Estimation of Abundance and Distribution of SaltMarsh Plants from Images Using Deep Learning
Jayant Parashar,
Suchendra Bhandarkar,
Jacob Simon,
Brian Hopkinson,
Steven Pennings

Auto-TLDR; CNN-based approaches to automated plant identification and localization in salt marsh images
Similar papers
A Fine-Grained Dataset and Its Efficient Semantic Segmentation for Unstructured Driving Scenarios
Kai Andreas Metzger, Peter Mortimer, Hans J "Joe" Wuensche

Auto-TLDR; TAS500: A Semantic Segmentation Dataset for Autonomous Driving in Unstructured Environments
Abstract Slides Poster Similar
A Versatile Crack Inspection Portable System Based on Classifier Ensemble and Controlled Illumination
Milind Gajanan Padalkar, Carlos Beltran-Gonzalez, Matteo Bustreo, Alessio Del Bue, Vittorio Murino

Auto-TLDR; Lighting Conditions for Crack Detection in Ceramic Tile
Abstract Slides Poster Similar
Towards Tackling Multi-Label Imbalances in Remote Sensing Imagery
Dominik Koßmann, Thorsten Wilhelm, Gernot Fink

Auto-TLDR; Class imbalance in land cover datasets using attribute encoding schemes
Abstract Slides Poster Similar
Detecting Marine Species in Echograms Via Traditional, Hybrid, and Deep Learning Frameworks
Porto Marques Tunai, Alireza Rezvanifar, Melissa Cote, Alexandra Branzan Albu, Kaan Ersahin, Todd Mudge, Stephane Gauthier

Auto-TLDR; End-to-End Deep Learning for Echogram Interpretation of Marine Species in Echograms
Abstract Slides Poster Similar
BAT Optimized CNN Model Identifies Water Stress in Chickpea Plant Shoot Images
Shiva Azimi, Taranjit Kaur, Tapan Gandhi

Auto-TLDR; BAT Optimized ResNet-18 for Stress Classification of chickpea shoot images under water deficiency
Abstract Slides Poster Similar
Aerial Road Segmentation in the Presence of Topological Label Noise
Corentin Henry, Friedrich Fraundorfer, Eleonora Vig

Auto-TLDR; Improving Road Segmentation with Noise-Aware U-Nets for Fine-Grained Topology delineation
Abstract Slides Poster Similar
RescueNet: Joint Building Segmentation and Damage Assessment from Satellite Imagery

Auto-TLDR; RescueNet: End-to-End Building Segmentation and Damage Classification for Humanitarian Aid and Disaster Response
Abstract Slides Poster Similar
Learn to Segment Retinal Lesions and Beyond
Qijie Wei, Xirong Li, Weihong Yu, Xiao Zhang, Yongpeng Zhang, Bojie Hu, Bin Mo, Di Gong, Ning Chen, Dayong Ding, Youxin Chen

Auto-TLDR; Multi-task Lesion Segmentation and Disease Classification for Diabetic Retinopathy Grading
Motion U-Net: Multi-Cue Encoder-Decoder Network for Motion Segmentation
Gani Rahmon, Filiz Bunyak, Kannappan Palaniappan

Auto-TLDR; Motion U-Net: A Deep Learning Framework for Robust Moving Object Detection under Challenging Conditions
Abstract Slides Poster Similar
A Systematic Investigation on Deep Architectures for Automatic Skin Lesions Classification
Pierluigi Carcagni, Marco Leo, Andrea Cuna, Giuseppe Celeste, Cosimo Distante

Auto-TLDR; RegNet: Deep Investigation of Convolutional Neural Networks for Automatic Classification of Skin Lesions
Abstract Slides Poster Similar
Conditional Multi-Task Learning for Plant Disease Identification
Sue Han Lee, Herve Goëau, Pierre Bonnet, Alexis Joly

Auto-TLDR; A conditional multi-task learning approach for plant disease identification
Abstract Slides Poster Similar
Creating Classifier Ensembles through Meta-Heuristic Algorithms for Aerial Scene Classification
Álvaro Roberto Ferreira Jr., Gustavo Gustavo Henrique De Rosa, Joao Paulo Papa, Gustavo Carneiro, Fabio Augusto Faria

Auto-TLDR; Univariate Marginal Distribution Algorithm for Aerial Scene Classification Using Meta-Heuristic Optimization
Abstract Slides Poster Similar
Point In: Counting Trees with Weakly Supervised Segmentation Network
Pinmo Tong, Shuhui Bu, Pengcheng Han

