Uncertainty-Aware Data Augmentation for Food Recognition
Eduardo Aguilar,
Bhalaji Nagarajan,
Rupali Khatun,
Marc Bolaños,
Petia Radeva

Auto-TLDR; Data Augmentation for Food Recognition Using Epistemic Uncertainty
Similar papers
Augmentation of Small Training Data Using GANs for Enhancing the Performance of Image Classification

Auto-TLDR; Generative Adversarial Network for Image Training Data Augmentation
Abstract Slides Poster Similar
Minority Class Oriented Active Learning for Imbalanced Datasets
Umang Aggarwal, Adrian Popescu, Celine Hudelot

Auto-TLDR; Active Learning for Imbalanced Datasets
Abstract Slides Poster Similar
A Systematic Investigation on Deep Architectures for Automatic Skin Lesions Classification
Pierluigi Carcagni, Marco Leo, Andrea Cuna, Giuseppe Celeste, Cosimo Distante

Auto-TLDR; RegNet: Deep Investigation of Convolutional Neural Networks for Automatic Classification of Skin Lesions
Abstract Slides Poster Similar
Data Augmentation Via Mixed Class Interpolation Using Cycle-Consistent Generative Adversarial Networks Applied to Cross-Domain Imagery
Hiroshi Sasaki, Chris G. Willcocks, Toby Breckon

Auto-TLDR; C2GMA: A Generative Domain Transfer Model for Non-visible Domain Classification
Abstract Slides Poster Similar
Picture-To-Amount (PITA): Predicting Relative Ingredient Amounts from Food Images
Jiatong Li, Fangda Han, Ricardo Guerrero, Vladimir Pavlovic

Auto-TLDR; PITA: A Deep Learning Architecture for Predicting the Relative Amount of Ingredients from Food Images
Abstract Slides Poster Similar
Learning to Rank for Active Learning: A Listwise Approach
Minghan Li, Xialei Liu, Joost Van De Weijer, Bogdan Raducanu

Auto-TLDR; Learning Loss for Active Learning
A Close Look at Deep Learning with Small Data

Auto-TLDR; Low-Complex Neural Networks for Small Data Conditions
Abstract Slides Poster Similar
Leveraging Synthetic Subject Invariant EEG Signals for Zero Calibration BCI
Nik Khadijah Nik Aznan, Amir Atapour-Abarghouei, Stephen Bonner, Jason Connolly, Toby Breckon

Auto-TLDR; SIS-GAN: Subject Invariant SSVEP Generative Adversarial Network for Brain-Computer Interface
SAGE: Sequential Attribute Generator for Analyzing Glioblastomas Using Limited Dataset
Padmaja Jonnalagedda, Brent Weinberg, Jason Allen, Taejin Min, Shiv Bhanu, Bir Bhanu

Auto-TLDR; SAGE: Generative Adversarial Networks for Imaging Biomarker Detection and Prediction
Abstract Slides Poster Similar
Multi-Task Learning for Calorie Prediction on a Novel Large-Scale Recipe Dataset Enriched with Nutritional Information
Robin Ruede, Verena Heusser, Lukas Frank, Monica Haurilet, Alina Roitberg, Rainer Stiefelhagen

Auto-TLDR; Pic2kcal: Learning Food Recipes from Images for Calorie Estimation
Abstract Slides Poster Similar
Probability Guided Maxout
Claudio Ferrari, Stefano Berretti, Alberto Del Bimbo

Auto-TLDR; Probability Guided Maxout for CNN Training
Abstract Slides Poster Similar
Generative Latent Implicit Conditional Optimization When Learning from Small Sample

Auto-TLDR; GLICO: Generative Latent Implicit Conditional Optimization for Small Sample Learning
Abstract Slides Poster Similar
Rethinking of Deep Models Parameters with Respect to Data Distribution
Shitala Prasad, Dongyun Lin, Yiqun Li, Sheng Dong, Zaw Min Oo

Auto-TLDR; A progressive stepwise training strategy for deep neural networks
Abstract Slides Poster Similar
Estimation of Abundance and Distribution of SaltMarsh Plants from Images Using Deep Learning
Jayant Parashar, Suchendra Bhandarkar, Jacob Simon, Brian Hopkinson, Steven Pennings

Auto-TLDR; CNN-based approaches to automated plant identification and localization in salt marsh images
A Systematic Investigation on End-To-End Deep Recognition of Grocery Products in the Wild
Marco Leo, Pierluigi Carcagni, Cosimo Distante

