Relatable Clothing: Detecting Visual Relationships between People and Clothing
Thomas Truong,
Svetlana Yanushkevich

Auto-TLDR; Relatable Clothing Dataset for ``worn'' and ``unworn'' Classification
Similar papers
Hierarchical Head Design for Object Detectors
Shivang Agarwal, Frederic Jurie

Auto-TLDR; Hierarchical Anchor for SSD Detector
Abstract Slides Poster Similar
StrongPose: Bottom-up and Strong Keypoint Heat Map Based Pose Estimation

Auto-TLDR; StrongPose: A bottom-up box-free approach for human pose estimation and action recognition
Abstract Slides Poster Similar
Efficient Grouping for Keypoint Detection
Alexey Sidnev, Ekaterina Krasikova, Maxim Kazakov
Auto-TLDR; Automatic Keypoint Grouping for DeepFashion2 Dataset
Abstract Slides Poster Similar
A Novel Region of Interest Extraction Layer for Instance Segmentation
Leonardo Rossi, Akbar Karimi, Andrea Prati

Auto-TLDR; Generic RoI Extractor for Two-Stage Neural Network for Instance Segmentation
Abstract Slides Poster Similar
PrivAttNet: Predicting Privacy Risks in Images Using Visual Attention
Chen Zhang, Thivya Kandappu, Vigneshwaran Subbaraju

Auto-TLDR; PrivAttNet: A Visual Attention Based Approach for Privacy Sensitivity in Images
Abstract Slides Poster Similar
Triplet-Path Dilated Network for Detection and Segmentation of General Pathological Images
Jiaqi Luo, Zhicheng Zhao, Fei Su, Limei Guo

Auto-TLDR; Triplet-path Network for One-Stage Object Detection and Segmentation in Pathological Images
End-To-End Deep Learning Methods for Automated Damage Detection in Extreme Events at Various Scales
Yongsheng Bai, Alper Yilmaz, Halil Sezen

Auto-TLDR; Robust Mask R-CNN for Crack Detection in Extreme Events
Abstract Slides Poster Similar
Construction Worker Hardhat-Wearing Detection Based on an Improved BiFPN
Chenyang Zhang, Zhiqiang Tian, Jingyi Song, Yaoyue Zheng, Bo Xu

Auto-TLDR; A One-Stage Object Detection Method for Hardhat-Wearing in Construction Site
Abstract Slides Poster Similar
FashionGraph: Understanding Fashion Data Using Scene Graph Generation
Shabnam Sadegharmaki, Marc A. Kastner, Shin'Ichi Satoh
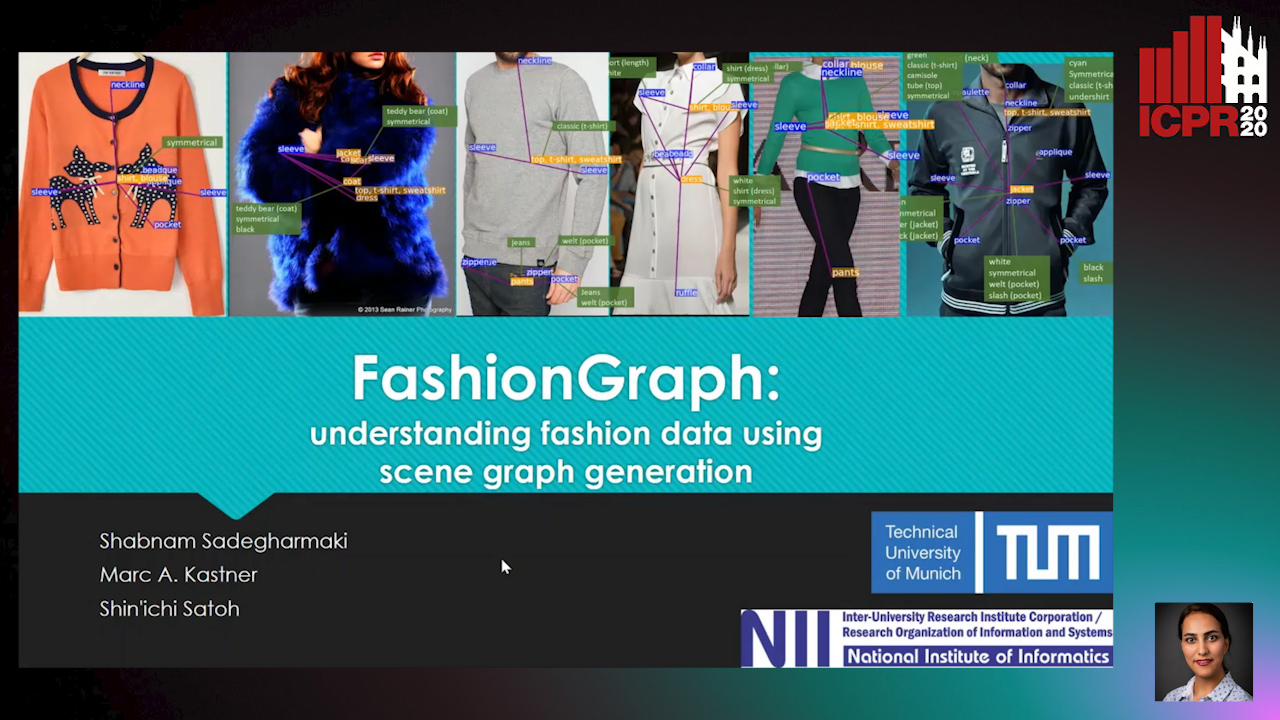
Auto-TLDR; Exploiting Scene Graph Knowledge for Fashion Applications
The DeepScoresV2 Dataset and Benchmark for Music Object Detection
Lukas Tuggener, Yvan Putra Satyawan, Alexander Pacha, Jürgen Schmidhuber, Thilo Stadelmann