Auto-TLDR; Weakly Tree counting using Deep Segmentation Network with Localization and Mask Prediction
Abstract Slides Poster Similar
End-To-End Deep Learning Methods for Automated Damage Detection in Extreme Events at Various Scales
Yongsheng Bai, Alper Yilmaz, Halil Sezen

Auto-TLDR; Robust Mask R-CNN for Crack Detection in Extreme Events
Abstract Slides Poster Similar
Bridging the Gap between Natural and Medical Images through Deep Colorization
Lia Morra, Luca Piano, Fabrizio Lamberti, Tatiana Tommasi

Auto-TLDR; Transfer Learning for Diagnosis on X-ray Images Using Color Adaptation
Abstract Slides Poster Similar
Automatic Semantic Segmentation of Structural Elements related to the Spinal Cord in the Lumbar Region by Using Convolutional Neural Networks
Jhon Jairo Sáenz Gamboa, Maria De La Iglesia-Vaya, Jon Ander Gómez

Auto-TLDR; Semantic Segmentation of Lumbar Spine Using Convolutional Neural Networks
Abstract Slides Poster Similar
Attention Pyramid Module for Scene Recognition
Zhinan Qiao, Xiaohui Yuan, Chengyuan Zhuang, Abolfazl Meyarian

Auto-TLDR; Attention Pyramid Module for Multi-Scale Scene Recognition
Abstract Slides Poster Similar
The Color Out of Space: Learning Self-Supervised Representations for Earth Observation Imagery
Stefano Vincenzi, Angelo Porrello, Pietro Buzzega, Marco Cipriano, Pietro Fronte, Roberto Cuccu, Carla Ippoliti, Annamaria Conte, Simone Calderara

Auto-TLDR; Satellite Image Representation Learning for Remote Sensing
Abstract Slides Poster Similar
Uncertainty-Aware Data Augmentation for Food Recognition
Eduardo Aguilar, Bhalaji Nagarajan, Rupali Khatun, Marc Bolaños, Petia Radeva

Auto-TLDR; Data Augmentation for Food Recognition Using Epistemic Uncertainty
Abstract Slides Poster Similar
Confidence Calibration for Deep Renal Biopsy Immunofluorescence Image Classification
Federico Pollastri, Juan Maroñas, Federico Bolelli, Giulia Ligabue, Roberto Paredes, Riccardo Magistroni, Costantino Grana

Auto-TLDR; A Probabilistic Convolutional Neural Network for Immunofluorescence Classification in Renal Biopsy
Abstract Slides Poster Similar
A Systematic Investigation on End-To-End Deep Recognition of Grocery Products in the Wild
Marco Leo, Pierluigi Carcagni, Cosimo Distante

Auto-TLDR; Automatic Recognition of Products on grocery shelf images using Convolutional Neural Networks
Abstract Slides Poster Similar
Early Wildfire Smoke Detection in Videos
Taanya Gupta, Hengyue Liu, Bir Bhanu

Auto-TLDR; Semi-supervised Spatio-Temporal Video Object Segmentation for Automatic Detection of Smoke in Videos during Forest Fire
Rethinking of Deep Models Parameters with Respect to Data Distribution
Shitala Prasad, Dongyun Lin, Yiqun Li, Sheng Dong, Zaw Min Oo

Auto-TLDR; A progressive stepwise training strategy for deep neural networks
Abstract Slides Poster Similar
Attention Based Coupled Framework for Road and Pothole Segmentation
Shaik Masihullah, Ritu Garg, Prerana Mukherjee, Anupama Ray

Auto-TLDR; Few Shot Learning for Road and Pothole Segmentation on KITTI and IDD
Abstract Slides Poster Similar
Global-Local Attention Network for Semantic Segmentation in Aerial Images
Minglong Li, Lianlei Shan, Weiqiang Wang