Auto-TLDR; Automatic Recognition of Products on grocery shelf images using Convolutional Neural Networks
Abstract Slides Poster Similar
Partially Supervised Multi-Task Network for Single-View Dietary Assessment
Ya Lu, Thomai Stathopoulou, Stavroula Mougiakakou

Auto-TLDR; Food Volume Estimation from a Single Food Image via Geometric Understanding and Semantic Prediction
Abstract Slides Poster Similar
Bridging the Gap between Natural and Medical Images through Deep Colorization
Lia Morra, Luca Piano, Fabrizio Lamberti, Tatiana Tommasi

Auto-TLDR; Transfer Learning for Diagnosis on X-ray Images Using Color Adaptation
Abstract Slides Poster Similar
Confidence Calibration for Deep Renal Biopsy Immunofluorescence Image Classification
Federico Pollastri, Juan Maroñas, Federico Bolelli, Giulia Ligabue, Roberto Paredes, Riccardo Magistroni, Costantino Grana

Auto-TLDR; A Probabilistic Convolutional Neural Network for Immunofluorescence Classification in Renal Biopsy
Abstract Slides Poster Similar
Towards Tackling Multi-Label Imbalances in Remote Sensing Imagery
Dominik Koßmann, Thorsten Wilhelm, Gernot Fink

Auto-TLDR; Class imbalance in land cover datasets using attribute encoding schemes
Abstract Slides Poster Similar
RWMF: A Real-World Multimodal Foodlog Database
Pengfei Zhou, Cong Bai, Kaining Ying, Jie Xia, Lixin Huang
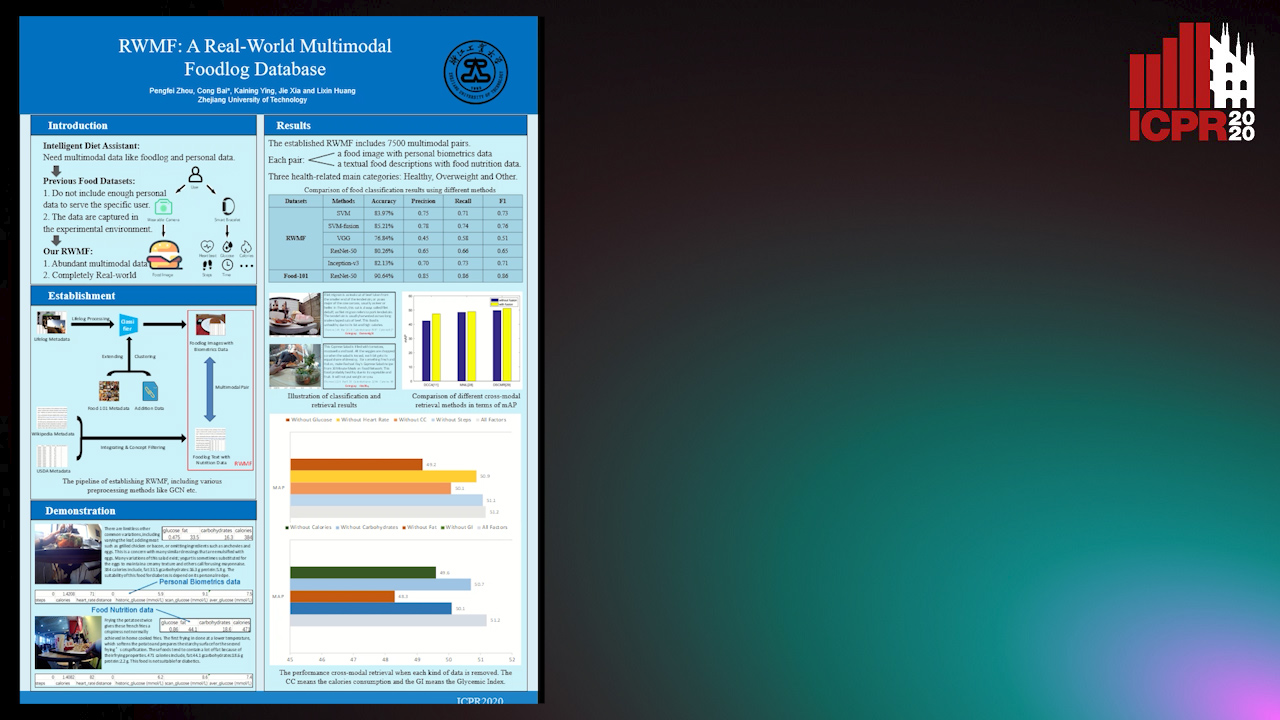
Auto-TLDR; Real-World Multimodal Foodlog: A Real-World Foodlog Database for Diet Assistant
Abstract Slides Poster Similar
IDA-GAN: A Novel Imbalanced Data Augmentation GAN