Auto-TLDR; DeepScoresV2: an extended version of the DeepScores dataset for optical music recognition
Abstract Slides Poster Similar
SyNet: An Ensemble Network for Object Detection in UAV Images

Auto-TLDR; SyNet: Combining Multi-Stage and Single-Stage Object Detection for Aerial Images
Relevance Detection in Cataract Surgery Videos by Spatio-Temporal Action Localization
Negin Ghamsarian, Mario Taschwer, Doris Putzgruber, Stephanie. Sarny, Klaus Schoeffmann

Auto-TLDR; relevance-based retrieval in cataract surgery videos
Detecting Objects with High Object Region Percentage
Fen Fang, Qianli Xu, Liyuan Li, Ying Gu, Joo-Hwee Lim

Auto-TLDR; Faster R-CNN for High-ORP Object Detection
Abstract Slides Poster Similar
Image-Based Table Cell Detection: A New Dataset and an Improved Detection Method
Dafeng Wei, Hongtao Lu, Yi Zhou, Kai Chen

Auto-TLDR; TableCell: A Semi-supervised Dataset for Table-wise Detection and Recognition
Abstract Slides Poster Similar
EAGLE: Large-Scale Vehicle Detection Dataset in Real-World Scenarios Using Aerial Imagery
Seyed Majid Azimi, Reza Bahmanyar, Corentin Henry, Kurz Franz

Auto-TLDR; EAGLE: A Large-Scale Dataset for Multi-class Vehicle Detection with Object Orientation Information in Airborne Imagery
Mutually Guided Dual-Task Network for Scene Text Detection
Mengbiao Zhao, Wei Feng, Fei Yin, Xu-Yao Zhang, Cheng-Lin Liu

Auto-TLDR; A dual-task network for word-level and line-level text detection
Efficient-Receptive Field Block with Group Spatial Attention Mechanism for Object Detection
Jiacheng Zhang, Zhicheng Zhao, Fei Su

Auto-TLDR; E-RFB: Efficient-Receptive Field Block for Deep Neural Network for Object Detection
Abstract Slides Poster Similar
Classify Breast Histopathology Images with Ductal Instance-Oriented Pipeline
Beibin Li, Ezgi Mercan, Sachin Mehta, Stevan Knezevich, Corey Arnold, Donald Weaver, Joann Elmore, Linda Shapiro

