Feature Pyramid Hierarchies for Multi-Scale Temporal Action Detection

Auto-TLDR; Temporal Action Detection using Pyramid Hierarchies and Multi-scale Feature Maps
Similar papers
You Ought to Look Around: Precise, Large Span Action Detection
Ge Pan, Zhang Han, Fan Yu, Yonghong Song, Yuanlin Zhang, Han Yuan

Auto-TLDR; YOLA: Local Feature Extraction for Action Localization with Variable receptive field
Gabriella: An Online System for Real-Time Activity Detection in Untrimmed Security Videos
Mamshad Nayeem Rizve, Ugur Demir, Praveen Praveen Tirupattur, Aayush Jung Rana, Kevin Duarte, Ishan Rajendrakumar Dave, Yogesh Rawat, Mubarak Shah

Auto-TLDR; Gabriella: A Real-Time Online System for Activity Detection in Surveillance Videos
ActionSpotter: Deep Reinforcement Learning Framework for Temporal Action Spotting in Videos
Guillaume Vaudaux-Ruth, Adrien Chan-Hon-Tong, Catherine Achard

Auto-TLDR; ActionSpotter: A Reinforcement Learning Algorithm for Action Spotting in Video
Abstract Slides Poster Similar
Precise Temporal Action Localization with Quantified Temporal Structure of Actions
Chongkai Lu, Ruimin Li, Hong Fu, Bin Fu, Yihao Wang, Wai Lun Lo, Zheru Chi

Auto-TLDR; Action progression networks for temporal action detection
Abstract Slides Poster Similar
RMS-Net: Regression and Masking for Soccer Event Spotting
Matteo Tomei, Lorenzo Baraldi, Simone Calderara, Simone Bronzin, Rita Cucchiara

Auto-TLDR; An Action Spotting Network for Soccer Videos
Abstract Slides Poster Similar
RWF-2000: An Open Large Scale Video Database for Violence Detection
Ming Cheng, Kunjing Cai, Ming Li

Auto-TLDR; Flow Gated Network for Violence Detection in Surveillance Cameras
Abstract Slides Poster Similar
Scene Text Detection with Selected Anchors
Anna Zhu, Hang Du, Shengwu Xiong

Auto-TLDR; AS-RPN: Anchor Selection-based Region Proposal Network for Scene Text Detection
Abstract Slides Poster Similar
TinyVIRAT: Low-Resolution Video Action Recognition
Ugur Demir, Yogesh Rawat, Mubarak Shah

Auto-TLDR; TinyVIRAT: A Progressive Generative Approach for Action Recognition in Videos
Abstract Slides Poster Similar
Bidirectional Matrix Feature Pyramid Network for Object Detection

Auto-TLDR; BMFPN: Bidirectional Matrix Feature Pyramid Network for Object Detection
Abstract Slides Poster Similar
MFI: Multi-Range Feature Interchange for Video Action Recognition
Sikai Bai, Qi Wang, Xuelong Li

Auto-TLDR; Multi-range Feature Interchange Network for Action Recognition in Videos
Abstract Slides Poster Similar
SFPN: Semantic Feature Pyramid Network for Object Detection

Auto-TLDR; SFPN: Semantic Feature Pyramid Network to Address Information Dilution Issue in FPN
Abstract Slides Poster Similar
Multi-Scale 2D Representation Learning for Weakly-Supervised Moment Retrieval
Ding Li, Rui Wu, Zhizhong Zhang, Yongqiang Tang, Wensheng Zhang

Auto-TLDR; Multi-scale 2D Representation Learning for Weakly Supervised Video Moment Retrieval
Abstract Slides Poster Similar
Learning a Dynamic High-Resolution Network for Multi-Scale Pedestrian Detection
Mengyuan Ding, Shanshan Zhang, Jian Yang

Auto-TLDR; Learningable Dynamic HRNet for Pedestrian Detection
Abstract Slides Poster Similar
What and How? Jointly Forecasting Human Action and Pose
Yanjun Zhu, Yanxia Zhang, Qiong Liu, Andreas Girgensohn

