Multi-Task Learning for Calorie Prediction on a Novel Large-Scale Recipe Dataset Enriched with Nutritional Information
Robin Ruede,
Verena Heusser,
Lukas Frank,
Monica Haurilet,
Alina Roitberg,
Rainer Stiefelhagen

Auto-TLDR; Pic2kcal: Learning Food Recipes from Images for Calorie Estimation
Similar papers
Picture-To-Amount (PITA): Predicting Relative Ingredient Amounts from Food Images
Jiatong Li, Fangda Han, Ricardo Guerrero, Vladimir Pavlovic

Auto-TLDR; PITA: A Deep Learning Architecture for Predicting the Relative Amount of Ingredients from Food Images
Abstract Slides Poster Similar
RWMF: A Real-World Multimodal Foodlog Database
Pengfei Zhou, Cong Bai, Kaining Ying, Jie Xia, Lixin Huang
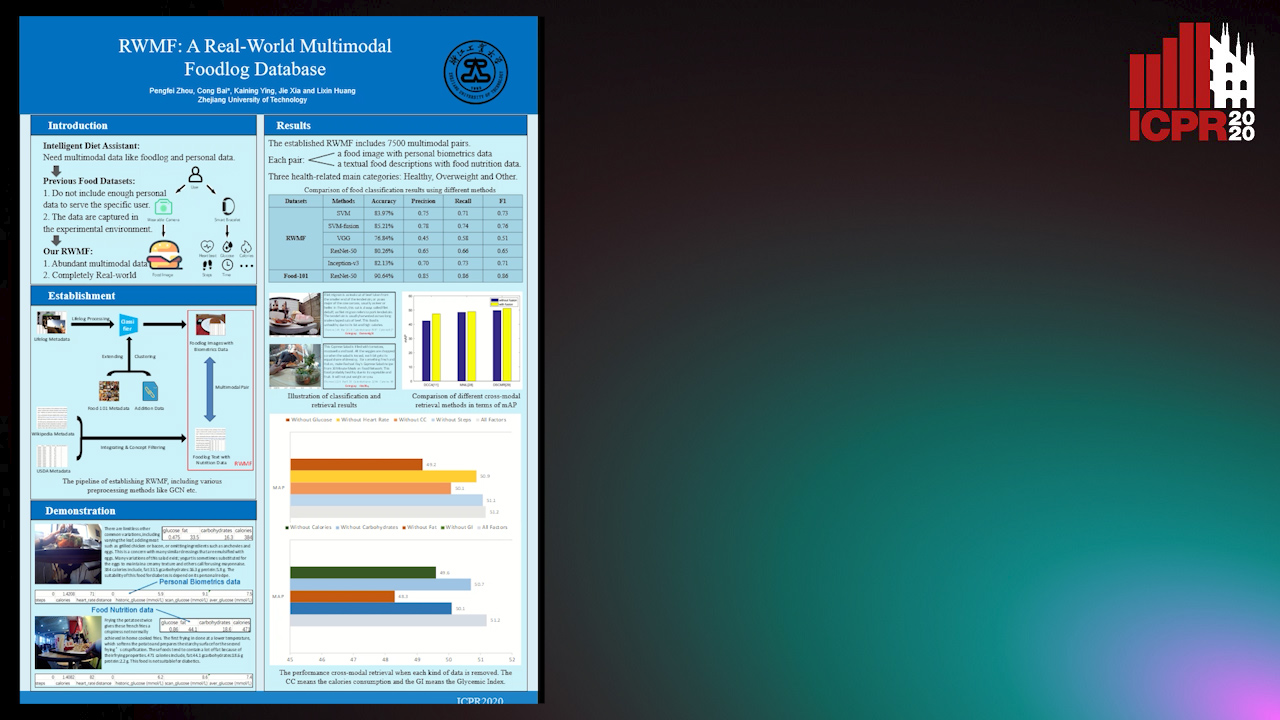
Auto-TLDR; Real-World Multimodal Foodlog: A Real-World Foodlog Database for Diet Assistant
Abstract Slides Poster Similar
Partially Supervised Multi-Task Network for Single-View Dietary Assessment
Ya Lu, Thomai Stathopoulou, Stavroula Mougiakakou

Auto-TLDR; Food Volume Estimation from a Single Food Image via Geometric Understanding and Semantic Prediction
Abstract Slides Poster Similar
Making Every Label Count: Handling Semantic Imprecision by Integrating Domain Knowledge
Clemens-Alexander Brust, Björn Barz, Joachim Denzler

