Using Scene Graphs for Detecting Visual Relationships
Anurag Tripathi,
Siddharth Srivastava,
Brejesh Lall,
Santanu Chaudhury

Auto-TLDR; Relationship Detection using Context Aligned Scene Graph Embeddings
Similar papers
Adaptive Word Embedding Module for Semantic Reasoning in Large-Scale Detection
Yu Zhang, Xiaoyu Wu, Ruolin Zhu

Auto-TLDR; Adaptive Word Embedding Module for Object Detection
Abstract Slides Poster Similar
Context for Object Detection Via Lightweight Global and Mid-Level Representations
Mesut Erhan Unal, Adriana Kovashka

Auto-TLDR; Context-Based Object Detection with Semantic Similarity
Abstract Slides Poster Similar
Improving Visual Relation Detection Using Depth Maps
Sahand Sharifzadeh, Sina Moayed Baharlou, Max Berrendorf, Rajat Koner, Volker Tresp

Auto-TLDR; Exploiting Depth Maps for Visual Relation Detection
Abstract Slides Poster Similar
Human-Centric Parsing Network for Human-Object Interaction Detection
Guanyu Chen, Chong Chen, Zhicheng Zhao, Fei Su

Auto-TLDR; Human-Centric Parsing Network for Human-Object Interactions Detection
Abstract Slides Poster Similar
MAGNet: Multi-Region Attention-Assisted Grounding of Natural Language Queries at Phrase Level
Amar Shrestha, Krittaphat Pugdeethosapol, Haowen Fang, Qinru Qiu

Auto-TLDR; MAGNet: A Multi-Region Attention-Aware Grounding Network for Free-form Textual Queries
Abstract Slides Poster Similar
Exploring and Exploiting the Hierarchical Structure of a Scene for Scene Graph Generation
Ikuto Kurosawa, Tetsunori Kobayashi, Yoshihiko Hayashi

Auto-TLDR; A Hierarchical Model for Scene Graph Generation
Abstract Slides Poster Similar
Multi-Modal Contextual Graph Neural Network for Text Visual Question Answering
Yaoyuan Liang, Xin Wang, Xuguang Duan, Wenwu Zhu

Auto-TLDR; Multi-modal Contextual Graph Neural Network for Text Visual Question Answering
Abstract Slides Poster Similar
Semantics to Space(S2S): Embedding Semantics into Spatial Space for Zero-Shot Verb-Object Query Inferencing

Auto-TLDR; Semantics-to-Space: Deep Zero-Shot Learning for Verb-Object Interaction with Vectors
Abstract Slides Poster Similar
Object Detection Using Dual Graph Network
Shengjia Chen, Zhixin Li, Feicheng Huang, Canlong Zhang, Huifang Ma

Auto-TLDR; A Graph Convolutional Network for Object Detection with Key Relation Information
A CNN-RNN Framework for Image Annotation from Visual Cues and Social Network Metadata
Tobia Tesan, Pasquale Coscia, Lamberto Ballan

