Self-Selective Context for Interaction Recognition
Kilickaya Kilickaya,
Noureldien Hussein,
Efstratios Gavves,
Arnold Smeulders

Auto-TLDR; Self-Selective Context for Human-Object Interaction Recognition
Similar papers
Human-Centric Parsing Network for Human-Object Interaction Detection
Guanyu Chen, Chong Chen, Zhicheng Zhao, Fei Su

Auto-TLDR; Human-Centric Parsing Network for Human-Object Interactions Detection
Abstract Slides Poster Similar
Context Aware Group Activity Recognition
Avijit Dasgupta, C. V. Jawahar, Karteek Alahari

Auto-TLDR; A Two-Stream Architecture for Group Activity Recognition in Multi-Person Videos
Abstract Slides Poster Similar
Activity and Relationship Modeling Driven Weakly Supervised Object Detection
Yinlin Li, Yang Qian, Xu Yang, Yuren Zhang
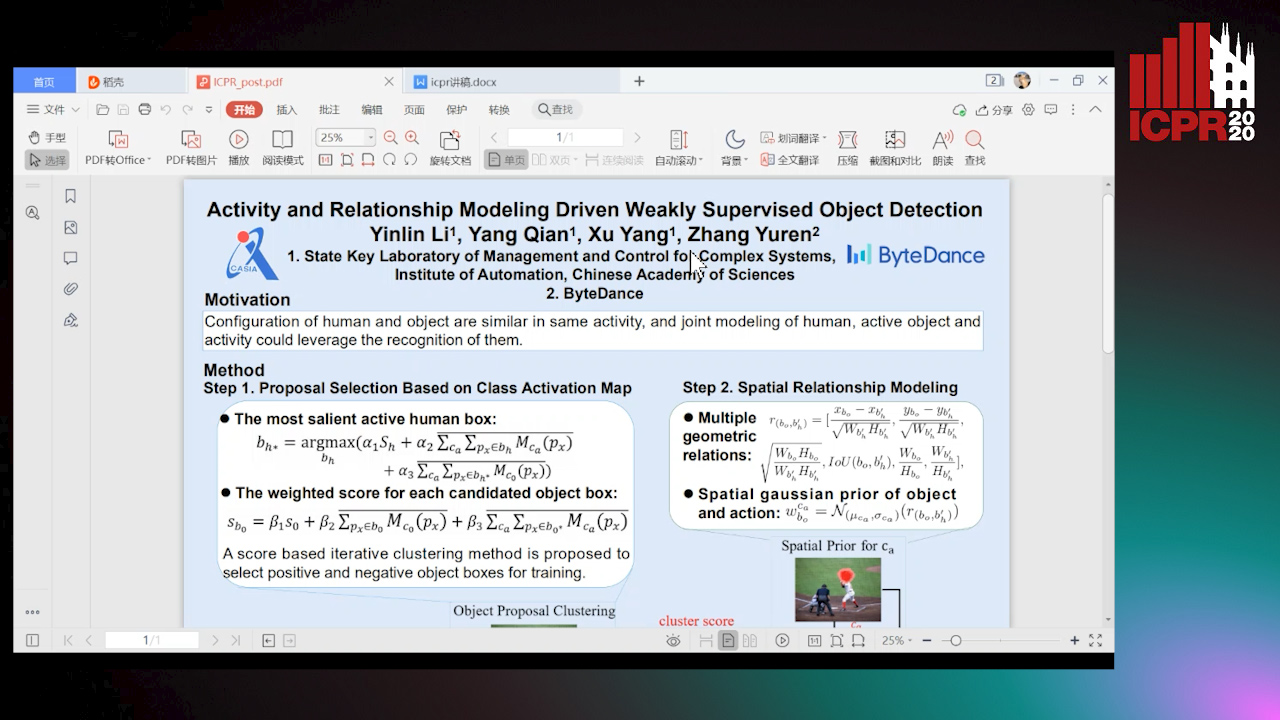
Auto-TLDR; Weakly Supervised Object Detection Using Activity Label and Relationship Modeling
Abstract Slides Poster Similar
An Improved Bilinear Pooling Method for Image-Based Action Recognition

