FashionGraph: Understanding Fashion Data Using Scene Graph Generation
Shabnam Sadegharmaki,
Marc A. Kastner,
Shin'Ichi Satoh
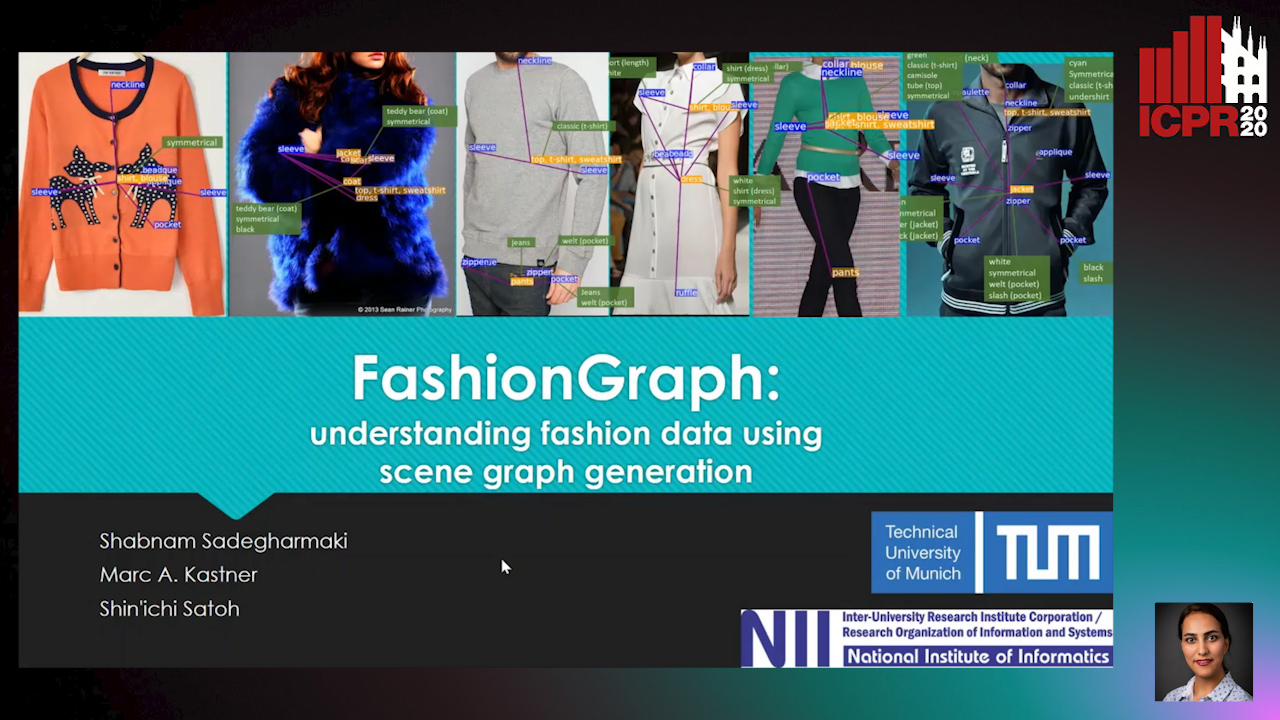
Auto-TLDR; Exploiting Scene Graph Knowledge for Fashion Applications
Similar papers
Improving Visual Relation Detection Using Depth Maps
Sahand Sharifzadeh, Sina Moayed Baharlou, Max Berrendorf, Rajat Koner, Volker Tresp

Auto-TLDR; Exploiting Depth Maps for Visual Relation Detection
Abstract Slides Poster Similar
Using Scene Graphs for Detecting Visual Relationships
Anurag Tripathi, Siddharth Srivastava, Brejesh Lall, Santanu Chaudhury

Auto-TLDR; Relationship Detection using Context Aligned Scene Graph Embeddings
Abstract Slides Poster Similar
Exploring and Exploiting the Hierarchical Structure of a Scene for Scene Graph Generation
Ikuto Kurosawa, Tetsunori Kobayashi, Yoshihiko Hayashi

Auto-TLDR; A Hierarchical Model for Scene Graph Generation
Abstract Slides Poster Similar
Efficient Grouping for Keypoint Detection
Alexey Sidnev, Ekaterina Krasikova, Maxim Kazakov
Auto-TLDR; Automatic Keypoint Grouping for DeepFashion2 Dataset
Abstract Slides Poster Similar
Aggregating Object Features Based on Attention Weights for Fine-Grained Image Retrieval
Hongli Lin, Yongqi Song, Zixuan Zeng, Weisheng Wang

