Multi-Scale 2D Representation Learning for Weakly-Supervised Moment Retrieval
Ding Li,
Rui Wu,
Zhizhong Zhang,
Yongqiang Tang,
Wensheng Zhang

Auto-TLDR; Multi-scale 2D Representation Learning for Weakly Supervised Video Moment Retrieval
Similar papers
Context Visual Information-Based Deliberation Network for Video Captioning
Min Lu, Xueyong Li, Caihua Liu

Auto-TLDR; Context visual information-based deliberation network for video captioning
Abstract Slides Poster Similar
Attentive Visual Semantic Specialized Network for Video Captioning
Jesus Perez-Martin, Benjamin Bustos, Jorge Pérez

Auto-TLDR; Adaptive Visual Semantic Specialized Network for Video Captioning
Abstract Slides Poster Similar
Text Synopsis Generation for Egocentric Videos
Aidean Sharghi, Niels Lobo, Mubarak Shah

Auto-TLDR; Egocentric Video Summarization Using Multi-task Learning for End-to-End Learning
Visual Oriented Encoder: Integrating Multimodal and Multi-Scale Contexts for Video Captioning

Auto-TLDR; Visual Oriented Encoder for Video Captioning
Abstract Slides Poster Similar
You Ought to Look Around: Precise, Large Span Action Detection
Ge Pan, Zhang Han, Fan Yu, Yonghong Song, Yuanlin Zhang, Han Yuan

Auto-TLDR; YOLA: Local Feature Extraction for Action Localization with Variable receptive field
Feature Pyramid Hierarchies for Multi-Scale Temporal Action Detection

Auto-TLDR; Temporal Action Detection using Pyramid Hierarchies and Multi-scale Feature Maps
Abstract Slides Poster Similar
Enriching Video Captions with Contextual Text
Philipp Rimle, Pelin Dogan, Markus Gross

Auto-TLDR; Contextualized Video Captioning Using Contextual Text
Abstract Slides Poster Similar
MAGNet: Multi-Region Attention-Assisted Grounding of Natural Language Queries at Phrase Level
Amar Shrestha, Krittaphat Pugdeethosapol, Haowen Fang, Qinru Qiu

Auto-TLDR; MAGNet: A Multi-Region Attention-Aware Grounding Network for Free-form Textual Queries
Abstract Slides Poster Similar
Gabriella: An Online System for Real-Time Activity Detection in Untrimmed Security Videos
Mamshad Nayeem Rizve, Ugur Demir, Praveen Praveen Tirupattur, Aayush Jung Rana, Kevin Duarte, Ishan Rajendrakumar Dave, Yogesh Rawat, Mubarak Shah

Auto-TLDR; Gabriella: A Real-Time Online System for Activity Detection in Surveillance Videos
VSR++: Improving Visual Semantic Reasoning for Fine-Grained Image-Text Matching
Hui Yuan, Yan Huang, Dongbo Zhang, Zerui Chen, Wenlong Cheng, Liang Wang

Auto-TLDR; Improving Visual Semantic Reasoning for Fine-Grained Image-Text Matching
Abstract Slides Poster Similar
A Novel Attention-Based Aggregation Function to Combine Vision and Language
Matteo Stefanini, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara

Auto-TLDR; Fully-Attentive Reduction for Vision and Language
Abstract Slides Poster Similar
TinyVIRAT: Low-Resolution Video Action Recognition
Ugur Demir, Yogesh Rawat, Mubarak Shah

Auto-TLDR; TinyVIRAT: A Progressive Generative Approach for Action Recognition in Videos
Abstract Slides Poster Similar
ActionSpotter: Deep Reinforcement Learning Framework for Temporal Action Spotting in Videos
Guillaume Vaudaux-Ruth, Adrien Chan-Hon-Tong, Catherine Achard

Auto-TLDR; ActionSpotter: A Reinforcement Learning Algorithm for Action Spotting in Video
Abstract Slides Poster Similar
MFI: Multi-Range Feature Interchange for Video Action Recognition
Sikai Bai, Qi Wang, Xuelong Li

Auto-TLDR; Multi-range Feature Interchange Network for Action Recognition in Videos
Abstract Slides Poster Similar
A Novel Actor Dual-Critic Model for Remote Sensing Image Captioning
Ruchika Chavhan, Biplab Banerjee, Xiao Xiang Zhu, Subhasis Chaudhuri