Auto-TLDR; IDA-GAN: Generative Adversarial Networks for Imbalanced Data Augmentation
Abstract Slides Poster Similar
Contextual Classification Using Self-Supervised Auxiliary Models for Deep Neural Networks
Sebastian Palacio, Philipp Engler, Jörn Hees, Andreas Dengel

Auto-TLDR; Self-Supervised Autogenous Learning for Deep Neural Networks
Abstract Slides Poster Similar
Lightweight Low-Resolution Face Recognition for Surveillance Applications
Yoanna Martínez-Díaz, Heydi Mendez-Vazquez, Luis S. Luevano, Leonardo Chang, Miguel Gonzalez-Mendoza

Auto-TLDR; Efficiency of Lightweight Deep Face Networks on Low-Resolution Surveillance Imagery
Abstract Slides Poster Similar
Unsupervised Domain Adaptation with Multiple Domain Discriminators and Adaptive Self-Training
Teo Spadotto, Marco Toldo, Umberto Michieli, Pietro Zanuttigh

Auto-TLDR; Unsupervised Domain Adaptation for Semantic Segmentation of Urban Scenes
Abstract Slides Poster Similar
Conditional Multi-Task Learning for Plant Disease Identification
Sue Han Lee, Herve Goëau, Pierre Bonnet, Alexis Joly

Auto-TLDR; A conditional multi-task learning approach for plant disease identification
Abstract Slides Poster Similar
Leveraging Quadratic Spherical Mutual Information Hashing for Fast Image Retrieval
Nikolaos Passalis, Anastasios Tefas

Auto-TLDR; Quadratic Mutual Information for Large-Scale Hashing and Information Retrieval
Abstract Slides Poster Similar
Robust Pedestrian Detection in Thermal Imagery Using Synthesized Images
My Kieu, Lorenzo Berlincioni, Leonardo Galteri, Marco Bertini, Andrew Bagdanov, Alberto Del Bimbo

Auto-TLDR; Improving Pedestrian Detection in the thermal domain using Generative Adversarial Network
Abstract Slides Poster Similar
Rethinking Deep Active Learning: Using Unlabeled Data at Model Training
Oriane Siméoni, Mateusz Budnik, Yannis Avrithis, Guillaume Gravier

Auto-TLDR; Unlabeled Data for Active Learning
Abstract Slides Poster Similar
Novel View Synthesis from a 6-DoF Pose by Two-Stage Networks
Xiang Guo, Bo Li, Yuchao Dai, Tongxin Zhang, Hui Deng

Auto-TLDR; Novel View Synthesis from a 6-DoF Pose Using Generative Adversarial Network
Abstract Slides Poster Similar
S2I-Bird: Sound-To-Image Generation of Bird Species Using Generative Adversarial Networks
Joo Yong Shim, Joongheon Kim, Jong-Kook Kim

Auto-TLDR; Generating bird images from sound using conditional generative adversarial networks
Abstract Slides Poster Similar
Creating Classifier Ensembles through Meta-Heuristic Algorithms for Aerial Scene Classification
Álvaro Roberto Ferreira Jr., Gustavo Gustavo Henrique De Rosa, Joao Paulo Papa, Gustavo Carneiro, Fabio Augusto Faria

Auto-TLDR; Univariate Marginal Distribution Algorithm for Aerial Scene Classification Using Meta-Heuristic Optimization
Abstract Slides Poster Similar
Improving Model Accuracy for Imbalanced Image Classification Tasks by Adding a Final Batch Normalization Layer: An Empirical Study
Veysel Kocaman, Ofer M. Shir, Thomas Baeck

Auto-TLDR; Exploiting Batch Normalization before the Output Layer in Deep Learning for Minority Class Detection in Imbalanced Data Sets
Abstract Slides Poster Similar
Multi-Attribute Learning with Highly Imbalanced Data
Lady Viviana Beltran Beltran, Mickaël Coustaty, Nicholas Journet, Juan C. Caicedo, Antoine Doucet

Auto-TLDR; Data Imbalance in Multi-Attribute Deep Learning Models: Adaptation to face each one of the problems derived from imbalance
Abstract Slides Poster Similar
Digit Recognition Applied to Reconstructed Audio Signals Using Deep Learning
Anastasia-Sotiria Toufa, Constantine Kotropoulos