Auto-TLDR; DSAW: Unsupervised Dual-selection for Fine-Grained Image Retrieval
Transformer Reasoning Network for Image-Text Matching and Retrieval
Nicola Messina, Fabrizio Falchi, Andrea Esuli, Giuseppe Amato

Auto-TLDR; A Transformer Encoder Reasoning Network for Image-Text Matching in Large-Scale Information Retrieval
Abstract Slides Poster Similar
Context for Object Detection Via Lightweight Global and Mid-Level Representations
Mesut Erhan Unal, Adriana Kovashka

Auto-TLDR; Context-Based Object Detection with Semantic Similarity
Abstract Slides Poster Similar
Exploiting Knowledge Embedded Soft Labels for Image Recognition
Lixian Yuan, Riquan Chen, Hefeng Wu, Tianshui Chen, Wentao Wang, Pei Chen

Auto-TLDR; A Soft Label Vector for Image Recognition
Abstract Slides Poster Similar
UCCTGAN: Unsupervised Clothing Color Transformation Generative Adversarial Network
Shuming Sun, Xiaoqiang Li, Jide Li

Auto-TLDR; An Unsupervised Clothing Color Transformation Generative Adversarial Network
Abstract Slides Poster Similar
Making Every Label Count: Handling Semantic Imprecision by Integrating Domain Knowledge
Clemens-Alexander Brust, Björn Barz, Joachim Denzler

Auto-TLDR; Class Hierarchies for Imprecise Label Learning and Annotation eXtrapolation
Abstract Slides Poster Similar
The DeepScoresV2 Dataset and Benchmark for Music Object Detection
Lukas Tuggener, Yvan Putra Satyawan, Alexander Pacha, Jürgen Schmidhuber, Thilo Stadelmann

Auto-TLDR; DeepScoresV2: an extended version of the DeepScores dataset for optical music recognition
Abstract Slides Poster Similar
Relatable Clothing: Detecting Visual Relationships between People and Clothing
Thomas Truong, Svetlana Yanushkevich

Auto-TLDR; Relatable Clothing Dataset for ``worn'' and ``unworn'' Classification
Abstract Slides Poster Similar
MEG: Multi-Evidence GNN for Multimodal Semantic Forensics
Ekraam Sabir, Ayush Jaiswal, Wael Abdalmageed, Prem Natarajan

Auto-TLDR; Scalable Image Repurposing Detection with Graph Neural Network Based Model
Abstract Slides Poster Similar
Hierarchical Head Design for Object Detectors
Shivang Agarwal, Frederic Jurie

Auto-TLDR; Hierarchical Anchor for SSD Detector
Abstract Slides Poster Similar
Equation Attention Relationship Network (EARN) : A Geometric Deep Metric Framework for Learning Similar Math Expression Embedding
Saleem Ahmed, Kenny Davila, Srirangaraj Setlur, Venu Govindaraju

Auto-TLDR; Representational Learning for Similarity Based Retrieval of Mathematical Expressions
Abstract Slides Poster Similar
Mutually Guided Dual-Task Network for Scene Text Detection
Mengbiao Zhao, Wei Feng, Fei Yin, Xu-Yao Zhang, Cheng-Lin Liu

Auto-TLDR; A dual-task network for word-level and line-level text detection
Automatically Gather Address Specific Dwelling Images Using Google Street View

Auto-TLDR; Automatic Address Specific Dwelling Image Collection Using Google Street View Data
Abstract Slides Poster Similar
Deep Gait Relative Attribute Using a Signed Quadratic Contrastive Loss
Yuta Hayashi, Shehata Allam, Yasushi Makihara, Daigo Muramatsu, Yasushi Yagi

Auto-TLDR; Signal-Contrastive Loss for Gait Attributes Estimation
Multi-View Object Detection Using Epipolar Constraints within Cluttered X-Ray Security Imagery
Brian Kostadinov Shalon Isaac-Medina, Chris G. Willcocks, Toby Breckon

Auto-TLDR; Exploiting Epipolar Constraints for Multi-View Object Detection in X-ray Security Images
Abstract Slides Poster Similar
VSR++: Improving Visual Semantic Reasoning for Fine-Grained Image-Text Matching
Hui Yuan, Yan Huang, Dongbo Zhang, Zerui Chen, Wenlong Cheng, Liang Wang