Auto-TLDR; An improved bilinear pooling method for image-based action recognition
Abstract Slides Poster Similar
Semantics to Space(S2S): Embedding Semantics into Spatial Space for Zero-Shot Verb-Object Query Inferencing

Auto-TLDR; Semantics-to-Space: Deep Zero-Shot Learning for Verb-Object Interaction with Vectors
Abstract Slides Poster Similar
Modeling Long-Term Interactions to Enhance Action Recognition
Alejandro Cartas, Petia Radeva, Mariella Dimiccoli

Auto-TLDR; A Hierarchical Long Short-Term Memory Network for Action Recognition in Egocentric Videos
Abstract Slides Poster Similar
Using Scene Graphs for Detecting Visual Relationships
Anurag Tripathi, Siddharth Srivastava, Brejesh Lall, Santanu Chaudhury

Auto-TLDR; Relationship Detection using Context Aligned Scene Graph Embeddings
Abstract Slides Poster Similar
Question-Agnostic Attention for Visual Question Answering
Moshiur R Farazi, Salman Hameed Khan, Nick Barnes

Auto-TLDR; Question-Agnostic Attention for Visual Question Answering
Abstract Slides Poster Similar
Context for Object Detection Via Lightweight Global and Mid-Level Representations
Mesut Erhan Unal, Adriana Kovashka

Auto-TLDR; Context-Based Object Detection with Semantic Similarity
Abstract Slides Poster Similar
Developing Motion Code Embedding for Action Recognition in Videos
Maxat Alibayev, David Andrea Paulius, Yu Sun

Auto-TLDR; Motion Embedding via Motion Codes for Action Recognition
Abstract Slides Poster Similar
A Novel Attention-Based Aggregation Function to Combine Vision and Language
Matteo Stefanini, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara

Auto-TLDR; Fully-Attentive Reduction for Vision and Language
Abstract Slides Poster Similar
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
StrongPose: Bottom-up and Strong Keypoint Heat Map Based Pose Estimation

Auto-TLDR; StrongPose: A bottom-up box-free approach for human pose estimation and action recognition
Abstract Slides Poster Similar
Attention Pyramid Module for Scene Recognition
Zhinan Qiao, Xiaohui Yuan, Chengyuan Zhuang, Abolfazl Meyarian

Auto-TLDR; Attention Pyramid Module for Multi-Scale Scene Recognition
Abstract Slides Poster Similar
Adaptive Word Embedding Module for Semantic Reasoning in Large-Scale Detection
Yu Zhang, Xiaoyu Wu, Ruolin Zhu

Auto-TLDR; Adaptive Word Embedding Module for Object Detection
Abstract Slides Poster Similar
Detective: An Attentive Recurrent Model for Sparse Object Detection
Amine Kechaou, Manuel Martinez, Monica Haurilet, Rainer Stiefelhagen

Auto-TLDR; Detective: An attentive object detector that identifies objects in images in a sequential manner
Abstract Slides Poster Similar
Detecting Objects with High Object Region Percentage
Fen Fang, Qianli Xu, Liyuan Li, Ying Gu, Joo-Hwee Lim

Auto-TLDR; Faster R-CNN for High-ORP Object Detection
Abstract Slides Poster Similar
VTT: Long-Term Visual Tracking with Transformers
Tianling Bian, Yang Hua, Tao Song, Zhengui Xue, Ruhui Ma, Neil Robertson, Haibing Guan

Auto-TLDR; Visual Tracking Transformer with transformers for long-term visual tracking
Multi-Modal Contextual Graph Neural Network for Text Visual Question Answering
Yaoyuan Liang, Xin Wang, Xuguang Duan, Wenwu Zhu

Auto-TLDR; Multi-modal Contextual Graph Neural Network for Text Visual Question Answering
Abstract Slides Poster Similar
A Novel Region of Interest Extraction Layer for Instance Segmentation
Leonardo Rossi, Akbar Karimi, Andrea Prati