Auto-TLDR; Compressed Sensing for Digit Recognition in Audio Reconstruction
Personalized Models in Human Activity Recognition Using Deep Learning
Hamza Amrani, Daniela Micucci, Paolo Napoletano

Auto-TLDR; Incremental Learning for Personalized Human Activity Recognition
Abstract Slides Poster Similar
On the Information of Feature Maps and Pruning of Deep Neural Networks
Mohammadreza Soltani, Suya Wu, Jie Ding, Robert Ravier, Vahid Tarokh

Auto-TLDR; Compressing Deep Neural Models Using Mutual Information
Abstract Slides Poster Similar
Video Face Manipulation Detection through Ensemble of CNNs
Nicolo Bonettini, Edoardo Daniele Cannas, Sara Mandelli, Luca Bondi, Paolo Bestagini, Stefano Tubaro

Auto-TLDR; Face Manipulation Detection in Video Sequences Using Convolutional Neural Networks
Separation of Aleatoric and Epistemic Uncertainty in Deterministic Deep Neural Networks
Denis Huseljic, Bernhard Sick, Marek Herde, Daniel Kottke

Auto-TLDR; AE-DNN: Modeling Uncertainty in Deep Neural Networks
Abstract Slides Poster Similar
Categorizing the Feature Space for Two-Class Imbalance Learning
Rosa Sicilia, Ermanno Cordelli, Paolo Soda

Auto-TLDR; Efficient Ensemble of Classifiers for Minority Class Inference
Abstract Slides Poster Similar
A Fine-Grained Dataset and Its Efficient Semantic Segmentation for Unstructured Driving Scenarios
Kai Andreas Metzger, Peter Mortimer, Hans J "Joe" Wuensche

Auto-TLDR; TAS500: A Semantic Segmentation Dataset for Autonomous Driving in Unstructured Environments
Abstract Slides Poster Similar
Learning Disentangled Representations for Identity Preserving Surveillance Face Camouflage
Jingzhi Li, Lutong Han, Hua Zhang, Xiaoguang Han, Jingguo Ge, Xiaochu Cao

Auto-TLDR; Individual Face Privacy under Surveillance Scenario with Multi-task Loss Function
Automatic Semantic Segmentation of Structural Elements related to the Spinal Cord in the Lumbar Region by Using Convolutional Neural Networks
Jhon Jairo Sáenz Gamboa, Maria De La Iglesia-Vaya, Jon Ander Gómez

Auto-TLDR; Semantic Segmentation of Lumbar Spine Using Convolutional Neural Networks
Abstract Slides Poster Similar
Smart Inference for Multidigit Convolutional Neural Network Based Barcode Decoding
Duy-Thao Do, Tolcha Yalew, Tae Joon Jun, Daeyoung Kim

Auto-TLDR; Smart Inference for Barcode Decoding using Deep Convolutional Neural Network
Abstract Slides Poster Similar
Dealing with Scarce Labelled Data: Semi-Supervised Deep Learning with Mix Match for Covid-19 Detection Using Chest X-Ray Images
Saúl Calderón Ramirez, Raghvendra Giri, Shengxiang Yang, Armaghan Moemeni, Mario Umaña, David Elizondo, Jordina Torrents-Barrena, Miguel A. Molina-Cabello

Auto-TLDR; Semi-supervised Deep Learning for Covid-19 Detection using Chest X-rays
Abstract Slides Poster Similar
Supporting Skin Lesion Diagnosis with Content-Based Image Retrieval
Stefano Allegretti, Federico Bolelli, Federico Pollastri, Sabrina Longhitano, Giovanni Pellacani, Costantino Grana

Auto-TLDR; Skin Images Retrieval Using Convolutional Neural Networks for Skin Lesion Classification and Segmentation
Abstract Slides Poster Similar
SiamMT: Real-Time Arbitrary Multi-Object Tracking
Lorenzo Vaquero, Manuel Mucientes, Victor Brea

Auto-TLDR; SiamMT: A Deep-Learning-based Arbitrary Multi-Object Tracking System for Video
Abstract Slides Poster Similar
Iterative Label Improvement: Robust Training by Confidence Based Filtering and Dataset Partitioning
Christian Haase-Schütz, Rainer Stal, Heinz Hertlein, Bernhard Sick

Auto-TLDR; Meta Training and Labelling for Unlabelled Data
Abstract Slides Poster Similar
Rethinking Domain Generalization Baselines
Francesco Cappio Borlino, Antonio D'Innocente, Tatiana Tommasi

Auto-TLDR; Style Transfer Data Augmentation for Domain Generalization
Abstract Slides Poster Similar