Making Every Label Count: Handling Semantic Imprecision by Integrating Domain Knowledge
Clemens-Alexander Brust,
Björn Barz,
Joachim Denzler

Auto-TLDR; Class Hierarchies for Imprecise Label Learning and Annotation eXtrapolation
Similar papers
Towards Robust Learning with Different Label Noise Distributions
Diego Ortego, Eric Arazo, Paul Albert, Noel E O'Connor, Kevin Mcguinness

Auto-TLDR; Distribution Robust Pseudo-Labeling with Semi-supervised Learning
Exploiting Knowledge Embedded Soft Labels for Image Recognition
Lixian Yuan, Riquan Chen, Hefeng Wu, Tianshui Chen, Wentao Wang, Pei Chen

Auto-TLDR; A Soft Label Vector for Image Recognition
Abstract Slides Poster Similar
Hierarchical Classification with Confidence Using Generalized Logits
James W. Davis, Tong Liang, James Enouen, Roman Ilin

Auto-TLDR; Generalized Logits for Hierarchical Classification
Abstract Slides Poster Similar
Iterative Label Improvement: Robust Training by Confidence Based Filtering and Dataset Partitioning
Christian Haase-Schütz, Rainer Stal, Heinz Hertlein, Bernhard Sick

Auto-TLDR; Meta Training and Labelling for Unlabelled Data
Abstract Slides Poster Similar
Contextual Classification Using Self-Supervised Auxiliary Models for Deep Neural Networks
Sebastian Palacio, Philipp Engler, Jörn Hees, Andreas Dengel

Auto-TLDR; Self-Supervised Autogenous Learning for Deep Neural Networks
Abstract Slides Poster Similar
P-DIFF: Learning Classifier with Noisy Labels Based on Probability Difference Distributions
Wei Hu, Qihao Zhao, Yangyu Huang, Fan Zhang

Auto-TLDR; P-DIFF: A Simple and Effective Training Paradigm for Deep Neural Network Classifier with Noisy Labels
Abstract Slides Poster Similar
A CNN-RNN Framework for Image Annotation from Visual Cues and Social Network Metadata
Tobia Tesan, Pasquale Coscia, Lamberto Ballan

Auto-TLDR; Context-Based Image Annotation with Multiple Semantic Embeddings and Recurrent Neural Networks
Abstract Slides Poster Similar
Quasibinary Classifier for Images with Zero and Multiple Labels
Liao Shuai, Efstratios Gavves, Changyong Oh, Cees Snoek

Auto-TLDR; Quasibinary Classifiers for Zero-label and Multi-label Classification
Abstract Slides Poster Similar
Learning Embeddings for Image Clustering: An Empirical Study of Triplet Loss Approaches
Kalun Ho, Janis Keuper, Franz-Josef Pfreundt, Margret Keuper

Auto-TLDR; Clustering Objectives for K-means and Correlation Clustering Using Triplet Loss
Abstract Slides Poster Similar
Few-Shot Few-Shot Learning and the Role of Spatial Attention
Yann Lifchitz, Yannis Avrithis, Sylvaine Picard

Auto-TLDR; Few-shot Learning with Pre-trained Classifier on Large-Scale Datasets
Abstract Slides Poster Similar
Overcoming Noisy and Irrelevant Data in Federated Learning
Tiffany Tuor, Shiqiang Wang, Bong Jun Ko, Changchang Liu, Kin K Leung

Auto-TLDR; Distributedly Selecting Relevant Data for Federated Learning
Abstract Slides Poster Similar
Generative Latent Implicit Conditional Optimization When Learning from Small Sample

Auto-TLDR; GLICO: Generative Latent Implicit Conditional Optimization for Small Sample Learning
Abstract Slides Poster Similar
Multi-Attribute Learning with Highly Imbalanced Data
Lady Viviana Beltran Beltran, Mickaël Coustaty, Nicholas Journet, Juan C. Caicedo, Antoine Doucet

Auto-TLDR; Data Imbalance in Multi-Attribute Deep Learning Models: Adaptation to face each one of the problems derived from imbalance
Abstract Slides Poster Similar
Multi-Task Learning for Calorie Prediction on a Novel Large-Scale Recipe Dataset Enriched with Nutritional Information
Robin Ruede, Verena Heusser, Lukas Frank, Monica Haurilet, Alina Roitberg, Rainer Stiefelhagen

