Human-Centric Parsing Network for Human-Object Interaction Detection
Guanyu Chen,
Chong Chen,
Zhicheng Zhao,
Fei Su

Auto-TLDR; Human-Centric Parsing Network for Human-Object Interactions Detection
Similar papers
Exploring and Exploiting the Hierarchical Structure of a Scene for Scene Graph Generation
Ikuto Kurosawa, Tetsunori Kobayashi, Yoshihiko Hayashi

Auto-TLDR; A Hierarchical Model for Scene Graph Generation
Abstract Slides Poster Similar
Self-Selective Context for Interaction Recognition
Kilickaya Kilickaya, Noureldien Hussein, Efstratios Gavves, Arnold Smeulders

Auto-TLDR; Self-Selective Context for Human-Object Interaction Recognition
Abstract Slides Poster Similar
Using Scene Graphs for Detecting Visual Relationships
Anurag Tripathi, Siddharth Srivastava, Brejesh Lall, Santanu Chaudhury

Auto-TLDR; Relationship Detection using Context Aligned Scene Graph Embeddings
Abstract Slides Poster Similar
Context for Object Detection Via Lightweight Global and Mid-Level Representations
Mesut Erhan Unal, Adriana Kovashka

Auto-TLDR; Context-Based Object Detection with Semantic Similarity
Abstract Slides Poster Similar
Privacy Attributes-Aware Message Passing Neural Network for Visual Privacy Attributes Classification
Hanbin Hong, Wentao Bao, Yuan Hong, Yu Kong

Auto-TLDR; Privacy Attributes-Aware Message Passing Neural Network for Visual Privacy Attribute Classification
Abstract Slides Poster Similar
StrongPose: Bottom-up and Strong Keypoint Heat Map Based Pose Estimation

Auto-TLDR; StrongPose: A bottom-up box-free approach for human pose estimation and action recognition
Abstract Slides Poster Similar
Activity and Relationship Modeling Driven Weakly Supervised Object Detection
Yinlin Li, Yang Qian, Xu Yang, Yuren Zhang
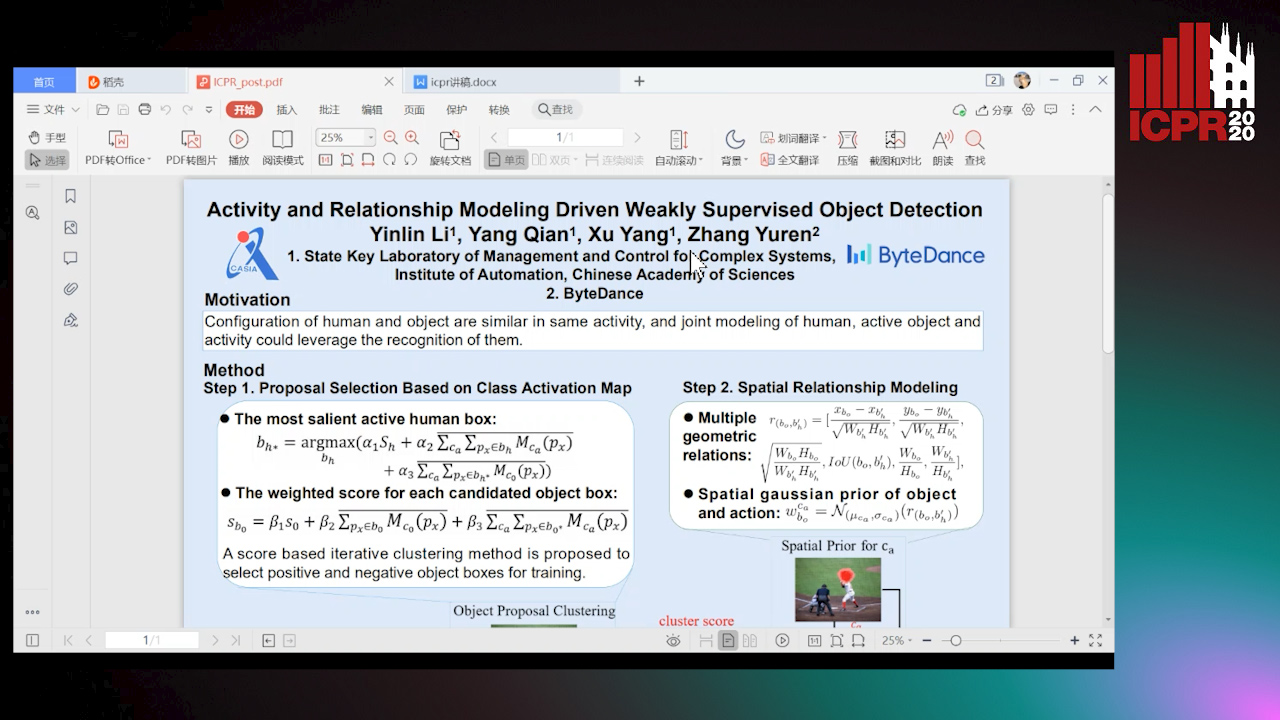
Auto-TLDR; Weakly Supervised Object Detection Using Activity Label and Relationship Modeling
Abstract Slides Poster Similar
P2 Net: Augmented Parallel-Pyramid Net for Attention Guided Pose Estimation
Luanxuan Hou, Jie Cao, Yuan Zhao, Haifeng Shen, Jian Tang, Ran He