Auto-TLDR; Context-Based Image Annotation with Multiple Semantic Embeddings and Recurrent Neural Networks
Abstract Slides Poster Similar
Activity and Relationship Modeling Driven Weakly Supervised Object Detection
Yinlin Li, Yang Qian, Xu Yang, Yuren Zhang
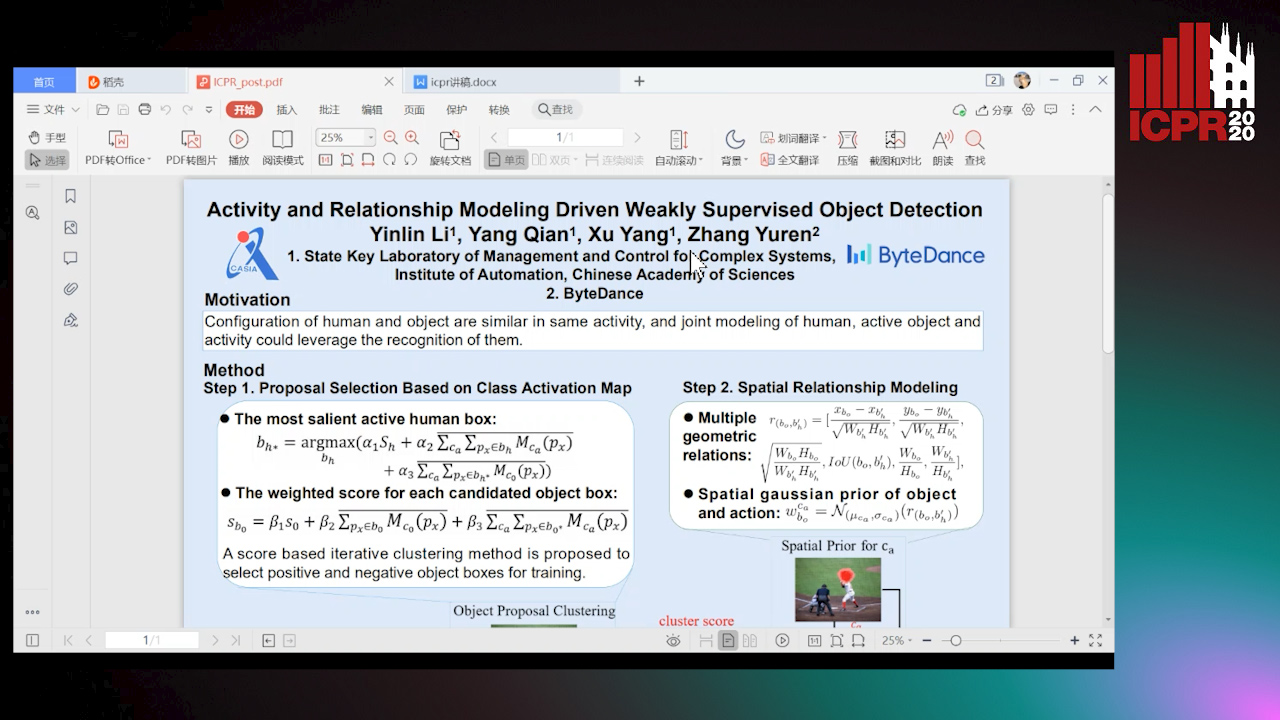
Auto-TLDR; Weakly Supervised Object Detection Using Activity Label and Relationship Modeling
Abstract Slides Poster Similar
Context Aware Group Activity Recognition
Avijit Dasgupta, C. V. Jawahar, Karteek Alahari

Auto-TLDR; A Two-Stream Architecture for Group Activity Recognition in Multi-Person Videos
Abstract Slides Poster Similar
Detecting Objects with High Object Region Percentage
Fen Fang, Qianli Xu, Liyuan Li, Ying Gu, Joo-Hwee Lim

Auto-TLDR; Faster R-CNN for High-ORP Object Detection
Abstract Slides Poster Similar
VSR++: Improving Visual Semantic Reasoning for Fine-Grained Image-Text Matching
Hui Yuan, Yan Huang, Dongbo Zhang, Zerui Chen, Wenlong Cheng, Liang Wang

Auto-TLDR; Improving Visual Semantic Reasoning for Fine-Grained Image-Text Matching
Abstract Slides Poster Similar
Cross-View Relation Networks for Mammogram Mass Detection
Ma Jiechao, Xiang Li, Hongwei Li, Ruixuan Wang, Bjoern Menze, Wei-Shi Zheng

Auto-TLDR; Multi-view Modeling for Mass Detection in Mammogram
Abstract Slides Poster Similar
Question-Agnostic Attention for Visual Question Answering
Moshiur R Farazi, Salman Hameed Khan, Nick Barnes