Auto-TLDR; Pic2kcal: Learning Food Recipes from Images for Calorie Estimation
Abstract Slides Poster Similar
A Fine-Grained Dataset and Its Efficient Semantic Segmentation for Unstructured Driving Scenarios
Kai Andreas Metzger, Peter Mortimer, Hans J "Joe" Wuensche

Auto-TLDR; TAS500: A Semantic Segmentation Dataset for Autonomous Driving in Unstructured Environments
Abstract Slides Poster Similar
Trainable Spectrally Initializable Matrix Transformations in Convolutional Neural Networks
Michele Alberti, Angela Botros, Schuetz Narayan, Rolf Ingold, Marcus Liwicki, Mathias Seuret

Auto-TLDR; Trainable and Spectrally Initializable Matrix Transformations for Neural Networks
Abstract Slides Poster Similar
Aerial Road Segmentation in the Presence of Topological Label Noise
Corentin Henry, Friedrich Fraundorfer, Eleonora Vig

Auto-TLDR; Improving Road Segmentation with Noise-Aware U-Nets for Fine-Grained Topology delineation
Abstract Slides Poster Similar
Meta Soft Label Generation for Noisy Labels

Auto-TLDR; MSLG: Meta-Learning for Noisy Label Generation
Abstract Slides Poster Similar
A Simple Domain Shifting Network for Generating Low Quality Images
Guruprasad Hegde, Avinash Nittur Ramesh, Kanchana Vaishnavi Gandikota, Michael Möller, Roman Obermaisser

Auto-TLDR; Robotic Image Classification Using Quality degrading networks
Abstract Slides Poster Similar
Knowledge Distillation Beyond Model Compression
Fahad Sarfraz, Elahe Arani, Bahram Zonooz

Auto-TLDR; Knowledge Distillation from Teacher to Student
Abstract Slides Poster Similar
Stochastic Label Refinery: Toward Better Target Label Distribution
Xi Fang, Jiancheng Yang, Bingbing Ni

Auto-TLDR; Stochastic Label Refinery for Deep Supervised Learning
Abstract Slides Poster Similar
Semantics to Space(S2S): Embedding Semantics into Spatial Space for Zero-Shot Verb-Object Query Inferencing

Auto-TLDR; Semantics-to-Space: Deep Zero-Shot Learning for Verb-Object Interaction with Vectors
Abstract Slides Poster Similar
Verifying the Causes of Adversarial Examples
Honglin Li, Yifei Fan, Frieder Ganz, Tony Yezzi, Payam Barnaghi

Auto-TLDR; Exploring the Causes of Adversarial Examples in Neural Networks
Abstract Slides Poster Similar
Webly Supervised Image-Text Embedding with Noisy Tag Refinement
Niluthpol Mithun, Ravdeep Pasricha, Evangelos Papalexakis, Amit Roy-Chowdhury

Auto-TLDR; Robust Joint Embedding for Image-Text Retrieval Using Web Images
Equation Attention Relationship Network (EARN) : A Geometric Deep Metric Framework for Learning Similar Math Expression Embedding
Saleem Ahmed, Kenny Davila, Srirangaraj Setlur, Venu Govindaraju

Auto-TLDR; Representational Learning for Similarity Based Retrieval of Mathematical Expressions
Abstract Slides Poster Similar
Zero-Shot Text Classification with Semantically Extended Graph Convolutional Network
Tengfei Liu, Yongli Hu, Junbin Gao, Yanfeng Sun, Baocai Yin

Auto-TLDR; Semantically Extended Graph Convolutional Network for Zero-shot Text Classification
Abstract Slides Poster Similar
Self-Supervised Learning for Astronomical Image Classification
Ana Martinazzo, Mateus Espadoto, Nina S. T. Hirata

Auto-TLDR; Unlabeled Astronomical Images for Deep Neural Network Pre-training
Abstract Slides Poster Similar
Learning Natural Thresholds for Image Ranking
Somayeh Keshavarz, Quang Nhat Tran, Richard Souvenir

Auto-TLDR; Image Representation Learning and Label Discretization for Natural Image Ranking
Abstract Slides Poster Similar
Developing Motion Code Embedding for Action Recognition in Videos
Maxat Alibayev, David Andrea Paulius, Yu Sun

