Exploiting Knowledge Embedded Soft Labels for Image Recognition
Lixian Yuan,
Riquan Chen,
Hefeng Wu,
Tianshui Chen,
Wentao Wang,
Pei Chen

Auto-TLDR; A Soft Label Vector for Image Recognition
Similar papers
Semantic Bilinear Pooling for Fine-Grained Recognition
Xinjie Li, Chun Yang, Song-Lu Chen, Chao Zhu, Xu-Cheng Yin

Auto-TLDR; Semantic bilinear pooling for fine-grained recognition with hierarchical label tree
Abstract Slides Poster Similar
Multi-Order Feature Statistical Model for Fine-Grained Visual Categorization
Qingtao Wang, Ke Zhang, Shaoli Huang, Lianbo Zhang, Jin Fan

Auto-TLDR; Multi-Order Feature Statistical Method for Fine-Grained Visual Categorization
Abstract Slides Poster Similar
Prior Knowledge about Attributes: Learning a More Effective Potential Space for Zero-Shot Recognition

Auto-TLDR; Attribute Correlation Potential Space Generation for Zero-Shot Learning
Abstract Slides Poster Similar
Making Every Label Count: Handling Semantic Imprecision by Integrating Domain Knowledge
Clemens-Alexander Brust, Björn Barz, Joachim Denzler

Auto-TLDR; Class Hierarchies for Imprecise Label Learning and Annotation eXtrapolation
Abstract Slides Poster Similar
More Correlations Better Performance: Fully Associative Networks for Multi-Label Image Classification

Auto-TLDR; Fully Associative Network for Fully Exploiting Correlation Information in Multi-Label Classification
Abstract Slides Poster Similar
Multi-Attribute Learning with Highly Imbalanced Data
Lady Viviana Beltran Beltran, Mickaël Coustaty, Nicholas Journet, Juan C. Caicedo, Antoine Doucet

Auto-TLDR; Data Imbalance in Multi-Attribute Deep Learning Models: Adaptation to face each one of the problems derived from imbalance
Abstract Slides Poster Similar
Multi-Label Contrastive Focal Loss for Pedestrian Attribute Recognition
Xiaoqiang Zheng, Zhenxia Yu, Lin Chen, Fan Zhu, Shilong Wang

Auto-TLDR; Multi-label Contrastive Focal Loss for Pedestrian Attribute Recognition
Abstract Slides Poster Similar
Dual-Attention Guided Dropblock Module for Weakly Supervised Object Localization
Junhui Yin, Siqing Zhang, Dongliang Chang, Zhanyu Ma, Jun Guo

Auto-TLDR; Dual-Attention Guided Dropblock for Weakly Supervised Object Localization
Abstract Slides Poster Similar
A General Model for Learning Node and Graph Representations Jointly

Auto-TLDR; Joint Community Detection/Dynamic Routing for Graph Classification
Abstract Slides Poster Similar
Stochastic Label Refinery: Toward Better Target Label Distribution
Xi Fang, Jiancheng Yang, Bingbing Ni

Auto-TLDR; Stochastic Label Refinery for Deep Supervised Learning
Abstract Slides Poster Similar
Aggregating Object Features Based on Attention Weights for Fine-Grained Image Retrieval
Hongli Lin, Yongqi Song, Zixuan Zeng, Weisheng Wang

Auto-TLDR; DSAW: Unsupervised Dual-selection for Fine-Grained Image Retrieval
Local Attention and Global Representation Collaborating for Fine-Grained Classification
He Zhang, Yunming Bai, Hui Zhang, Jing Liu, Xingguang Li, Zhaofeng He

Auto-TLDR; Weighted Region Network for Cosmetic Contact Lenses Detection
Abstract Slides Poster Similar
Zero-Shot Text Classification with Semantically Extended Graph Convolutional Network
Tengfei Liu, Yongli Hu, Junbin Gao, Yanfeng Sun, Baocai Yin

Auto-TLDR; Semantically Extended Graph Convolutional Network for Zero-shot Text Classification
Abstract Slides Poster Similar
Boundary-Aware Graph Convolution for Semantic Segmentation
Hanzhe Hu, Jinshi Cui, Jinshi Hongbin Zha