Auto-TLDR; Parallel-Pyramid Net with Partial Attention for Human Pose Estimation
Abstract Slides Poster Similar
Adaptive Word Embedding Module for Semantic Reasoning in Large-Scale Detection
Yu Zhang, Xiaoyu Wu, Ruolin Zhu

Auto-TLDR; Adaptive Word Embedding Module for Object Detection
Abstract Slides Poster Similar
Boundary-Aware Graph Convolution for Semantic Segmentation
Hanzhe Hu, Jinshi Cui, Jinshi Hongbin Zha

Auto-TLDR; Boundary-Aware Graph Convolution for Semantic Segmentation
Abstract Slides Poster Similar
An Improved Bilinear Pooling Method for Image-Based Action Recognition

Auto-TLDR; An improved bilinear pooling method for image-based action recognition
Abstract Slides Poster Similar
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
Object Detection Using Dual Graph Network
Shengjia Chen, Zhixin Li, Feicheng Huang, Canlong Zhang, Huifang Ma

Auto-TLDR; A Graph Convolutional Network for Object Detection with Key Relation Information
Context Aware Group Activity Recognition
Avijit Dasgupta, C. V. Jawahar, Karteek Alahari

Auto-TLDR; A Two-Stream Architecture for Group Activity Recognition in Multi-Person Videos
Abstract Slides Poster Similar
What Nodes Vote To? Graph Classification without Readout Phase
Yuxing Tian, Zheng Liu, Weiding Liu, Zeyu Zhang, Yanwen Qu

Auto-TLDR; node voting based graph classification with convolutional operator
Abstract Slides Poster Similar
Efficient-Receptive Field Block with Group Spatial Attention Mechanism for Object Detection
Jiacheng Zhang, Zhicheng Zhao, Fei Su

Auto-TLDR; E-RFB: Efficient-Receptive Field Block for Deep Neural Network for Object Detection
Abstract Slides Poster Similar
Small Object Detection by Generative and Discriminative Learning
Yi Gu, Jie Li, Chentao Wu, Weijia Jia, Jianping Chen

Auto-TLDR; Generative and Discriminative Learning for Small Object Detection
Abstract Slides Poster Similar
Simple Multi-Resolution Representation Learning for Human Pose Estimation
Trung Tran Quang, Van Giang Nguyen, Daeyoung Kim

Auto-TLDR; Multi-resolution Heatmap Learning for Human Pose Estimation
Abstract Slides Poster Similar
A Novel Region of Interest Extraction Layer for Instance Segmentation
Leonardo Rossi, Akbar Karimi, Andrea Prati