Auto-TLDR; Forecasting Human Actions and Motion Trajectories with Joint Action Classification and Pose Regression
Abstract Slides Poster Similar
Learnable Higher-Order Representation for Action Recognition

Auto-TLDR; Learningable Higher-Order Operations for Spatiotemporal Dynamics in Video Recognition
Self-Supervised Joint Encoding of Motion and Appearance for First Person Action Recognition
Mirco Planamente, Andrea Bottino, Barbara Caputo

Auto-TLDR; A Single Stream Architecture for Egocentric Action Recognition from the First-Person Point of View
Abstract Slides Poster Similar
Construction Worker Hardhat-Wearing Detection Based on an Improved BiFPN
Chenyang Zhang, Zhiqiang Tian, Jingyi Song, Yaoyue Zheng, Bo Xu

Auto-TLDR; A One-Stage Object Detection Method for Hardhat-Wearing in Construction Site
Abstract Slides Poster Similar
Triplet-Path Dilated Network for Detection and Segmentation of General Pathological Images
Jiaqi Luo, Zhicheng Zhao, Fei Su, Limei Guo

Auto-TLDR; Triplet-path Network for One-Stage Object Detection and Segmentation in Pathological Images
Late Fusion of Bayesian and Convolutional Models for Action Recognition
Camille Maurice, Francisco Madrigal, Frederic Lerasle

Auto-TLDR; Fusion of Deep Neural Network and Bayesian-based Approach for Temporal Action Recognition
Abstract Slides Poster Similar
Object Detection Model Based on Scene-Level Region Proposal Self-Attention
Yu Quan, Zhixin Li, Canlong Zhang, Huifang Ma

Auto-TLDR; Exploiting Semantic Informations for Object Detection
Abstract Slides Poster Similar
Feature-Supervised Action Modality Transfer
Fida Mohammad Thoker, Cees Snoek

Auto-TLDR; Cross-Modal Action Recognition and Detection in Non-RGB Video Modalities by Learning from Large-Scale Labeled RGB Data
Abstract Slides Poster Similar
CenterRepp: Predict Central Representative Point Set's Distribution for Detection
Yulin He, Limeng Zhang, Wei Chen, Xin Luo, Chen Li, Xiaogang Jia

Auto-TLDR; CRPDet: CenterRepp Detector for Object Detection
Abstract Slides Poster Similar
Cascade Saliency Attention Network for Object Detection in Remote Sensing Images
Dayang Yu, Rong Zhang, Shan Qin

Auto-TLDR; Cascade Saliency Attention Network for Object Detection in Remote Sensing Images
Abstract Slides Poster Similar
PRF-Ped: Multi-Scale Pedestrian Detector with Prior-Based Receptive Field
Yuzhi Tan, Hongxun Yao, Haoran Li, Xiusheng Lu, Haozhe Xie

Auto-TLDR; Bidirectional Feature Enhancement Module for Multi-Scale Pedestrian Detection
Abstract Slides Poster Similar
Towards Practical Compressed Video Action Recognition: A Temporal Enhanced Multi-Stream Network
Bing Li, Longteng Kong, Dongming Zhang, Xiuguo Bao, Di Huang, Yunhong Wang

Auto-TLDR; TEMSN: Temporal Enhanced Multi-Stream Network for Compressed Video Action Recognition
Abstract Slides Poster Similar
Video Object Detection Using Object's Motion Context and Spatio-Temporal Feature Aggregation
Jaekyum Kim, Junho Koh, Byeongwon Lee, Seungji Yang, Jun Won Choi

Auto-TLDR; Video Object Detection Using Spatio-Temporal Aggregated Features and Gated Attention Network
Abstract Slides Poster Similar
Revisiting Sequence-To-Sequence Video Object Segmentation with Multi-Task Loss and Skip-Memory
Fatemeh Azimi, Benjamin Bischke, Sebastian Palacio, Federico Raue, Jörn Hees, Andreas Dengel