Auto-TLDR; Boundary-Aware Graph Convolution for Semantic Segmentation
Abstract Slides Poster Similar
Contextual Classification Using Self-Supervised Auxiliary Models for Deep Neural Networks
Sebastian Palacio, Philipp Engler, Jörn Hees, Andreas Dengel

Auto-TLDR; Self-Supervised Autogenous Learning for Deep Neural Networks
Abstract Slides Poster Similar
Context for Object Detection Via Lightweight Global and Mid-Level Representations
Mesut Erhan Unal, Adriana Kovashka

Auto-TLDR; Context-Based Object Detection with Semantic Similarity
Abstract Slides Poster Similar
Open Set Domain Recognition Via Attention-Based GCN and Semantic Matching Optimization
Xinxing He, Yuan Yuan, Zhiyu Jiang

Auto-TLDR; Attention-based GCN and Semantic Matching Optimization for Open Set Domain Recognition
Abstract Slides Poster Similar
MetaMix: Improved Meta-Learning with Interpolation-based Consistency Regularization
Yangbin Chen, Yun Ma, Tom Ko, Jianping Wang, Qing Li

Auto-TLDR; MetaMix: A Meta-Agnostic Meta-Learning Algorithm for Few-Shot Classification
Abstract Slides Poster Similar
Few-Shot Few-Shot Learning and the Role of Spatial Attention
Yann Lifchitz, Yannis Avrithis, Sylvaine Picard

Auto-TLDR; Few-shot Learning with Pre-trained Classifier on Large-Scale Datasets
Abstract Slides Poster Similar
An Improved Bilinear Pooling Method for Image-Based Action Recognition

Auto-TLDR; An improved bilinear pooling method for image-based action recognition
Abstract Slides Poster Similar
Augmented Bi-Path Network for Few-Shot Learning
Baoming Yan, Chen Zhou, Bo Zhao, Kan Guo, Yang Jiang, Xiaobo Li, Zhang Ming, Yizhou Wang

Auto-TLDR; Augmented Bi-path Network for Few-shot Learning
Abstract Slides Poster Similar
Adaptive Word Embedding Module for Semantic Reasoning in Large-Scale Detection
Yu Zhang, Xiaoyu Wu, Ruolin Zhu

Auto-TLDR; Adaptive Word Embedding Module for Object Detection
Abstract Slides Poster Similar
VSB^2-Net: Visual-Semantic Bi-Branch Network for Zero-Shot Hashing
Xin Li, Xiangfeng Wang, Bo Jin, Wenjie Zhang, Jun Wang, Hongyuan Zha

Auto-TLDR; VSB^2-Net: inductive zero-shot hashing for image retrieval
Abstract Slides Poster Similar
Using Scene Graphs for Detecting Visual Relationships
Anurag Tripathi, Siddharth Srivastava, Brejesh Lall, Santanu Chaudhury

Auto-TLDR; Relationship Detection using Context Aligned Scene Graph Embeddings
Abstract Slides Poster Similar
Generalized Local Attention Pooling for Deep Metric Learning
Carlos Roig Mari, David Varas, Issey Masuda, Juan Carlos Riveiro, Elisenda Bou-Balust

Auto-TLDR; Generalized Local Attention Pooling for Deep Metric Learning
Abstract Slides Poster Similar
Heterogeneous Graph-Based Knowledge Transfer for Generalized Zero-Shot Learning
Junjie Wang, Xiangfeng Wang, Bo Jin, Junchi Yan, Wenjie Zhang, Hongyuan Zha

Auto-TLDR; Heterogeneous Graph-based Knowledge Transfer for Generalized Zero-Shot Learning
Abstract Slides Poster Similar
TreeRNN: Topology-Preserving Deep Graph Embedding and Learning
Yecheng Lyu, Ming Li, Xinming Huang, Ulkuhan Guler, Patrick Schaumont, Ziming Zhang

Auto-TLDR; TreeRNN: Recurrent Neural Network for General Graph Classification
Abstract Slides Poster Similar
Parallel Network to Learn Novelty from the Known
Shuaiyuan Du, Chaoyi Hong, Zhiyu Pan, Chen Feng, Zhiguo Cao
Auto-TLDR; Trainable Parallel Network for Pseudo-Novel Detection
Abstract Slides Poster Similar
Object Detection Using Dual Graph Network
Shengjia Chen, Zhixin Li, Feicheng Huang, Canlong Zhang, Huifang Ma