Auto-TLDR; GLANet: Global-Local Attention Network for Semantic Segmentation
Abstract Slides Poster Similar
Dual Encoder Fusion U-Net (DEFU-Net) for Cross-manufacturer Chest X-Ray Segmentation
Zhang Lipei, Aozhi Liu, Jing Xiao
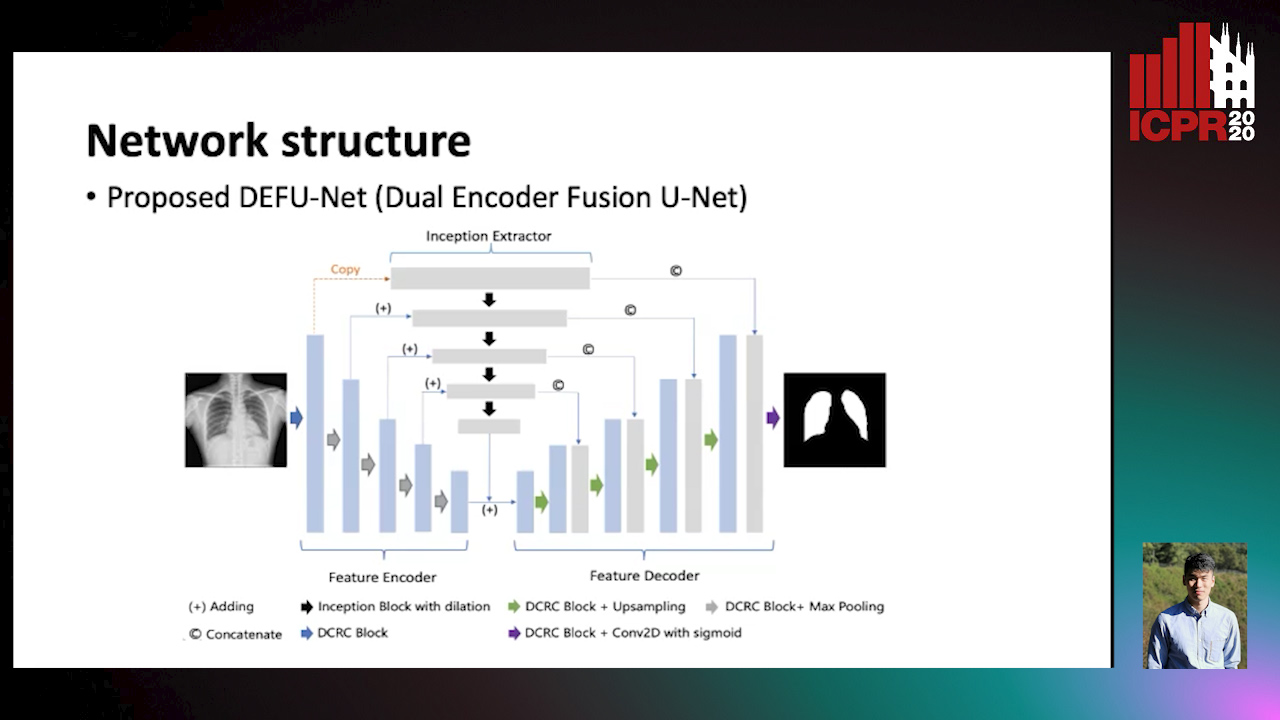
Auto-TLDR; Inception Convolutional Neural Network with Dilation for Chest X-Ray Segmentation
Segmentation of Intracranial Aneurysm Remnant in MRA Using Dual-Attention Atrous Net
Subhashis Banerjee, Ashis Kumar Dhara, Johan Wikström, Robin Strand

Auto-TLDR; Dual-Attention Atrous Net for Segmentation of Intracranial Aneurysm Remnant from MRA Images
Abstract Slides Poster Similar
Uncertainty Guided Recognition of Tiny Craters on the Moon
Thorsten Wilhelm, Christian Wöhler

Auto-TLDR; Accurately Detecting Tiny Craters in Remote Sensed Images Using Deep Neural Networks
Abstract Slides Poster Similar
A Hierarchical Framework for Leaf Instance Segmentation: Application to Plant Phenotyping
Swati Bhugra, Kanish Garg, Santanu Chaudhury, Brejesh Lall

Auto-TLDR; Under-segmentation of plant image using a graph based formulation to extract leaf shape knowledge for the task of leaf instance segmentation
Abstract Slides Poster Similar
Improving Model Accuracy for Imbalanced Image Classification Tasks by Adding a Final Batch Normalization Layer: An Empirical Study
Veysel Kocaman, Ofer M. Shir, Thomas Baeck

Auto-TLDR; Exploiting Batch Normalization before the Output Layer in Deep Learning for Minority Class Detection in Imbalanced Data Sets
Abstract Slides Poster Similar
PSDNet: A Balanced Architecture of Accuracy and Parameters for Semantic Segmentation

Auto-TLDR; Pyramid Pooling Module with SE1Cblock and D2SUpsample Network (PSDNet)
Abstract Slides Poster Similar
Enhancing Semantic Segmentation of Aerial Images with Inhibitory Neurons
Ihsan Ullah, Sean Reilly, Michael Madden

Auto-TLDR; Lateral Inhibition in Deep Neural Networks for Object Recognition and Semantic Segmentation
Abstract Slides Poster Similar
Classification of Spatially Enriched Pixel Time Series with Convolutional Neural Networks
Mohamed Chelali, Camille Kurtz, Anne Puissant, Nicole Vincent