Auto-TLDR; Generic RoI Extractor for Two-Stage Neural Network for Instance Segmentation
Abstract Slides Poster Similar
A Detection-Based Approach to Multiview Action Classification in Infants
Carolina Pacheco, Effrosyni Mavroudi, Elena Kokkoni, Herbert Tanner, Rene Vidal

Auto-TLDR; Multiview Action Classification for Infants in a Pediatric Rehabilitation Environment
Attention-Oriented Action Recognition for Real-Time Human-Robot Interaction
Ziyang Song, Ziyi Yin, Zejian Yuan, Chong Zhang, Wanchao Chi, Yonggen Ling, Shenghao Zhang

Auto-TLDR; Attention-Oriented Multi-Level Network for Action Recognition in Interaction Scenes
Abstract Slides Poster Similar
A Two-Stream Recurrent Network for Skeleton-Based Human Interaction Recognition
Qianhui Men, Edmond S. L. Ho, Shum Hubert P. H., Howard Leung

Auto-TLDR; Two-Stream Recurrent Neural Network for Human-Human Interaction Recognition
Abstract Slides Poster Similar
MAGNet: Multi-Region Attention-Assisted Grounding of Natural Language Queries at Phrase Level
Amar Shrestha, Krittaphat Pugdeethosapol, Haowen Fang, Qinru Qiu

Auto-TLDR; MAGNet: A Multi-Region Attention-Aware Grounding Network for Free-form Textual Queries
Abstract Slides Poster Similar
Motion-Supervised Co-Part Segmentation
Aliaksandr Siarohin, Subhankar Roy, Stéphane Lathuiliere, Sergey Tulyakov, Elisa Ricci, Nicu Sebe

Auto-TLDR; Self-supervised Co-Part Segmentation Using Motion Information from Videos
Dual-Attention Guided Dropblock Module for Weakly Supervised Object Localization
Junhui Yin, Siqing Zhang, Dongliang Chang, Zhanyu Ma, Jun Guo

Auto-TLDR; Dual-Attention Guided Dropblock for Weakly Supervised Object Localization
Abstract Slides Poster Similar
Improving Visual Relation Detection Using Depth Maps
Sahand Sharifzadeh, Sina Moayed Baharlou, Max Berrendorf, Rajat Koner, Volker Tresp

Auto-TLDR; Exploiting Depth Maps for Visual Relation Detection
Abstract Slides Poster Similar
HPERL: 3D Human Pose Estimastion from RGB and LiDAR
Michael Fürst, Shriya T.P. Gupta, René Schuster, Oliver Wasenmüler, Didier Stricker

Auto-TLDR; 3D Human Pose Estimation Using RGB and LiDAR Using Weakly-Supervised Approach
Abstract Slides Poster Similar
Self-Supervised Joint Encoding of Motion and Appearance for First Person Action Recognition
Mirco Planamente, Andrea Bottino, Barbara Caputo

Auto-TLDR; A Single Stream Architecture for Egocentric Action Recognition from the First-Person Point of View
Abstract Slides Poster Similar
ACRM: Attention Cascade R-CNN with Mix-NMS for Metallic Surface Defect Detection
Junting Fang, Xiaoyang Tan, Yuhui Wang

Auto-TLDR; Attention Cascade R-CNN with Mix Non-Maximum Suppression for Robust Metal Defect Detection
Abstract Slides Poster Similar
Attention-Driven Body Pose Encoding for Human Activity Recognition
Bappaditya Debnath, Swagat Kumar, Marry O'Brien, Ardhendu Behera

Auto-TLDR; Attention-based Body Pose Encoding for Human Activity Recognition
Abstract Slides Poster Similar
Convolutional STN for Weakly Supervised Object Localization
Akhil Meethal, Marco Pedersoli, Soufiane Belharbi, Eric Granger

Auto-TLDR; Spatial Localization for Weakly Supervised Object Localization
Weakly Supervised Body Part Segmentation with Pose Based Part Priors
Zhengyuan Yang, Yuncheng Li, Linjie Yang, Ning Zhang, Jiebo Luo