Auto-TLDR; Improving Visual Semantic Reasoning for Fine-Grained Image-Text Matching
Abstract Slides Poster Similar
Multiscale Attention-Based Prototypical Network for Few-Shot Semantic Segmentation
Yifei Zhang, Desire Sidibe, Olivier Morel, Fabrice Meriaudeau

Auto-TLDR; Few-shot Semantic Segmentation with Multiscale Feature Attention
RLST: A Reinforcement Learning Approach to Scene Text Detection Refinement
Xuan Peng, Zheng Huang, Kai Chen, Jie Guo, Weidong Qiu

Auto-TLDR; Saccadic Eye Movements and Peripheral Vision for Scene Text Detection using Reinforcement Learning
Abstract Slides Poster Similar
Adaptive Word Embedding Module for Semantic Reasoning in Large-Scale Detection
Yu Zhang, Xiaoyu Wu, Ruolin Zhu

Auto-TLDR; Adaptive Word Embedding Module for Object Detection
Abstract Slides Poster Similar
Developing Motion Code Embedding for Action Recognition in Videos
Maxat Alibayev, David Andrea Paulius, Yu Sun

Auto-TLDR; Motion Embedding via Motion Codes for Action Recognition
Abstract Slides Poster Similar
Detecting Objects with High Object Region Percentage
Fen Fang, Qianli Xu, Liyuan Li, Ying Gu, Joo-Hwee Lim

Auto-TLDR; Faster R-CNN for High-ORP Object Detection
Abstract Slides Poster Similar
EAGLE: Large-Scale Vehicle Detection Dataset in Real-World Scenarios Using Aerial Imagery
Seyed Majid Azimi, Reza Bahmanyar, Corentin Henry, Kurz Franz

Auto-TLDR; EAGLE: A Large-Scale Dataset for Multi-class Vehicle Detection with Object Orientation Information in Airborne Imagery
SECI-GAN: Semantic and Edge Completion for Dynamic Objects Removal
Francesco Pinto, Andrea Romanoni, Matteo Matteucci, Phil Torr

Auto-TLDR; SECI-GAN: Semantic and Edge Conditioned Inpainting Generative Adversarial Network
Abstract Slides Poster Similar
GarmentGAN: Photo-Realistic Adversarial Fashion Transfer
Amir Hossein Raffiee, Michael Sollami

Auto-TLDR; GarmentGAN: A Generative Adversarial Network for Image-Based Garment Transfer
Abstract Slides Poster Similar
A Novel Region of Interest Extraction Layer for Instance Segmentation
Leonardo Rossi, Akbar Karimi, Andrea Prati

Auto-TLDR; Generic RoI Extractor for Two-Stage Neural Network for Instance Segmentation
Abstract Slides Poster Similar
Self-Supervised Joint Encoding of Motion and Appearance for First Person Action Recognition
Mirco Planamente, Andrea Bottino, Barbara Caputo

Auto-TLDR; A Single Stream Architecture for Egocentric Action Recognition from the First-Person Point of View
Abstract Slides Poster Similar
Human-Centric Parsing Network for Human-Object Interaction Detection
Guanyu Chen, Chong Chen, Zhicheng Zhao, Fei Su

Auto-TLDR; Human-Centric Parsing Network for Human-Object Interactions Detection
Abstract Slides Poster Similar
Weakly Supervised Body Part Segmentation with Pose Based Part Priors
Zhengyuan Yang, Yuncheng Li, Linjie Yang, Ning Zhang, Jiebo Luo

Auto-TLDR; Weakly Supervised Body Part Segmentation Using Weak Labels
A CNN-RNN Framework for Image Annotation from Visual Cues and Social Network Metadata
Tobia Tesan, Pasquale Coscia, Lamberto Ballan

Auto-TLDR; Context-Based Image Annotation with Multiple Semantic Embeddings and Recurrent Neural Networks
Abstract Slides Poster Similar
An Unsupervised Approach towards Varying Human Skin Tone Using Generative Adversarial Networks
Debapriya Roy, Diganta Mukherjee, Bhabatosh Chanda

Auto-TLDR; Unsupervised Skin Tone Change Using Augmented Reality Based Models
Abstract Slides Poster Similar
Iterative Bounding Box Annotation for Object Detection
Bishwo Adhikari, Heikki Juhani Huttunen