Auto-TLDR; DIOP: Ductal Instance-Oriented Pipeline for Diagnostic Classification
Abstract Slides Poster Similar
Siamese Dynamic Mask Estimation Network for Fast Video Object Segmentation
Dexiang Hong, Guorong Li, Kai Xu, Li Su, Qingming Huang

Auto-TLDR; Siamese Dynamic Mask Estimation for Video Object Segmentation
Abstract Slides Poster Similar
Question-Agnostic Attention for Visual Question Answering
Moshiur R Farazi, Salman Hameed Khan, Nick Barnes

Auto-TLDR; Question-Agnostic Attention for Visual Question Answering
Abstract Slides Poster Similar
Iterative Bounding Box Annotation for Object Detection
Bishwo Adhikari, Heikki Juhani Huttunen

Auto-TLDR; Semi-Automatic Bounding Box Annotation for Object Detection in Digital Images
Abstract Slides Poster Similar
IPT: A Dataset for Identity Preserved Tracking in Closed Domains
Thomas Heitzinger, Martin Kampel

Auto-TLDR; Identity Preserved Tracking Using Depth Data for Privacy and Privacy
Abstract Slides Poster Similar
RescueNet: Joint Building Segmentation and Damage Assessment from Satellite Imagery

Auto-TLDR; RescueNet: End-to-End Building Segmentation and Damage Classification for Humanitarian Aid and Disaster Response
Abstract Slides Poster Similar
Small Object Detection by Generative and Discriminative Learning
Yi Gu, Jie Li, Chentao Wu, Weijia Jia, Jianping Chen

Auto-TLDR; Generative and Discriminative Learning for Small Object Detection
Abstract Slides Poster Similar
Using Scene Graphs for Detecting Visual Relationships
Anurag Tripathi, Siddharth Srivastava, Brejesh Lall, Santanu Chaudhury

Auto-TLDR; Relationship Detection using Context Aligned Scene Graph Embeddings
Abstract Slides Poster Similar
MEG: Multi-Evidence GNN for Multimodal Semantic Forensics
Ekraam Sabir, Ayush Jaiswal, Wael Abdalmageed, Prem Natarajan

Auto-TLDR; Scalable Image Repurposing Detection with Graph Neural Network Based Model
Abstract Slides Poster Similar
RLST: A Reinforcement Learning Approach to Scene Text Detection Refinement
Xuan Peng, Zheng Huang, Kai Chen, Jie Guo, Weidong Qiu

Auto-TLDR; Saccadic Eye Movements and Peripheral Vision for Scene Text Detection using Reinforcement Learning
Abstract Slides Poster Similar
MFPP: Morphological Fragmental Perturbation Pyramid for Black-Box Model Explanations
Qing Yang, Xia Zhu, Jong-Kae Fwu, Yun Ye, Ganmei You, Yuan Zhu

Auto-TLDR; Morphological Fragmental Perturbation Pyramid for Explainable Deep Neural Network
Abstract Slides Poster Similar
CDeC-Net: Composite Deformable Cascade Network for Table Detection in Document Images
Madhav Agarwal, Ajoy Mondal, C. V. Jawahar

Auto-TLDR; CDeC-Net: An End-to-End Trainable Deep Network for Detecting Tables in Document Images
Real Time Fencing Move Classification and Detection at Touch Time During a Fencing Match
Cem Ekin Sunal, Chris G. Willcocks, Boguslaw Obara

Auto-TLDR; Fencing Body Move Classification and Detection Using Deep Learning
Simple Multi-Resolution Representation Learning for Human Pose Estimation
Trung Tran Quang, Van Giang Nguyen, Daeyoung Kim

Auto-TLDR; Multi-resolution Heatmap Learning for Human Pose Estimation
Abstract Slides Poster Similar
Semantics to Space(S2S): Embedding Semantics into Spatial Space for Zero-Shot Verb-Object Query Inferencing

Auto-TLDR; Semantics-to-Space: Deep Zero-Shot Learning for Verb-Object Interaction with Vectors
Abstract Slides Poster Similar
Superpixel-Based Refinement for Object Proposal Generation
Christian Wilms, Simone Frintrop