Auto-TLDR; Question-Agnostic Attention for Visual Question Answering
Abstract Slides Poster Similar
Zero-Shot Text Classification with Semantically Extended Graph Convolutional Network
Tengfei Liu, Yongli Hu, Junbin Gao, Yanfeng Sun, Baocai Yin

Auto-TLDR; Semantically Extended Graph Convolutional Network for Zero-shot Text Classification
Abstract Slides Poster Similar
More Correlations Better Performance: Fully Associative Networks for Multi-Label Image Classification

Auto-TLDR; Fully Associative Network for Fully Exploiting Correlation Information in Multi-Label Classification
Abstract Slides Poster Similar
Region and Relations Based Multi Attention Network for Graph Classification
Manasvi Aggarwal, M. Narasimha Murty

Auto-TLDR; R2POOL: A Graph Pooling Layer for Non-euclidean Structures
Abstract Slides Poster Similar
Multi-Stage Attention Based Visual Question Answering
Aakansha Mishra, Ashish Anand, Prithwijit Guha

Auto-TLDR; Alternative Bi-directional Attention for Visual Question Answering
Self-Selective Context for Interaction Recognition
Kilickaya Kilickaya, Noureldien Hussein, Efstratios Gavves, Arnold Smeulders

Auto-TLDR; Self-Selective Context for Human-Object Interaction Recognition
Abstract Slides Poster Similar
Equation Attention Relationship Network (EARN) : A Geometric Deep Metric Framework for Learning Similar Math Expression Embedding
Saleem Ahmed, Kenny Davila, Srirangaraj Setlur, Venu Govindaraju

Auto-TLDR; Representational Learning for Similarity Based Retrieval of Mathematical Expressions
Abstract Slides Poster Similar
FashionGraph: Understanding Fashion Data Using Scene Graph Generation
Shabnam Sadegharmaki, Marc A. Kastner, Shin'Ichi Satoh
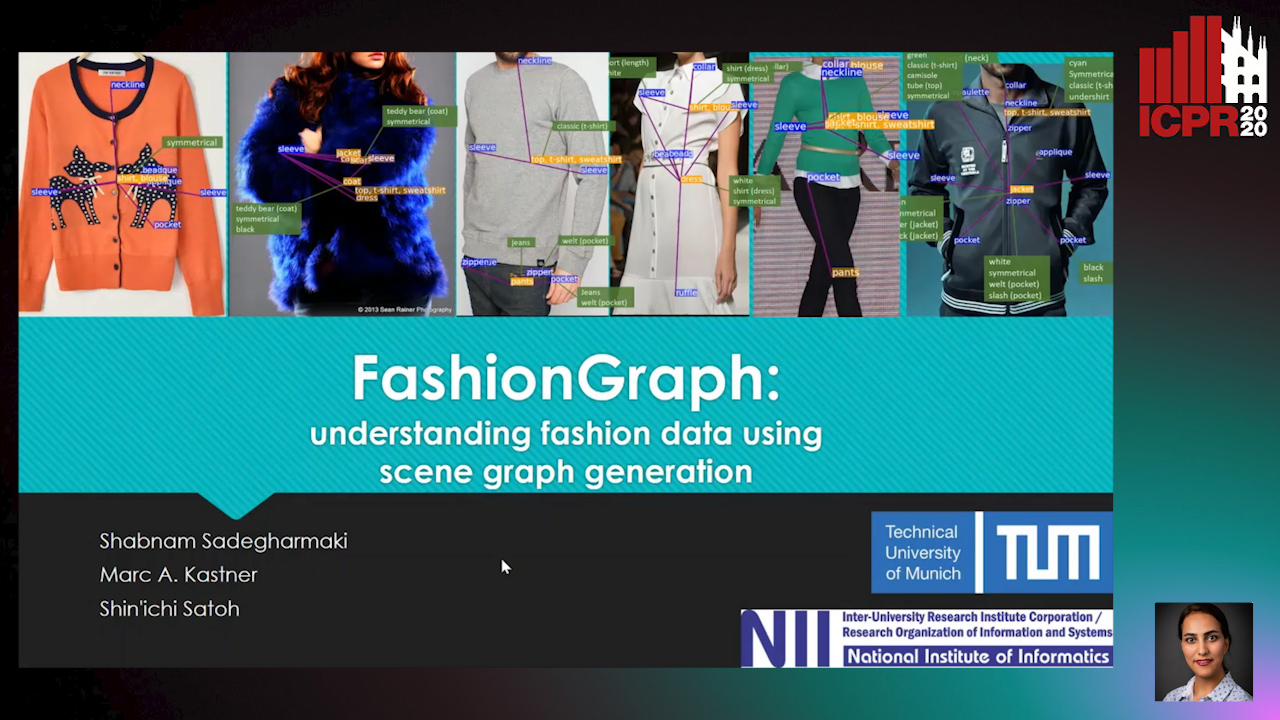
Auto-TLDR; Exploiting Scene Graph Knowledge for Fashion Applications
A Prototype-Based Generalized Zero-Shot Learning Framework for Hand Gesture Recognition
Jinting Wu, Yujia Zhang, Xiao-Guang Zhao

