustering for Unlabeled Images
Abstract Slides Poster Similar
Adaptive L2 Regularization in Person Re-Identification
Xingyang Ni, Liang Fang, Heikki Juhani Huttunen

Auto-TLDR; AdaptiveReID: Adaptive L2 Regularization for Person Re-identification
Abstract Slides Poster Similar
Dual Path Multi-Modal High-Order Features for Textual Content Based Visual Question Answering
Yanan Li, Yuetan Lin, Hongrui Zhao, Donghui Wang

Auto-TLDR; TextVQA: An End-to-End Visual Question Answering Model for Text-Based VQA
Visual Oriented Encoder: Integrating Multimodal and Multi-Scale Contexts for Video Captioning

Auto-TLDR; Visual Oriented Encoder for Video Captioning
Abstract Slides Poster Similar
MAGNet: Multi-Region Attention-Assisted Grounding of Natural Language Queries at Phrase Level
Amar Shrestha, Krittaphat Pugdeethosapol, Haowen Fang, Qinru Qiu

Auto-TLDR; MAGNet: A Multi-Region Attention-Aware Grounding Network for Free-form Textual Queries
Abstract Slides Poster Similar
Privacy Attributes-Aware Message Passing Neural Network for Visual Privacy Attributes Classification
Hanbin Hong, Wentao Bao, Yuan Hong, Yu Kong

Auto-TLDR; Privacy Attributes-Aware Message Passing Neural Network for Visual Privacy Attribute Classification
Abstract Slides Poster Similar
Smart Inference for Multidigit Convolutional Neural Network Based Barcode Decoding
Duy-Thao Do, Tolcha Yalew, Tae Joon Jun, Daeyoung Kim

Auto-TLDR; Smart Inference for Barcode Decoding using Deep Convolutional Neural Network
Abstract Slides Poster Similar
Road Network Metric Learning for Estimated Time of Arrival
Yiwen Sun, Kun Fu, Zheng Wang, Changshui Zhang, Jieping Ye

Auto-TLDR; Road Network Metric Learning for Estimated Time of Arrival (RNML-ETA)
Abstract Slides Poster Similar
A Prototype-Based Generalized Zero-Shot Learning Framework for Hand Gesture Recognition
Jinting Wu, Yujia Zhang, Xiao-Guang Zhao

Auto-TLDR; Generalized Zero-Shot Learning for Hand Gesture Recognition
Abstract Slides Poster Similar
Deep Composer: A Hash-Based Duplicative Neural Network for Generating Multi-Instrument Songs
Jacob Galajda, Brandon Royal, Kien Hua

Auto-TLDR; Deep Composer for Intelligence Duplication
Interpretable Structured Learning with Sparse Gated Sequence Encoder for Protein-Protein Interaction Prediction
Kishan K C, Feng Cui, Anne Haake, Rui Li

Auto-TLDR; Predicting Protein-Protein Interactions Using Sequence Representations
Abstract Slides Poster Similar
Supporting Skin Lesion Diagnosis with Content-Based Image Retrieval
Stefano Allegretti, Federico Bolelli, Federico Pollastri, Sabrina Longhitano, Giovanni Pellacani, Costantino Grana

Auto-TLDR; Skin Images Retrieval Using Convolutional Neural Networks for Skin Lesion Classification and Segmentation
Abstract Slides Poster Similar
Building Computationally Efficient and Well-Generalizing Person Re-Identification Models with Metric Learning
Vladislav Sovrasov, Dmitry Sidnev

Auto-TLDR; Cross-Domain Generalization in Person Re-identification using Omni-Scale Network
Developing Motion Code Embedding for Action Recognition in Videos
Maxat Alibayev, David Andrea Paulius, Yu Sun

Auto-TLDR; Motion Embedding via Motion Codes for Action Recognition
Abstract Slides Poster Similar
Attentive Visual Semantic Specialized Network for Video Captioning
Jesus Perez-Martin, Benjamin Bustos, Jorge Pérez

Auto-TLDR; Adaptive Visual Semantic Specialized Network for Video Captioning
Abstract Slides Poster Similar
Equation Attention Relationship Network (EARN) : A Geometric Deep Metric Framework for Learning Similar Math Expression Embedding
Saleem Ahmed, Kenny Davila, Srirangaraj Setlur, Venu Govindaraju

Auto-TLDR; Representational Learning for Similarity Based Retrieval of Mathematical Expressions
Abstract Slides Poster Similar
Region and Relations Based Multi Attention Network for Graph Classification
Manasvi Aggarwal, M. Narasimha Murty

Auto-TLDR; R2POOL: A Graph Pooling Layer for Non-euclidean Structures
Abstract Slides Poster Similar
Multi-Scale Cascading Network with Compact Feature Learning for RGB-Infrared Person Re-Identification
Can Zhang, Hong Liu, Wei Guo, Mang Ye

Auto-TLDR; Multi-Scale Part-Aware Cascading for RGB-Infrared Person Re-identification
Abstract Slides Poster Similar
One-Stage Multi-Task Detector for 3D Cardiac MR Imaging
Weizeng Lu, Xi Jia, Wei Chen, Nicolò Savioli, Antonio De Marvao, Linlin Shen, Declan O'Regan, Jinming Duan

Auto-TLDR; Multi-task Learning for Real-Time, simultaneous landmark location and bounding box detection in 3D space
Abstract Slides Poster Similar
Not 3D Re-ID: Simple Single Stream 2D Convolution for Robust Video Re-Identification

Auto-TLDR; ResNet50-IBN for Video-based Person Re-Identification using Single Stream 2D Convolution Network
Abstract Slides Poster Similar