Auto-TLDR; Superpixel-based Refinement of AttentionMask for Object Segmentation
Abstract Slides Poster Similar
Detective: An Attentive Recurrent Model for Sparse Object Detection
Amine Kechaou, Manuel Martinez, Monica Haurilet, Rainer Stiefelhagen

Auto-TLDR; Detective: An attentive object detector that identifies objects in images in a sequential manner
Abstract Slides Poster Similar
Automatically Gather Address Specific Dwelling Images Using Google Street View

Auto-TLDR; Automatic Address Specific Dwelling Image Collection Using Google Street View Data
Abstract Slides Poster Similar
Vision-Based Layout Detection from Scientific Literature Using Recurrent Convolutional Neural Networks

Auto-TLDR; Transfer Learning for Scientific Literature Layout Detection Using Convolutional Neural Networks
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
Enhancing Semantic Segmentation of Aerial Images with Inhibitory Neurons
Ihsan Ullah, Sean Reilly, Michael Madden

Auto-TLDR; Lateral Inhibition in Deep Neural Networks for Object Recognition and Semantic Segmentation
Abstract Slides Poster Similar
Object Detection Model Based on Scene-Level Region Proposal Self-Attention
Yu Quan, Zhixin Li, Canlong Zhang, Huifang Ma

Auto-TLDR; Exploiting Semantic Informations for Object Detection
Abstract Slides Poster Similar
Improving Robotic Grasping on Monocular Images Via Multi-Task Learning and Positional Loss
William Prew, Toby Breckon, Magnus Bordewich, Ulrik Beierholm

Auto-TLDR; Improving grasping performance from monocularcolour images in an end-to-end CNN architecture with multi-task learning
Abstract Slides Poster Similar
P2 Net: Augmented Parallel-Pyramid Net for Attention Guided Pose Estimation
Luanxuan Hou, Jie Cao, Yuan Zhao, Haifeng Shen, Jian Tang, Ran He

Auto-TLDR; Parallel-Pyramid Net with Partial Attention for Human Pose Estimation
Abstract Slides Poster Similar
Neural Compression and Filtering for Edge-assisted Real-time Object Detection in Challenged Networks
Yoshitomo Matsubara, Marco Levorato

Auto-TLDR; Deep Neural Networks for Remote Object Detection Using Edge Computing
Abstract Slides Poster Similar
FeatureNMS: Non-Maximum Suppression by Learning Feature Embeddings

Auto-TLDR; FeatureNMS: Non-Maximum Suppression for Multiple Object Detection
Abstract Slides Poster Similar
Multi-View Object Detection Using Epipolar Constraints within Cluttered X-Ray Security Imagery
Brian Kostadinov Shalon Isaac-Medina, Chris G. Willcocks, Toby Breckon

Auto-TLDR; Exploiting Epipolar Constraints for Multi-View Object Detection in X-ray Security Images
Abstract Slides Poster Similar
A Systematic Investigation on Deep Architectures for Automatic Skin Lesions Classification
Pierluigi Carcagni, Marco Leo, Andrea Cuna, Giuseppe Celeste, Cosimo Distante

Auto-TLDR; RegNet: Deep Investigation of Convolutional Neural Networks for Automatic Classification of Skin Lesions
Abstract Slides Poster Similar
Improved Residual Networks for Image and Video Recognition
Ionut Cosmin Duta, Li Liu, Fan Zhu, Ling Shao

Auto-TLDR; Residual Networks for Deep Learning
Abstract Slides Poster Similar
Hybrid Cascade Point Search Network for High Precision Bar Chart Component Detection
Junyu Luo, Jinpeng Wang, Chin-Yew Lin

Auto-TLDR; Object Detection of Chart Components in Chart Images Using Point-based and Region-Based Object Detection Framework
Abstract Slides Poster Similar
Semantic Object Segmentation in Cultural Sites Using Real and Synthetic Data
Francesco Ragusa, Daniele Di Mauro, Alfio Palermo, Antonino Furnari, Giovanni Maria Farinella

Auto-TLDR; Exploiting Synthetic Data for Object Segmentation in Cultural Sites
Abstract Slides Poster Similar