Auto-TLDR; Generalized Zero-Shot Learning for Hand Gesture Recognition
Abstract Slides Poster Similar
Dual Path Multi-Modal High-Order Features for Textual Content Based Visual Question Answering
Yanan Li, Yuetan Lin, Hongrui Zhao, Donghui Wang

Auto-TLDR; TextVQA: An End-to-End Visual Question Answering Model for Text-Based VQA
FeatureNMS: Non-Maximum Suppression by Learning Feature Embeddings

Auto-TLDR; FeatureNMS: Non-Maximum Suppression for Multiple Object Detection
Abstract Slides Poster Similar
Label Incorporated Graph Neural Networks for Text Classification
Yuan Xin, Linli Xu, Junliang Guo, Jiquan Li, Xin Sheng, Yuanyuan Zhou

Auto-TLDR; Graph Neural Networks for Semi-supervised Text Classification
Abstract Slides Poster Similar
Heterogeneous Graph-Based Knowledge Transfer for Generalized Zero-Shot Learning
Junjie Wang, Xiangfeng Wang, Bo Jin, Junchi Yan, Wenjie Zhang, Hongyuan Zha

Auto-TLDR; Heterogeneous Graph-based Knowledge Transfer for Generalized Zero-Shot Learning
Abstract Slides Poster Similar
Incrementally Zero-Shot Detection by an Extreme Value Analyzer
Sixiao Zheng, Yanwei Fu, Yanxi Hou

Auto-TLDR; IZSD-EVer: Incremental Zero-Shot Detection for Incremental Learning
Integrating Historical States and Co-Attention Mechanism for Visual Dialog
Tianling Jiang, Yi Ji, Chunping Liu

Auto-TLDR; Integrating Historical States and Co-attention for Visual Dialog
Abstract Slides Poster Similar
End-To-End Hierarchical Relation Extraction for Generic Form Understanding
Tuan Anh Nguyen Dang, Duc-Thanh Hoang, Quang Bach Tran, Chih-Wei Pan, Thanh-Dat Nguyen

Auto-TLDR; Joint Entity Labeling and Link Prediction for Form Understanding in Noisy Scanned Documents
Abstract Slides Poster Similar
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
Exploiting Knowledge Embedded Soft Labels for Image Recognition
Lixian Yuan, Riquan Chen, Hefeng Wu, Tianshui Chen, Wentao Wang, Pei Chen

Auto-TLDR; A Soft Label Vector for Image Recognition
Abstract Slides Poster Similar
Supervised Domain Adaptation Using Graph Embedding
Lukas Hedegaard, Omar Ali Sheikh-Omar, Alexandros Iosifidis