Auto-TLDR; A Graph Convolutional Network for Object Detection with Key Relation Information
Cc-Loss: Channel Correlation Loss for Image Classification
Zeyu Song, Dongliang Chang, Zhanyu Ma, Li Xiaoxu, Zheng-Hua Tan

Auto-TLDR; Channel correlation loss for ad- dressing image classification
Abstract Slides Poster Similar
Sketch-SNet: Deeper Subdivision of Temporal Cues for Sketch Recognition
Yizhou Tan, Lan Yang, Honggang Zhang

Auto-TLDR; Sketch Recognition using Invariable Structural Feature and Drawing Habits Feature
Abstract Slides Poster Similar
Learning a Dynamic High-Resolution Network for Multi-Scale Pedestrian Detection
Mengyuan Ding, Shanshan Zhang, Jian Yang

Auto-TLDR; Learningable Dynamic HRNet for Pedestrian Detection
Abstract Slides Poster Similar
Semantics to Space(S2S): Embedding Semantics into Spatial Space for Zero-Shot Verb-Object Query Inferencing

Auto-TLDR; Semantics-to-Space: Deep Zero-Shot Learning for Verb-Object Interaction with Vectors
Abstract Slides Poster Similar
Building Computationally Efficient and Well-Generalizing Person Re-Identification Models with Metric Learning
Vladislav Sovrasov, Dmitry Sidnev

Auto-TLDR; Cross-Domain Generalization in Person Re-identification using Omni-Scale Network
Complementing Representation Deficiency in Few-Shot Image Classification: A Meta-Learning Approach
Xian Zhong, Cheng Gu, Wenxin Huang, Lin Li, Shuqin Chen, Chia-Wen Lin

Auto-TLDR; Meta-learning with Complementary Representations Network for Few-Shot Learning
Abstract Slides Poster Similar
RGB-Infrared Person Re-Identification Via Image Modality Conversion
Huangpeng Dai, Qing Xie, Yanchun Ma, Yongjian Liu, Shengwu Xiong

Auto-TLDR; CE2L: A Novel Network for Cross-Modality Re-identification with Feature Alignment
Abstract Slides Poster Similar
Global-Local Attention Network for Semantic Segmentation in Aerial Images
Minglong Li, Lianlei Shan, Weiqiang Wang

Auto-TLDR; GLANet: Global-Local Attention Network for Semantic Segmentation
Abstract Slides Poster Similar
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
FashionGraph: Understanding Fashion Data Using Scene Graph Generation
Shabnam Sadegharmaki, Marc A. Kastner, Shin'Ichi Satoh
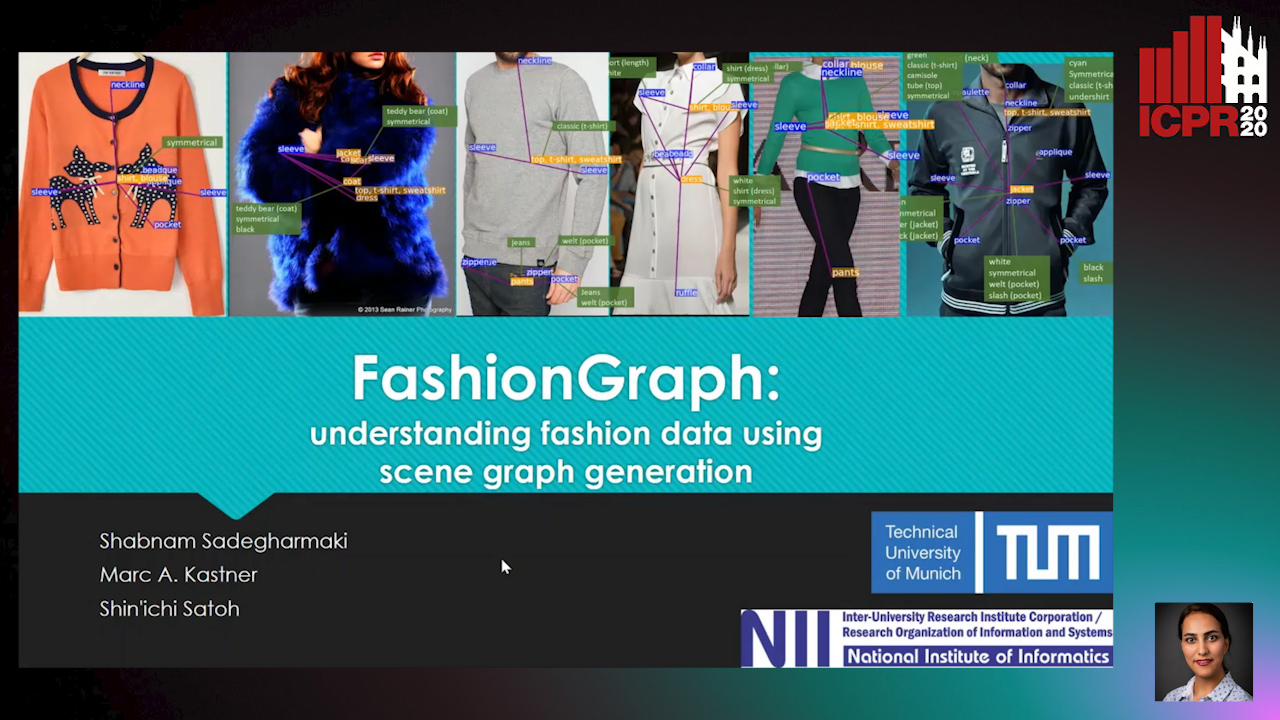
Auto-TLDR; Exploiting Scene Graph Knowledge for Fashion Applications
Attentive Hybrid Feature Based a Two-Step Fusion for Facial Expression Recognition
Jun Weng, Yang Yang, Zichang Tan, Zhen Lei