Auto-TLDR; Actor Dual-Critic Training for Remote Sensing Image Captioning Using Deep Reinforcement Learning
Abstract Slides Poster Similar
Unsupervised Co-Segmentation for Athlete Movements and Live Commentaries Using Crossmodal Temporal Proximity
Yasunori Ohishi, Yuki Tanaka, Kunio Kashino

Auto-TLDR; A guided attention scheme for audio-visual co-segmentation
Abstract Slides Poster Similar
Dual Path Multi-Modal High-Order Features for Textual Content Based Visual Question Answering
Yanan Li, Yuetan Lin, Hongrui Zhao, Donghui Wang

Auto-TLDR; TextVQA: An End-to-End Visual Question Answering Model for Text-Based VQA
RMS-Net: Regression and Masking for Soccer Event Spotting
Matteo Tomei, Lorenzo Baraldi, Simone Calderara, Simone Bronzin, Rita Cucchiara

Auto-TLDR; An Action Spotting Network for Soccer Videos
Abstract Slides Poster Similar
Video Summarization with a Dual Attention Capsule Network
Hao Fu, Hongxing Wang, Jianyu Yang

Auto-TLDR; Dual Self-Attention Capsule Network for Video Summarization
Abstract Slides Poster Similar
Precise Temporal Action Localization with Quantified Temporal Structure of Actions
Chongkai Lu, Ruimin Li, Hong Fu, Bin Fu, Yihao Wang, Wai Lun Lo, Zheru Chi

Auto-TLDR; Action progression networks for temporal action detection
Abstract Slides Poster Similar
Transformer Reasoning Network for Image-Text Matching and Retrieval
Nicola Messina, Fabrizio Falchi, Andrea Esuli, Giuseppe Amato

Auto-TLDR; A Transformer Encoder Reasoning Network for Image-Text Matching in Large-Scale Information Retrieval
Abstract Slides Poster Similar
Context Matters: Self-Attention for Sign Language Recognition
Fares Ben Slimane, Mohamed Bouguessa

Auto-TLDR; Attentional Network for Continuous Sign Language Recognition
Abstract Slides Poster Similar
Integrating Historical States and Co-Attention Mechanism for Visual Dialog
Tianling Jiang, Yi Ji, Chunping Liu

Auto-TLDR; Integrating Historical States and Co-attention for Visual Dialog
Abstract Slides Poster Similar
Activity and Relationship Modeling Driven Weakly Supervised Object Detection
Yinlin Li, Yang Qian, Xu Yang, Yuren Zhang
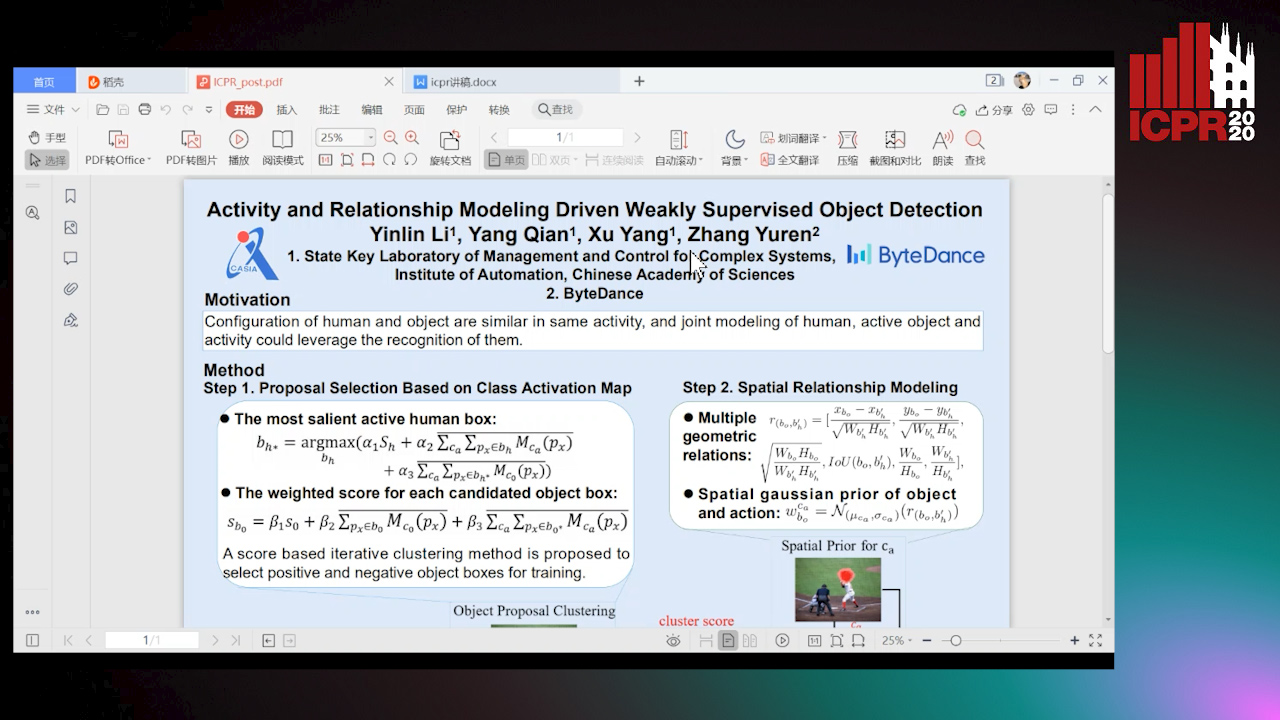
Auto-TLDR; Weakly Supervised Object Detection Using Activity Label and Relationship Modeling
Abstract Slides Poster Similar
Multi-Modal Contextual Graph Neural Network for Text Visual Question Answering
Yaoyuan Liang, Xin Wang, Xuguang Duan, Wenwu Zhu