Auto-TLDR; Motion Embedding via Motion Codes for Action Recognition
Abstract Slides Poster Similar
Weakly Supervised Learning through Rank-Based Contextual Measures
João Gabriel Camacho Presotto, Lucas Pascotti Valem, Nikolas Gomes De Sá, Daniel Carlos Guimaraes Pedronette, Joao Paulo Papa

Auto-TLDR; Exploiting Unlabeled Data for Weakly Supervised Classification of Multimedia Data
Abstract Slides Poster Similar
Supervised Domain Adaptation Using Graph Embedding
Lukas Hedegaard, Omar Ali Sheikh-Omar, Alexandros Iosifidis

Auto-TLDR; Domain Adaptation from the Perspective of Multi-view Graph Embedding and Dimensionality Reduction
Abstract Slides Poster Similar
Rethinking Domain Generalization Baselines
Francesco Cappio Borlino, Antonio D'Innocente, Tatiana Tommasi

Auto-TLDR; Style Transfer Data Augmentation for Domain Generalization
Abstract Slides Poster Similar
FashionGraph: Understanding Fashion Data Using Scene Graph Generation
Shabnam Sadegharmaki, Marc A. Kastner, Shin'Ichi Satoh
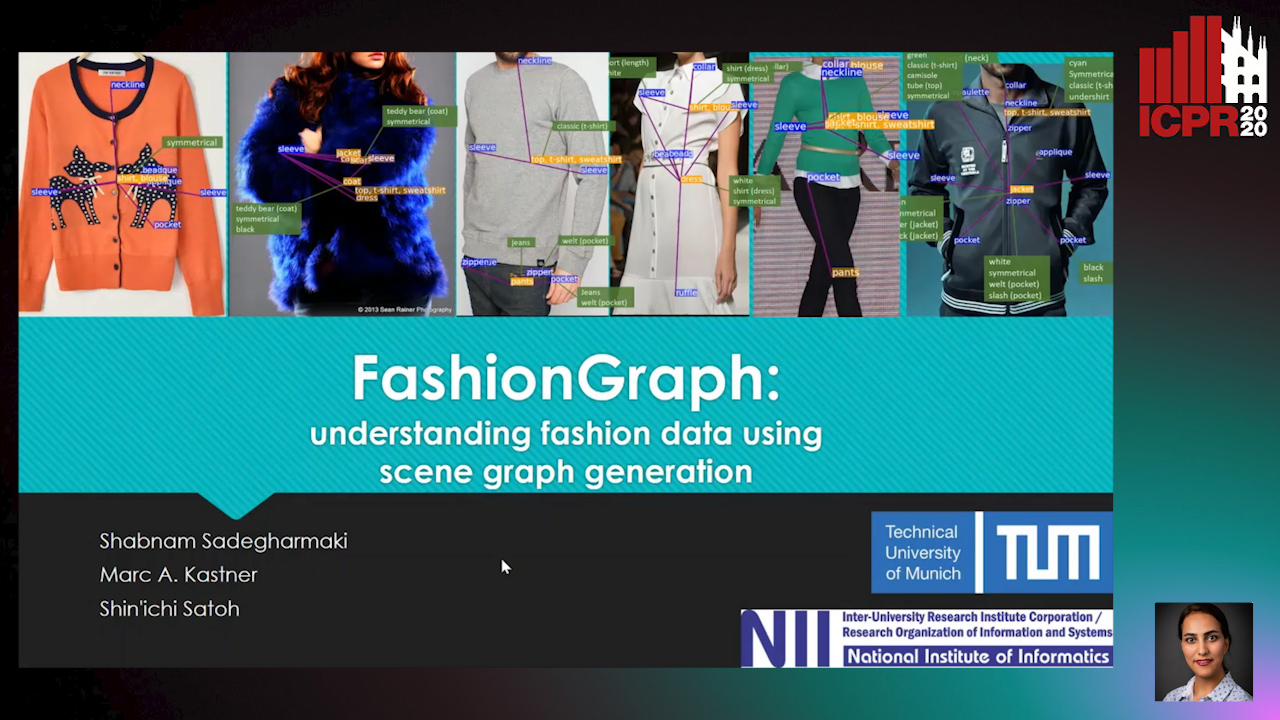
Auto-TLDR; Exploiting Scene Graph Knowledge for Fashion Applications
Derivation of Geometrically and Semantically Annotated UAV Datasets at Large Scales from 3D City Models
Sidi Wu, Lukas Liebel, Marco Körner