Auto-TLDR; Sequence-to-Sequence Learning for Video Object Segmentation
Abstract Slides Poster Similar
Developing Motion Code Embedding for Action Recognition in Videos
Maxat Alibayev, David Andrea Paulius, Yu Sun

Auto-TLDR; Motion Embedding via Motion Codes for Action Recognition
Abstract Slides Poster Similar
Modeling Long-Term Interactions to Enhance Action Recognition
Alejandro Cartas, Petia Radeva, Mariella Dimiccoli

Auto-TLDR; A Hierarchical Long Short-Term Memory Network for Action Recognition in Egocentric Videos
Abstract Slides Poster Similar
A Novel Region of Interest Extraction Layer for Instance Segmentation
Leonardo Rossi, Akbar Karimi, Andrea Prati

Auto-TLDR; Generic RoI Extractor for Two-Stage Neural Network for Instance Segmentation
Abstract Slides Poster Similar
Hierarchical Head Design for Object Detectors
Shivang Agarwal, Frederic Jurie

Auto-TLDR; Hierarchical Anchor for SSD Detector
Abstract Slides Poster Similar
Correlation-Based ConvNet for Small Object Detection in Videos
Brais Bosquet, Manuel Mucientes, Victor Brea

Auto-TLDR; STDnet-ST: An End-to-End Spatio-Temporal Convolutional Neural Network for Small Object Detection in Video
Abstract Slides Poster Similar
CAggNet: Crossing Aggregation Network for Medical Image Segmentation

Auto-TLDR; Crossing Aggregation Network for Medical Image Segmentation
Abstract Slides Poster Similar
Pose-Based Body Language Recognition for Emotion and Psychiatric Symptom Interpretation
Zhengyuan Yang, Amanda Kay, Yuncheng Li, Wendi Cross, Jiebo Luo

Auto-TLDR; Body Language Based Emotion Recognition for Psychiatric Symptoms Prediction
Abstract Slides Poster Similar
Attention-Oriented Action Recognition for Real-Time Human-Robot Interaction
Ziyang Song, Ziyi Yin, Zejian Yuan, Chong Zhang, Wanchao Chi, Yonggen Ling, Shenghao Zhang

Auto-TLDR; Attention-Oriented Multi-Level Network for Action Recognition in Interaction Scenes
Abstract Slides Poster Similar
A Multi-Task Neural Network for Action Recognition with 3D Key-Points
Rongxiao Tang, Wang Luyang, Zhenhua Guo

Auto-TLDR; Multi-task Neural Network for Action Recognition and 3D Human Pose Estimation
Abstract Slides Poster Similar
Activity Recognition Using First-Person-View Cameras Based on Sparse Optical Flows
Peng-Yuan Kao, Yan-Jing Lei, Chia-Hao Chang, Chu-Song Chen, Ming-Sui Lee, Yi-Ping Hung

Auto-TLDR; 3D Convolutional Neural Network for Activity Recognition with FPV Videos
Abstract Slides Poster Similar
Flow-Guided Spatial Attention Tracking for Egocentric Activity Recognition

Auto-TLDR; flow-guided spatial attention tracking for egocentric activity recognition
Abstract Slides Poster Similar
Mutual-Supervised Feature Modulation Network for Occluded Pedestrian Detection

Auto-TLDR; A Mutual-Supervised Feature Modulation Network for Occluded Pedestrian Detection
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
Video Representation Fusion Network For Multi-Label Movie Genre Classification
Tianyu Bi, Dmitri Jarnikov, Johan Lukkien

Auto-TLDR; A Video Representation Fusion Network for Movie Genre Classification
Abstract Slides Poster Similar
Detecting Objects with High Object Region Percentage
Fen Fang, Qianli Xu, Liyuan Li, Ying Gu, Joo-Hwee Lim

Auto-TLDR; Faster R-CNN for High-ORP Object Detection
Abstract Slides Poster Similar
MixTConv: Mixed Temporal Convolutional Kernels for Efficient Action Recognition
Kaiyu Shan, Yongtao Wang, Zhi Tang, Ying Chen, Yangyan Li