Auto-TLDR; Class Hierarchies for Imprecise Label Learning and Annotation eXtrapolation
Abstract Slides Poster Similar
Uncertainty-Aware Data Augmentation for Food Recognition
Eduardo Aguilar, Bhalaji Nagarajan, Rupali Khatun, Marc Bolaños, Petia Radeva

Auto-TLDR; Data Augmentation for Food Recognition Using Epistemic Uncertainty
Abstract Slides Poster Similar
A Systematic Investigation on End-To-End Deep Recognition of Grocery Products in the Wild
Marco Leo, Pierluigi Carcagni, Cosimo Distante

Auto-TLDR; Automatic Recognition of Products on grocery shelf images using Convolutional Neural Networks
Abstract Slides Poster Similar
Self-Supervised Learning for Astronomical Image Classification
Ana Martinazzo, Mateus Espadoto, Nina S. T. Hirata

Auto-TLDR; Unlabeled Astronomical Images for Deep Neural Network Pre-training
Abstract Slides Poster Similar
Contextual Classification Using Self-Supervised Auxiliary Models for Deep Neural Networks
Sebastian Palacio, Philipp Engler, Jörn Hees, Andreas Dengel

Auto-TLDR; Self-Supervised Autogenous Learning for Deep Neural Networks
Abstract Slides Poster Similar
Multi-Modal Deep Clustering: Unsupervised Partitioning of Images

Auto-TLDR; Multi-Modal Deep Clustering for Unlabeled Images
Abstract Slides Poster Similar
A CNN-RNN Framework for Image Annotation from Visual Cues and Social Network Metadata
Tobia Tesan, Pasquale Coscia, Lamberto Ballan

Auto-TLDR; Context-Based Image Annotation with Multiple Semantic Embeddings and Recurrent Neural Networks
Abstract Slides Poster Similar
Adversarial Encoder-Multi-Task-Decoder for Multi-Stage Processes
Andre Mendes, Julian Togelius, Leandro Dos Santos Coelho

Auto-TLDR; Multi-Task Learning and Semi-Supervised Learning for Multi-Stage Processes
Deep Gait Relative Attribute Using a Signed Quadratic Contrastive Loss
Yuta Hayashi, Shehata Allam, Yasushi Makihara, Daigo Muramatsu, Yasushi Yagi

Auto-TLDR; Signal-Contrastive Loss for Gait Attributes Estimation
Price Suggestion for Online Second-Hand Items
Liang Han, Zhaozheng Yin, Zhurong Xia, Li Guo, Mingqian Tang, Rong Jin
Auto-TLDR; An Intelligent Price Suggestion System for Online Second-hand Items
Abstract Slides Poster Similar
Attentive Visual Semantic Specialized Network for Video Captioning
Jesus Perez-Martin, Benjamin Bustos, Jorge Pérez

Auto-TLDR; Adaptive Visual Semantic Specialized Network for Video Captioning
Abstract Slides Poster Similar
Bridging the Gap between Natural and Medical Images through Deep Colorization
Lia Morra, Luca Piano, Fabrizio Lamberti, Tatiana Tommasi

Auto-TLDR; Transfer Learning for Diagnosis on X-ray Images Using Color Adaptation
Abstract Slides Poster Similar
Text Synopsis Generation for Egocentric Videos
Aidean Sharghi, Niels Lobo, Mubarak Shah

Auto-TLDR; Egocentric Video Summarization Using Multi-task Learning for End-to-End Learning
Uncertainty-Sensitive Activity Recognition: A Reliability Benchmark and the CARING Models
Alina Roitberg, Monica Haurilet, Manuel Martinez, Rainer Stiefelhagen

Auto-TLDR; CARING: Calibrated Action Recognition with Input Guidance
Towards Tackling Multi-Label Imbalances in Remote Sensing Imagery
Dominik Koßmann, Thorsten Wilhelm, Gernot Fink

Auto-TLDR; Class imbalance in land cover datasets using attribute encoding schemes
Abstract Slides Poster Similar
Emerging Relation Network and Task Embedding for Multi-Task Regression Problems

Auto-TLDR; A Comparative Study of Multi-Task Learning for Non-linear Time Series Problems
Abstract Slides Poster Similar
Weight Estimation from an RGB-D Camera in Top-View Configuration
Marco Mameli, Marina Paolanti, Nicola Conci, Filippo Tessaro, Emanuele Frontoni, Primo Zingaretti