Auto-TLDR; Generic RoI Extractor for Two-Stage Neural Network for Instance Segmentation
Abstract Slides Poster Similar
MFI: Multi-Range Feature Interchange for Video Action Recognition
Sikai Bai, Qi Wang, Xuelong Li

Auto-TLDR; Multi-range Feature Interchange Network for Action Recognition in Videos
Abstract Slides Poster Similar
Bidirectional Matrix Feature Pyramid Network for Object Detection

Auto-TLDR; BMFPN: Bidirectional Matrix Feature Pyramid Network for Object Detection
Abstract Slides Poster Similar
More Correlations Better Performance: Fully Associative Networks for Multi-Label Image Classification

Auto-TLDR; Fully Associative Network for Fully Exploiting Correlation Information in Multi-Label Classification
Abstract Slides Poster Similar
SyNet: An Ensemble Network for Object Detection in UAV Images

Auto-TLDR; SyNet: Combining Multi-Stage and Single-Stage Object Detection for Aerial Images
Dual-Attention Guided Dropblock Module for Weakly Supervised Object Localization
Junhui Yin, Siqing Zhang, Dongliang Chang, Zhanyu Ma, Jun Guo

Auto-TLDR; Dual-Attention Guided Dropblock for Weakly Supervised Object Localization
Abstract Slides Poster Similar
Improving Visual Relation Detection Using Depth Maps
Sahand Sharifzadeh, Sina Moayed Baharlou, Max Berrendorf, Rajat Koner, Volker Tresp

Auto-TLDR; Exploiting Depth Maps for Visual Relation Detection
Abstract Slides Poster Similar
Detecting Objects with High Object Region Percentage
Fen Fang, Qianli Xu, Liyuan Li, Ying Gu, Joo-Hwee Lim

Auto-TLDR; Faster R-CNN for High-ORP Object Detection
Abstract Slides Poster Similar
Forground-Guided Vehicle Perception Framework
Kun Tian, Tong Zhou, Shiming Xiang, Chunhong Pan

Auto-TLDR; A foreground segmentation branch for vehicle detection
Abstract Slides Poster Similar
Detective: An Attentive Recurrent Model for Sparse Object Detection
Amine Kechaou, Manuel Martinez, Monica Haurilet, Rainer Stiefelhagen

Auto-TLDR; Detective: An attentive object detector that identifies objects in images in a sequential manner
Abstract Slides Poster Similar
Question-Agnostic Attention for Visual Question Answering
Moshiur R Farazi, Salman Hameed Khan, Nick Barnes

Auto-TLDR; Question-Agnostic Attention for Visual Question Answering
Abstract Slides Poster Similar
Cross-View Relation Networks for Mammogram Mass Detection
Ma Jiechao, Xiang Li, Hongwei Li, Ruixuan Wang, Bjoern Menze, Wei-Shi Zheng

Auto-TLDR; Multi-view Modeling for Mass Detection in Mammogram
Abstract Slides Poster Similar
Modeling Long-Term Interactions to Enhance Action Recognition
Alejandro Cartas, Petia Radeva, Mariella Dimiccoli

Auto-TLDR; A Hierarchical Long Short-Term Memory Network for Action Recognition in Egocentric Videos
Abstract Slides Poster Similar
SFPN: Semantic Feature Pyramid Network for Object Detection

Auto-TLDR; SFPN: Semantic Feature Pyramid Network to Address Information Dilution Issue in FPN
Abstract Slides Poster Similar
Flow-Guided Spatial Attention Tracking for Egocentric Activity Recognition

Auto-TLDR; flow-guided spatial attention tracking for egocentric activity recognition
Abstract Slides Poster Similar
ACRM: Attention Cascade R-CNN with Mix-NMS for Metallic Surface Defect Detection
Junting Fang, Xiaoyang Tan, Yuhui Wang