Auto-TLDR; Multi-modal Contextual Graph Neural Network for Text Visual Question Answering
Abstract Slides Poster Similar
Cross-Lingual Text Image Recognition Via Multi-Task Sequence to Sequence Learning
Zhuo Chen, Fei Yin, Xu-Yao Zhang, Qing Yang, Cheng-Lin Liu

Auto-TLDR; Cross-Lingual Text Image Recognition with Multi-task Learning
Abstract Slides Poster Similar
Aggregating Object Features Based on Attention Weights for Fine-Grained Image Retrieval
Hongli Lin, Yongqi Song, Zixuan Zeng, Weisheng Wang

Auto-TLDR; DSAW: Unsupervised Dual-selection for Fine-Grained Image Retrieval
A Multi-Head Self-Relation Network for Scene Text Recognition
Zhou Junwei, Hongchao Gao, Jiao Dai, Dongqin Liu, Jizhong Han

Auto-TLDR; Multi-head Self-relation Network for Scene Text Recognition
Abstract Slides Poster Similar
Zero-Shot Text Classification with Semantically Extended Graph Convolutional Network
Tengfei Liu, Yongli Hu, Junbin Gao, Yanfeng Sun, Baocai Yin

Auto-TLDR; Semantically Extended Graph Convolutional Network for Zero-shot Text Classification
Abstract Slides Poster Similar
ConvMath : A Convolutional Sequence Network for Mathematical Expression Recognition
Zuoyu Yan, Xiaode Zhang, Liangcai Gao, Ke Yuan, Zhi Tang

Auto-TLDR; Convolutional Sequence Modeling for Mathematical Expressions Recognition
Abstract Slides Poster Similar
Label Incorporated Graph Neural Networks for Text Classification
Yuan Xin, Linli Xu, Junliang Guo, Jiquan Li, Xin Sheng, Yuanyuan Zhou

Auto-TLDR; Graph Neural Networks for Semi-supervised Text Classification
Abstract Slides Poster Similar
Using Scene Graphs for Detecting Visual Relationships
Anurag Tripathi, Siddharth Srivastava, Brejesh Lall, Santanu Chaudhury

Auto-TLDR; Relationship Detection using Context Aligned Scene Graph Embeddings
Abstract Slides Poster Similar
Audio-Based Near-Duplicate Video Retrieval with Audio Similarity Learning
Pavlos Avgoustinakis, Giorgos Kordopatis-Zilos, Symeon Papadopoulos, Andreas L. Symeonidis, Ioannis Kompatsiaris