Auto-TLDR; Top-View Weight Estimation using Deep Neural Networks
Abstract Slides Poster Similar
Learning Neural Textual Representations for Citation Recommendation
Thanh Binh Kieu, Inigo Jauregi Unanue, Son Bao Pham, Xuan-Hieu Phan, M. Piccardi

Auto-TLDR; Sentence-BERT cascaded with Siamese and triplet networks for citation recommendation
Abstract Slides Poster Similar
Exploiting the Logits: Joint Sign Language Recognition and Spell-Correction
Christina Runkel, Stefan Dorenkamp, Hartmut Bauermeister, Michael Möller

Auto-TLDR; A Convolutional Neural Network for Spell-correction in Sign Language Videos
Abstract Slides Poster Similar
DR2S: Deep Regression with Region Selection for Camera Quality Evaluation
Marcelin Tworski, Stéphane Lathuiliere, Salim Belkarfa, Attilio Fiandrotti, Marco Cagnazzo

Auto-TLDR; Texture Quality Estimation Using Deep Learning
Abstract Slides Poster Similar
FC-DCNN: A Densely Connected Neural Network for Stereo Estimation
Dominik Hirner, Friedrich Fraundorfer

Auto-TLDR; FC-DCNN: A Lightweight Network for Stereo Estimation
Abstract Slides Poster Similar
Large-Scale Historical Watermark Recognition: Dataset and a New Consistency-Based Approach
Xi Shen, Ilaria Pastrolin, Oumayma Bounou, Spyros Gidaris, Marc Smith, Olivier Poncet, Mathieu Aubry

Auto-TLDR; Historical Watermark Recognition with Fine-Grained Cross-Domain One-Shot Instance Recognition
Abstract Slides Poster Similar
Iterative Label Improvement: Robust Training by Confidence Based Filtering and Dataset Partitioning
Christian Haase-Schütz, Rainer Stal, Heinz Hertlein, Bernhard Sick

Auto-TLDR; Meta Training and Labelling for Unlabelled Data
Abstract Slides Poster Similar
Predicting Chemical Properties Using Self-Attention Multi-Task Learning Based on SMILES Representation

Auto-TLDR; Self-attention based Transformer-Variant Model for Chemical Compound Properties Prediction
Abstract Slides Poster Similar
ESResNet: Environmental Sound Classification Based on Visual Domain Models
Andrey Guzhov, Federico Raue, Jörn Hees, Andreas Dengel

Auto-TLDR; Environmental Sound Classification with Short-Time Fourier Transform Spectrograms
Abstract Slides Poster Similar
Smart Inference for Multidigit Convolutional Neural Network Based Barcode Decoding
Duy-Thao Do, Tolcha Yalew, Tae Joon Jun, Daeyoung Kim

Auto-TLDR; Smart Inference for Barcode Decoding using Deep Convolutional Neural Network
Abstract Slides Poster Similar
A Systematic Investigation on Deep Architectures for Automatic Skin Lesions Classification
Pierluigi Carcagni, Marco Leo, Andrea Cuna, Giuseppe Celeste, Cosimo Distante

Auto-TLDR; RegNet: Deep Investigation of Convolutional Neural Networks for Automatic Classification of Skin Lesions
Abstract Slides Poster Similar
Webly Supervised Image-Text Embedding with Noisy Tag Refinement
Niluthpol Mithun, Ravdeep Pasricha, Evangelos Papalexakis, Amit Roy-Chowdhury

Auto-TLDR; Robust Joint Embedding for Image-Text Retrieval Using Web Images
Improving Model Accuracy for Imbalanced Image Classification Tasks by Adding a Final Batch Normalization Layer: An Empirical Study
Veysel Kocaman, Ofer M. Shir, Thomas Baeck

Auto-TLDR; Exploiting Batch Normalization before the Output Layer in Deep Learning for Minority Class Detection in Imbalanced Data Sets
Abstract Slides Poster Similar
Enriching Video Captions with Contextual Text
Philipp Rimle, Pelin Dogan, Markus Gross

Auto-TLDR; Contextualized Video Captioning Using Contextual Text
Abstract Slides Poster Similar
Video Face Manipulation Detection through Ensemble of CNNs
Nicolo Bonettini, Edoardo Daniele Cannas, Sara Mandelli, Luca Bondi, Paolo Bestagini, Stefano Tubaro