Auto-TLDR; Weakly Supervised Body Part Segmentation Using Weak Labels
Late Fusion of Bayesian and Convolutional Models for Action Recognition
Camille Maurice, Francisco Madrigal, Frederic Lerasle

Auto-TLDR; Fusion of Deep Neural Network and Bayesian-based Approach for Temporal Action Recognition
Abstract Slides Poster Similar
Extracting Action Hierarchies from Action Labels and their Use in Deep Action Recognition
Konstadinos Bacharidis, Antonis Argyros

Auto-TLDR; Exploiting the Information Content of Language Label Associations for Human Action Recognition
Abstract Slides Poster Similar
Inferring Tasks and Fluents in Videos by Learning Causal Relations
Haowen Tang, Ping Wei, Huan Li, Nanning Zheng

Auto-TLDR; Joint Learning of Complex Task and Fluent States in Videos
Abstract Slides Poster Similar
Learnable Higher-Order Representation for Action Recognition

Auto-TLDR; Learningable Higher-Order Operations for Spatiotemporal Dynamics in Video Recognition
Object Detection Using Dual Graph Network
Shengjia Chen, Zhixin Li, Feicheng Huang, Canlong Zhang, Huifang Ma

Auto-TLDR; A Graph Convolutional Network for Object Detection with Key Relation Information
Efficient-Receptive Field Block with Group Spatial Attention Mechanism for Object Detection
Jiacheng Zhang, Zhicheng Zhao, Fei Su

Auto-TLDR; E-RFB: Efficient-Receptive Field Block for Deep Neural Network for Object Detection
Abstract Slides Poster Similar
Multi-Stage Attention Based Visual Question Answering
Aakansha Mishra, Ashish Anand, Prithwijit Guha

Auto-TLDR; Alternative Bi-directional Attention for Visual Question Answering
Exploring and Exploiting the Hierarchical Structure of a Scene for Scene Graph Generation
Ikuto Kurosawa, Tetsunori Kobayashi, Yoshihiko Hayashi

Auto-TLDR; A Hierarchical Model for Scene Graph Generation
Abstract Slides Poster Similar
Object Detection on Monocular Images with Two-Dimensional Canonical Correlation Analysis

Auto-TLDR; Multi-Task Object Detection from Monocular Images Using Multimodal RGB and Depth Data
Abstract Slides Poster Similar
More Correlations Better Performance: Fully Associative Networks for Multi-Label Image Classification

Auto-TLDR; Fully Associative Network for Fully Exploiting Correlation Information in Multi-Label Classification
Abstract Slides Poster Similar
End-To-End Hierarchical Relation Extraction for Generic Form Understanding
Tuan Anh Nguyen Dang, Duc-Thanh Hoang, Quang Bach Tran, Chih-Wei Pan, Thanh-Dat Nguyen

Auto-TLDR; Joint Entity Labeling and Link Prediction for Form Understanding in Noisy Scanned Documents
Abstract Slides Poster Similar
Aggregating Object Features Based on Attention Weights for Fine-Grained Image Retrieval
Hongli Lin, Yongqi Song, Zixuan Zeng, Weisheng Wang

Auto-TLDR; DSAW: Unsupervised Dual-selection for Fine-Grained Image Retrieval
Transformer-Encoder Detector Module: Using Context to Improve Robustness to Adversarial Attacks on Object Detection
Faisal Alamri, Sinan Kalkan, Nicolas Pugeault

Auto-TLDR; Context Module for Robust Object Detection with Transformer-Encoder Detector Module
Abstract Slides Poster Similar
Flow-Guided Spatial Attention Tracking for Egocentric Activity Recognition

Auto-TLDR; flow-guided spatial attention tracking for egocentric activity recognition
Abstract Slides Poster Similar
Explore and Explain: Self-Supervised Navigation and Recounting
Roberto Bigazzi, Federico Landi, Marcella Cornia, Silvia Cascianelli, Lorenzo Baraldi, Rita Cucchiara

Auto-TLDR; Exploring a Photorealistic Environment for Explanation and Navigation