Auto-TLDR; AuSiL: Audio Similarity Learning for Near-duplicate Video Retrieval
Abstract Slides Poster Similar
Learnable Higher-Order Representation for Action Recognition

Auto-TLDR; Learningable Higher-Order Operations for Spatiotemporal Dynamics in Video Recognition
What and How? Jointly Forecasting Human Action and Pose
Yanjun Zhu, Yanxia Zhang, Qiong Liu, Andreas Girgensohn

Auto-TLDR; Forecasting Human Actions and Motion Trajectories with Joint Action Classification and Pose Regression
Abstract Slides Poster Similar
Detective: An Attentive Recurrent Model for Sparse Object Detection
Amine Kechaou, Manuel Martinez, Monica Haurilet, Rainer Stiefelhagen

Auto-TLDR; Detective: An attentive object detector that identifies objects in images in a sequential manner
Abstract Slides Poster Similar
Multi-Stage Attention Based Visual Question Answering
Aakansha Mishra, Ashish Anand, Prithwijit Guha

Auto-TLDR; Alternative Bi-directional Attention for Visual Question Answering
Beyond the Deep Metric Learning: Enhance the Cross-Modal Matching with Adversarial Discriminative Domain Regularization
Li Ren, Kai Li, Liqiang Wang, Kien Hua

Auto-TLDR; Adversarial Discriminative Domain Regularization for Efficient Cross-Modal Matching
Abstract Slides Poster Similar
Boundary-Aware Graph Convolution for Semantic Segmentation
Hanzhe Hu, Jinshi Cui, Jinshi Hongbin Zha

Auto-TLDR; Boundary-Aware Graph Convolution for Semantic Segmentation
Abstract Slides Poster Similar
Global Context-Based Network with Transformer for Image2latex
Nuo Pang, Chun Yang, Xiaobin Zhu, Jixuan Li, Xu-Cheng Yin

Auto-TLDR; Image2latex with Global Context block and Transformer
Abstract Slides Poster Similar
Flow-Guided Spatial Attention Tracking for Egocentric Activity Recognition

Auto-TLDR; flow-guided spatial attention tracking for egocentric activity recognition
Abstract Slides Poster Similar
RWF-2000: An Open Large Scale Video Database for Violence Detection
Ming Cheng, Kunjing Cai, Ming Li

Auto-TLDR; Flow Gated Network for Violence Detection in Surveillance Cameras
Abstract Slides Poster Similar
Continuous Sign Language Recognition with Iterative Spatiotemporal Fine-Tuning
Kenessary Koishybay, Medet Mukushev, Anara Sandygulova

Auto-TLDR; A Deep Neural Network for Continuous Sign Language Recognition with Iterative Gloss Recognition
Abstract Slides Poster Similar
Self-Training for Domain Adaptive Scene Text Detection
Yudi Chen, Wei Wang, Yu Zhou, Fei Yang, Dongbao Yang, Weiping Wang

Auto-TLDR; A self-training framework for image-based scene text detection
Talking Face Generation Via Learning Semantic and Temporal Synchronous Landmarks
Aihua Zheng, Feixia Zhu, Hao Zhu, Mandi Luo, Ran He

Auto-TLDR; A semantic and temporal synchronous landmark learning method for talking face generation
Abstract Slides Poster Similar
PICK: Processing Key Information Extraction from Documents Using Improved Graph Learning-Convolutional Networks
Wenwen Yu, Ning Lu, Xianbiao Qi, Ping Gong, Rong Xiao

Auto-TLDR; PICK: A Graph Learning Framework for Key Information Extraction from Documents
Abstract Slides Poster Similar
Towards Practical Compressed Video Action Recognition: A Temporal Enhanced Multi-Stream Network
Bing Li, Longteng Kong, Dongming Zhang, Xiuguo Bao, Di Huang, Yunhong Wang

Auto-TLDR; TEMSN: Temporal Enhanced Multi-Stream Network for Compressed Video Action Recognition
Abstract Slides Poster Similar
PIN: A Novel Parallel Interactive Network for Spoken Language Understanding
Peilin Zhou, Zhiqi Huang, Fenglin Liu, Yuexian Zou

Auto-TLDR; Parallel Interactive Network for Spoken Language Understanding
Abstract Slides Poster Similar