Auto-TLDR; Face Manipulation Detection in Video Sequences Using Convolutional Neural Networks
Detective: An Attentive Recurrent Model for Sparse Object Detection
Amine Kechaou, Manuel Martinez, Monica Haurilet, Rainer Stiefelhagen

Auto-TLDR; Detective: An attentive object detector that identifies objects in images in a sequential manner
Abstract Slides Poster Similar
Ballroom Dance Recognition from Audio Recordings
Tomas Pavlin, Jan Cech, Jiri Matas

Auto-TLDR; A CNN-based approach to classify ballroom dances given audio recordings
Abstract Slides Poster Similar
An Evaluation of DNN Architectures for Page Segmentation of Historical Newspapers
Manuel Burghardt, Bernhard Liebl

Auto-TLDR; Evaluation of Backbone Architectures for Optical Character Segmentation of Historical Documents
Abstract Slides Poster Similar
End-To-End Hierarchical Relation Extraction for Generic Form Understanding
Tuan Anh Nguyen Dang, Duc-Thanh Hoang, Quang Bach Tran, Chih-Wei Pan, Thanh-Dat Nguyen

Auto-TLDR; Joint Entity Labeling and Link Prediction for Form Understanding in Noisy Scanned Documents
Abstract Slides Poster Similar
A Novel Attention-Based Aggregation Function to Combine Vision and Language
Matteo Stefanini, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara

Auto-TLDR; Fully-Attentive Reduction for Vision and Language
Abstract Slides Poster Similar
Learning from Web Data: Improving Crowd Counting Via Semi-Supervised Learning

Auto-TLDR; Semi-supervised Crowd Counting Baseline for Deep Neural Networks
Abstract Slides Poster Similar
Cross-Lingual Text Image Recognition Via Multi-Task Sequence to Sequence Learning
Zhuo Chen, Fei Yin, Xu-Yao Zhang, Qing Yang, Cheng-Lin Liu

Auto-TLDR; Cross-Lingual Text Image Recognition with Multi-task Learning
Abstract Slides Poster Similar
Confidence Calibration for Deep Renal Biopsy Immunofluorescence Image Classification
Federico Pollastri, Juan Maroñas, Federico Bolelli, Giulia Ligabue, Roberto Paredes, Riccardo Magistroni, Costantino Grana

Auto-TLDR; A Probabilistic Convolutional Neural Network for Immunofluorescence Classification in Renal Biopsy
Abstract Slides Poster Similar
Conditional Multi-Task Learning for Plant Disease Identification
Sue Han Lee, Herve Goëau, Pierre Bonnet, Alexis Joly

Auto-TLDR; A conditional multi-task learning approach for plant disease identification
Abstract Slides Poster Similar
How Unique Is a Face: An Investigative Study
Michal Balazia, S L Happy, Francois Bremond, Antitza Dantcheva

Auto-TLDR; Uniqueness of Face Recognition: Exploring the Impact of Factors such as image resolution, feature representation, database size, age and gender
Abstract Slides Poster Similar
Multimodal Side-Tuning for Document Classification
Stefano Zingaro, Giuseppe Lisanti, Maurizio Gabbrielli

Auto-TLDR; Side-tuning for Multimodal Document Classification
Abstract Slides Poster Similar
The DeepHealth Toolkit: A Unified Framework to Boost Biomedical Applications
Michele Cancilla, Laura Canalini, Federico Bolelli, Stefano Allegretti, Salvador Carrión, Roberto Paredes, Jon Ander Gómez, Simone Leo, Marco Enrico Piras, Luca Pireddu, Asaf Badouh, Santiago Marco-Sola, Lluc Alvarez, Miquel Moreto, Costantino Grana

Auto-TLDR; DeepHealth Toolkit: An Open Source Deep Learning Toolkit for Cloud Computing and HPC
Abstract Slides Poster Similar
Improving Word Recognition Using Multiple Hypotheses and Deep Embeddings
Siddhant Bansal, Praveen Krishnan, C. V. Jawahar

Auto-TLDR; EmbedNet: fuse recognition-based and recognition-free approaches for word recognition using learning-based methods
Abstract Slides Poster Similar
RMS-Net: Regression and Masking for Soccer Event Spotting
Matteo Tomei, Lorenzo Baraldi, Simone Calderara, Simone Bronzin, Rita Cucchiara

Auto-TLDR; An Action Spotting Network for Soccer Videos
Abstract Slides Poster Similar