Auto-TLDR; Large-Scale Dataset of Synthetic UAV Imagery for Geometric and Semantic Annotation
Abstract Slides Poster Similar
A Systematic Investigation on End-To-End Deep Recognition of Grocery Products in the Wild
Marco Leo, Pierluigi Carcagni, Cosimo Distante

Auto-TLDR; Automatic Recognition of Products on grocery shelf images using Convolutional Neural Networks
Abstract Slides Poster Similar
Multi-Order Feature Statistical Model for Fine-Grained Visual Categorization
Qingtao Wang, Ke Zhang, Shaoli Huang, Lianbo Zhang, Jin Fan

Auto-TLDR; Multi-Order Feature Statistical Method for Fine-Grained Visual Categorization
Abstract Slides Poster Similar
Joint Supervised and Self-Supervised Learning for 3D Real World Challenges
Antonio Alliegro, Davide Boscaini, Tatiana Tommasi

Auto-TLDR; Self-supervision for 3D Shape Classification and Segmentation in Point Clouds
Hierarchical Routing Mixture of Experts
Wenbo Zhao, Yang Gao, Shahan Ali Memon, Bhiksha Raj, Rita Singh

Auto-TLDR; A Binary Tree-structured Hierarchical Routing Mixture of Experts for Regression
Abstract Slides Poster Similar
Improving Model Accuracy for Imbalanced Image Classification Tasks by Adding a Final Batch Normalization Layer: An Empirical Study
Veysel Kocaman, Ofer M. Shir, Thomas Baeck

Auto-TLDR; Exploiting Batch Normalization before the Output Layer in Deep Learning for Minority Class Detection in Imbalanced Data Sets
Abstract Slides Poster Similar
Local Propagation for Few-Shot Learning
Yann Lifchitz, Yannis Avrithis, Sylvaine Picard

Auto-TLDR; Local Propagation for Few-Shot Inference
Abstract Slides Poster Similar
Deep Convolutional Embedding for Digitized Painting Clustering
Giovanna Castellano, Gennaro Vessio

Auto-TLDR; A Deep Convolutional Embedding Model for Clustering Artworks
Abstract Slides Poster Similar
Towards Tackling Multi-Label Imbalances in Remote Sensing Imagery
Dominik Koßmann, Thorsten Wilhelm, Gernot Fink

Auto-TLDR; Class imbalance in land cover datasets using attribute encoding schemes
Abstract Slides Poster Similar
Improving Visual Relation Detection Using Depth Maps
Sahand Sharifzadeh, Sina Moayed Baharlou, Max Berrendorf, Rajat Koner, Volker Tresp

Auto-TLDR; Exploiting Depth Maps for Visual Relation Detection
Abstract Slides Poster Similar
Graph-Based Interpolation of Feature Vectors for Accurate Few-Shot Classification
Yuqing Hu, Vincent Gripon, Stéphane Pateux

Auto-TLDR; Transductive Learning for Few-Shot Classification using Graph Neural Networks
Abstract Slides Poster Similar
Open Set Domain Recognition Via Attention-Based GCN and Semantic Matching Optimization
Xinxing He, Yuan Yuan, Zhiyu Jiang

Auto-TLDR; Attention-based GCN and Semantic Matching Optimization for Open Set Domain Recognition
Abstract Slides Poster Similar
Text Recognition - Real World Data and Where to Find Them
Klára Janoušková, Lluis Gomez, Dimosthenis Karatzas, Jiri Matas

Auto-TLDR; Exploiting Weakly Annotated Images for Text Extraction
Abstract Slides Poster Similar
Confidence Calibration for Deep Renal Biopsy Immunofluorescence Image Classification
Federico Pollastri, Juan Maroñas, Federico Bolelli, Giulia Ligabue, Roberto Paredes, Riccardo Magistroni, Costantino Grana

Auto-TLDR; A Probabilistic Convolutional Neural Network for Immunofluorescence Classification in Renal Biopsy
Abstract Slides Poster Similar
Semantic Bilinear Pooling for Fine-Grained Recognition
Xinjie Li, Chun Yang, Song-Lu Chen, Chao Zhu, Xu-Cheng Yin

Auto-TLDR; Semantic bilinear pooling for fine-grained recognition with hierarchical label tree
Abstract Slides Poster Similar