Auto-TLDR; Attentive Hybrid Architecture for Facial Expression Recognition
Abstract Slides Poster Similar
Edge-Aware Graph Attention Network for Ratio of Edge-User Estimation in Mobile Networks
Jiehui Deng, Sheng Wan, Xiang Wang, Enmei Tu, Xiaolin Huang, Jie Yang, Chen Gong

Auto-TLDR; EAGAT: Edge-Aware Graph Attention Network for Automatic REU Estimation in Mobile Networks
Abstract Slides Poster Similar
Rethinking of Deep Models Parameters with Respect to Data Distribution
Shitala Prasad, Dongyun Lin, Yiqun Li, Sheng Dong, Zaw Min Oo

Auto-TLDR; A progressive stepwise training strategy for deep neural networks
Abstract Slides Poster Similar
A CNN-RNN Framework for Image Annotation from Visual Cues and Social Network Metadata
Tobia Tesan, Pasquale Coscia, Lamberto Ballan

Auto-TLDR; Context-Based Image Annotation with Multiple Semantic Embeddings and Recurrent Neural Networks
Abstract Slides Poster Similar
Multi-Scale Cascading Network with Compact Feature Learning for RGB-Infrared Person Re-Identification
Can Zhang, Hong Liu, Wei Guo, Mang Ye

Auto-TLDR; Multi-Scale Part-Aware Cascading for RGB-Infrared Person Re-identification
Abstract Slides Poster Similar
Convolutional STN for Weakly Supervised Object Localization
Akhil Meethal, Marco Pedersoli, Soufiane Belharbi, Eric Granger

Auto-TLDR; Spatial Localization for Weakly Supervised Object Localization
Quasibinary Classifier for Images with Zero and Multiple Labels
Liao Shuai, Efstratios Gavves, Changyong Oh, Cees Snoek

Auto-TLDR; Quasibinary Classifiers for Zero-label and Multi-label Classification
Abstract Slides Poster Similar
Recognizing Bengali Word Images - A Zero-Shot Learning Perspective
Sukalpa Chanda, Daniël Arjen Willem Haitink, Prashant Kumar Prasad, Jochem Baas, Umapada Pal, Lambert Schomaker

Auto-TLDR; Zero-Shot Learning for Word Recognition in Bengali Script
Abstract Slides Poster Similar
Learning from Web Data: Improving Crowd Counting Via Semi-Supervised Learning

Auto-TLDR; Semi-supervised Crowd Counting Baseline for Deep Neural Networks
Abstract Slides Poster Similar