Auto-TLDR; Semi-Automatic Bounding Box Annotation for Object Detection in Digital Images
Abstract Slides Poster Similar
MAGNet: Multi-Region Attention-Assisted Grounding of Natural Language Queries at Phrase Level
Amar Shrestha, Krittaphat Pugdeethosapol, Haowen Fang, Qinru Qiu

Auto-TLDR; MAGNet: A Multi-Region Attention-Aware Grounding Network for Free-form Textual Queries
Abstract Slides Poster Similar
Hierarchical Deep Hashing for Fast Large Scale Image Retrieval
Yongfei Zhang, Cheng Peng, Zhang Jingtao, Xianglong Liu, Shiliang Pu, Changhuai Chen

Auto-TLDR; Hierarchical indexed deep hashing for fast large scale image retrieval
Abstract Slides Poster Similar
Semantic Segmentation Refinement Using Entropy and Boundary-guided Monte Carlo Sampling and Directed Regional Search
Zitang Sun, Sei-Ichiro Kamata, Ruojing Wang, Weili Chen

Auto-TLDR; Directed Region Search and Refinement for Semantic Segmentation
Abstract Slides Poster Similar
Semantics to Space(S2S): Embedding Semantics into Spatial Space for Zero-Shot Verb-Object Query Inferencing

Auto-TLDR; Semantics-to-Space: Deep Zero-Shot Learning for Verb-Object Interaction with Vectors
Abstract Slides Poster Similar
Explorable Tone Mapping Operators
Su Chien-Chuan, Yu-Lun Liu, Hung Jin Lin, Ren Wang, Chia-Ping Chen, Yu-Lin Chang, Soo-Chang Pei

Auto-TLDR; Learning-based multimodal tone-mapping from HDR images
Abstract Slides Poster Similar
EdgeNet: Semantic Scene Completion from a Single RGB-D Image
Aloisio Dourado, Teofilo De Campos, Adrian Hilton, Hansung Kim

Auto-TLDR; Semantic Scene Completion using 3D Depth and RGB Information
Abstract Slides Poster Similar
Automated Whiteboard Lecture Video Summarization by Content Region Detection and Representation
Bhargava Urala Kota, Alexander Stone, Kenny Davila, Srirangaraj Setlur, Venu Govindaraju

Auto-TLDR; A Framework for Summarizing Whiteboard Lecture Videos Using Feature Representations of Handwritten Content Regions
VITON-GT: An Image-Based Virtual Try-On Model with Geometric Transformations
Matteo Fincato, Federico Landi, Marcella Cornia, Fabio Cesari, Rita Cucchiara

Auto-TLDR; VITON-GT: An Image-based Virtual Try-on Architecture for Fashion Catalogs
Abstract Slides Poster Similar
Privacy Attributes-Aware Message Passing Neural Network for Visual Privacy Attributes Classification
Hanbin Hong, Wentao Bao, Yuan Hong, Yu Kong

Auto-TLDR; Privacy Attributes-Aware Message Passing Neural Network for Visual Privacy Attribute Classification
Abstract Slides Poster Similar
PrivAttNet: Predicting Privacy Risks in Images Using Visual Attention
Chen Zhang, Thivya Kandappu, Vigneshwaran Subbaraju

Auto-TLDR; PrivAttNet: A Visual Attention Based Approach for Privacy Sensitivity in Images
Abstract Slides Poster Similar
Self-Supervised Learning with Graph Neural Networks for Region of Interest Retrieval in Histopathology
Yigit Ozen, Selim Aksoy, Kemal Kosemehmetoglu, Sevgen Onder, Aysegul Uner

Auto-TLDR; Self-supervised Contrastive Learning for Deep Representation Learning of Histopathology Images
Abstract Slides Poster Similar
Tiny Object Detection in Aerial Images
Jinwang Wang, Wen Yang, Haowen Guo, Ruixiang Zhang, Gui-Song Xia

Auto-TLDR; Tiny Object Detection in Aerial Images Using Multiple Center Points Based Learning Network
RescueNet: Joint Building Segmentation and Damage Assessment from Satellite Imagery

Auto-TLDR; RescueNet: End-to-End Building Segmentation and Damage Classification for Humanitarian Aid and Disaster Response
Abstract Slides Poster Similar