Auto-TLDR; Spatio-Temporal Features Extraction from Satellite Image Time Series Using Random Walk
Abstract Slides Poster Similar
Crack Detection As a Weakly-Supervised Problem: Towards Achieving Less Annotation-Intensive Crack Detectors

Auto-TLDR; A Weakly-supervised Framework for Automatic Crack Detection
Abstract Slides Poster Similar
DA-RefineNet: Dual-Inputs Attention RefineNet for Whole Slide Image Segmentation
Ziqiang Li, Rentuo Tao, Qianrun Wu, Bin Li

Auto-TLDR; DA-RefineNet: A dual-inputs attention network for whole slide image segmentation
Abstract Slides Poster Similar
Automatically Gather Address Specific Dwelling Images Using Google Street View

Auto-TLDR; Automatic Address Specific Dwelling Image Collection Using Google Street View Data
Abstract Slides Poster Similar
Relevance Detection in Cataract Surgery Videos by Spatio-Temporal Action Localization
Negin Ghamsarian, Mario Taschwer, Doris Putzgruber, Stephanie. Sarny, Klaus Schoeffmann

Auto-TLDR; relevance-based retrieval in cataract surgery videos
A Lumen Segmentation Method in Ureteroscopy Images Based on a Deep Residual U-Net Architecture
Jorge Lazo, Marzullo Aldo, Sara Moccia, Michele Catellani, Benoit Rosa, Elena De Momi, Michel De Mathelin, Francesco Calimeri

Auto-TLDR; A Deep Neural Network for Ureteroscopy with Residual Units
Abstract Slides Poster Similar
Investigating and Exploiting Image Resolution for Transfer Learning-Based Skin Lesion Classification
Amirreza Mahbod, Gerald Schaefer, Chunliang Wang, Rupert Ecker, Georg Dorffner, Isabella Ellinger

Auto-TLDR; Fine-tuned Neural Networks for Skin Lesion Classification Using Dermoscopic Images
Abstract Slides Poster Similar
On the Minimal Recognizable Image Patch
Mark Fonaryov, Michael Lindenbaum

Auto-TLDR; MIRC: A Deep Neural Network for Minimal Recognition on Partially Occluded Images
Abstract Slides Poster Similar
Which are the factors affecting the performance of audio surveillance systems?
Antonio Greco, Antonio Roberto, Alessia Saggese, Mario Vento

Auto-TLDR; Sound Event Recognition Using Convolutional Neural Networks and Visual Representations on MIVIA Audio Events
Comparison of Deep Learning and Hand Crafted Features for Mining Simulation Data
Theodoros Georgiou, Sebastian Schmitt, Thomas Baeck, Nan Pu, Wei Chen, Michael Lew

Auto-TLDR; Automated Data Analysis of Flow Fields in Computational Fluid Dynamics Simulations
Abstract Slides Poster Similar
Transitional Asymmetric Non-Local Neural Networks for Real-World Dirt Road Segmentation

Auto-TLDR; Transitional Asymmetric Non-Local Neural Networks for Semantic Segmentation on Dirt Roads
Abstract Slides Poster Similar
One-Shot Learning for Acoustic Identification of Bird Species in Non-Stationary Environments
Michelangelo Acconcjaioco, Stavros Ntalampiras

Auto-TLDR; One-shot Learning in the Bioacoustics Domain using Siamese Neural Networks
Abstract Slides Poster Similar
Fine-Tuning Convolutional Neural Networks: A Comprehensive Guide and Benchmark Analysis for Glaucoma Screening
Amed Mvoulana, Rostom Kachouri, Mohamed Akil

Auto-TLDR; Fine-tuning Convolutional Neural Networks for Glaucoma Screening
Abstract Slides Poster Similar
Real-Time Monocular Depth Estimation with Extremely Light-Weight Neural Network
Mian Jhong Chiu, Wei-Chen Chiu, Hua-Tsung Chen, Jen-Hui Chuang

Auto-TLDR; Real-Time Light-Weight Depth Prediction for Obstacle Avoidance and Environment Sensing with Deep Learning-based CNN
Abstract Slides Poster Similar
Context-Aware Residual Module for Image Classification

Auto-TLDR; Context-Aware Residual Module for Image Classification
Abstract Slides Poster Similar
Multi-Attribute Learning with Highly Imbalanced Data
Lady Viviana Beltran Beltran, Mickaël Coustaty, Nicholas Journet, Juan C. Caicedo, Antoine Doucet

Auto-TLDR; Data Imbalance in Multi-Attribute Deep Learning Models: Adaptation to face each one of the problems derived from imbalance
Abstract Slides Poster Similar