Auto-TLDR; Attention Cascade R-CNN with Mix Non-Maximum Suppression for Robust Metal Defect Detection
Abstract Slides Poster Similar
Image Inpainting with Contrastive Relation Network
Xiaoqiang Zhou, Junjie Li, Zilei Wang, Ran He, Tieniu Tan

Auto-TLDR; Two-Stage Inpainting with Graph-based Relation Network
Multi-Modal Contextual Graph Neural Network for Text Visual Question Answering
Yaoyuan Liang, Xin Wang, Xuguang Duan, Wenwu Zhu

Auto-TLDR; Multi-modal Contextual Graph Neural Network for Text Visual Question Answering
Abstract Slides Poster Similar
Semantics to Space(S2S): Embedding Semantics into Spatial Space for Zero-Shot Verb-Object Query Inferencing

Auto-TLDR; Semantics-to-Space: Deep Zero-Shot Learning for Verb-Object Interaction with Vectors
Abstract Slides Poster Similar
Cascade Saliency Attention Network for Object Detection in Remote Sensing Images
Dayang Yu, Rong Zhang, Shan Qin

Auto-TLDR; Cascade Saliency Attention Network for Object Detection in Remote Sensing Images
Abstract Slides Poster Similar
Learning a Dynamic High-Resolution Network for Multi-Scale Pedestrian Detection
Mengyuan Ding, Shanshan Zhang, Jian Yang

Auto-TLDR; Learningable Dynamic HRNet for Pedestrian Detection
Abstract Slides Poster Similar
Global-Local Attention Network for Semantic Segmentation in Aerial Images
Minglong Li, Lianlei Shan, Weiqiang Wang

Auto-TLDR; GLANet: Global-Local Attention Network for Semantic Segmentation
Abstract Slides Poster Similar
CenterRepp: Predict Central Representative Point Set's Distribution for Detection
Yulin He, Limeng Zhang, Wei Chen, Xin Luo, Chen Li, Xiaogang Jia

Auto-TLDR; CRPDet: CenterRepp Detector for Object Detection
Abstract Slides Poster Similar
Temporal Attention-Augmented Graph Convolutional Network for Efficient Skeleton-Based Human Action Recognition
Negar Heidari, Alexandros Iosifidis

Auto-TLDR; Temporal Attention Module for Efficient Graph Convolutional Network-based Action Recognition
Abstract Slides Poster Similar
Self and Channel Attention Network for Person Re-Identification
Asad Munir, Niki Martinel, Christian Micheloni

Auto-TLDR; SCAN: Self and Channel Attention Network for Person Re-identification
Abstract Slides Poster Similar
Zero-Shot Text Classification with Semantically Extended Graph Convolutional Network
Tengfei Liu, Yongli Hu, Junbin Gao, Yanfeng Sun, Baocai Yin

Auto-TLDR; Semantically Extended Graph Convolutional Network for Zero-shot Text Classification
Abstract Slides Poster Similar
A Two-Stream Recurrent Network for Skeleton-Based Human Interaction Recognition
Qianhui Men, Edmond S. L. Ho, Shum Hubert P. H., Howard Leung

Auto-TLDR; Two-Stream Recurrent Neural Network for Human-Human Interaction Recognition
Abstract Slides Poster Similar
Region and Relations Based Multi Attention Network for Graph Classification
Manasvi Aggarwal, M. Narasimha Murty

Auto-TLDR; R2POOL: A Graph Pooling Layer for Non-euclidean Structures
Abstract Slides Poster Similar
MANet: Multimodal Attention Network Based Point-View Fusion for 3D Shape Recognition
Yaxin Zhao, Jichao Jiao, Ning Li

Auto-TLDR; Fusion Network for 3D Shape Recognition based on Multimodal Attention Mechanism
Abstract Slides Poster Similar
Weakly Supervised Body Part Segmentation with Pose Based Part Priors
Zhengyuan Yang, Yuncheng Li, Linjie Yang, Ning Zhang, Jiebo Luo

Auto-TLDR; Weakly Supervised Body Part Segmentation Using Weak Labels