Auto-TLDR; Domain Adaptation from the Perspective of Multi-view Graph Embedding and Dimensionality Reduction
Abstract Slides Poster Similar
Recognizing Bengali Word Images - A Zero-Shot Learning Perspective
Sukalpa Chanda, Daniël Arjen Willem Haitink, Prashant Kumar Prasad, Jochem Baas, Umapada Pal, Lambert Schomaker

Auto-TLDR; Zero-Shot Learning for Word Recognition in Bengali Script
Abstract Slides Poster Similar
A Novel Region of Interest Extraction Layer for Instance Segmentation
Leonardo Rossi, Akbar Karimi, Andrea Prati

Auto-TLDR; Generic RoI Extractor for Two-Stage Neural Network for Instance Segmentation
Abstract Slides Poster Similar
Multi-Scale 2D Representation Learning for Weakly-Supervised Moment Retrieval
Ding Li, Rui Wu, Zhizhong Zhang, Yongqiang Tang, Wensheng Zhang

Auto-TLDR; Multi-scale 2D Representation Learning for Weakly Supervised Video Moment Retrieval
Abstract Slides Poster Similar
A Novel Attention-Based Aggregation Function to Combine Vision and Language
Matteo Stefanini, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara

Auto-TLDR; Fully-Attentive Reduction for Vision and Language
Abstract Slides Poster Similar
Privacy Attributes-Aware Message Passing Neural Network for Visual Privacy Attributes Classification
Hanbin Hong, Wentao Bao, Yuan Hong, Yu Kong

Auto-TLDR; Privacy Attributes-Aware Message Passing Neural Network for Visual Privacy Attribute Classification
Abstract Slides Poster Similar
Force Banner for the Recognition of Spatial Relations
Robin Deléarde, Camille Kurtz, Laurent Wendling, Philippe Dejean

Auto-TLDR; Spatial Relation Recognition using Force Banners
Boundary-Aware Graph Convolution for Semantic Segmentation
Hanzhe Hu, Jinshi Cui, Jinshi Hongbin Zha

Auto-TLDR; Boundary-Aware Graph Convolution for Semantic Segmentation
Abstract Slides Poster Similar
VSB^2-Net: Visual-Semantic Bi-Branch Network for Zero-Shot Hashing
Xin Li, Xiangfeng Wang, Bo Jin, Wenjie Zhang, Jun Wang, Hongyuan Zha

Auto-TLDR; VSB^2-Net: inductive zero-shot hashing for image retrieval
Abstract Slides Poster Similar
Multi-Scale Relational Reasoning with Regional Attention for Visual Question Answering

Auto-TLDR; Question-Guided Relational Reasoning for Visual Question Answering
Abstract Slides Poster Similar
Learning Group Activities from Skeletons without Individual Action Labels
Fabio Zappardino, Tiberio Uricchio, Lorenzo Seidenari, Alberto Del Bimbo

Auto-TLDR; Lean Pose Only for Group Activity Recognition
SyNet: An Ensemble Network for Object Detection in UAV Images

Auto-TLDR; SyNet: Combining Multi-Stage and Single-Stage Object Detection for Aerial Images
Attentive Visual Semantic Specialized Network for Video Captioning
Jesus Perez-Martin, Benjamin Bustos, Jorge Pérez

Auto-TLDR; Adaptive Visual Semantic Specialized Network for Video Captioning
Abstract Slides Poster Similar
Video Semantic Segmentation Using Deep Multi-View Representation Learning
Akrem Sellami, Salvatore Tabbone

Auto-TLDR; Deep Multi-view Representation Learning for Video Object Segmentation
Abstract Slides Poster Similar
Foreground-Focused Domain Adaption for Object Detection

Auto-TLDR; Unsupervised Domain Adaptation for Unsupervised Object Detection