Auto-TLDR; Mixed Temporal Convolution for Action Recognition
Abstract Slides Poster Similar
TSMSAN: A Three-Stream Multi-Scale Attentive Network for Video Saliency Detection
Jingwen Yang, Guanwen Zhang, Wei Zhou

Auto-TLDR; Three-stream Multi-scale attentive network for video saliency detection in dynamic scenes
Abstract Slides Poster Similar
Activity and Relationship Modeling Driven Weakly Supervised Object Detection
Yinlin Li, Yang Qian, Xu Yang, Yuren Zhang
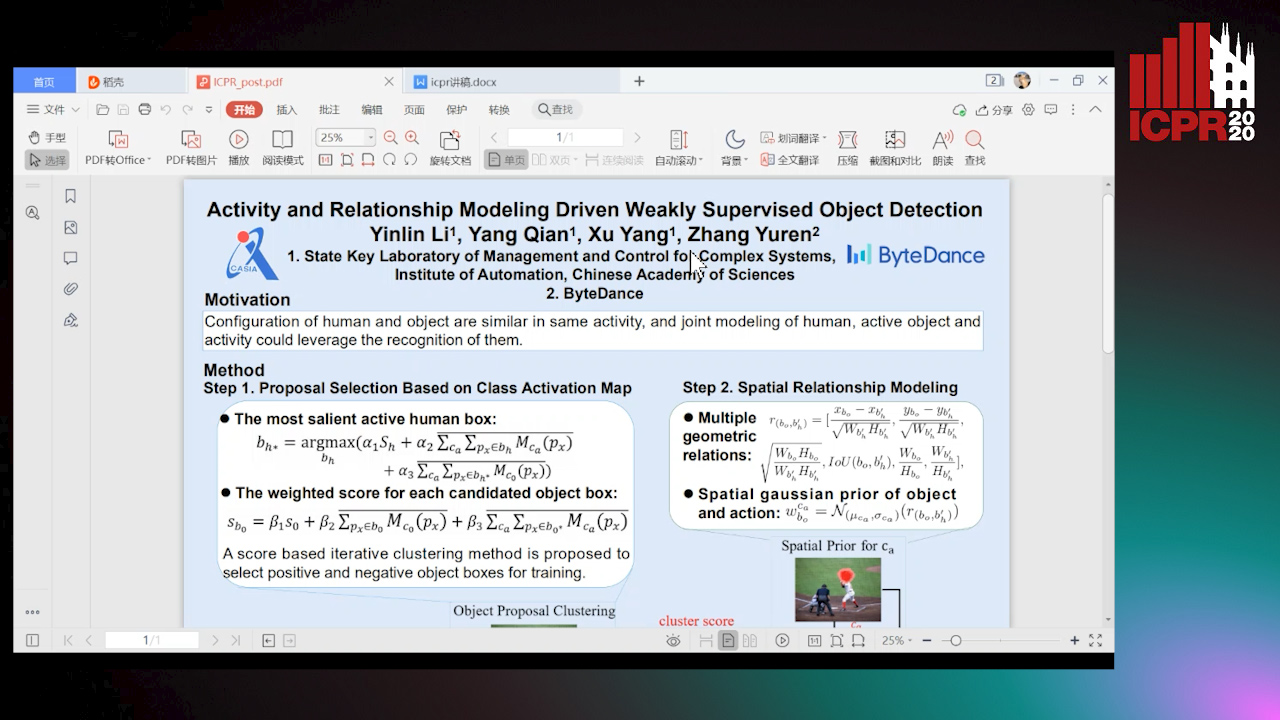
Auto-TLDR; Weakly Supervised Object Detection Using Activity Label and Relationship Modeling
Abstract Slides Poster Similar
Attentive Visual Semantic Specialized Network for Video Captioning
Jesus Perez-Martin, Benjamin Bustos, Jorge Pérez

Auto-TLDR; Adaptive Visual Semantic Specialized Network for Video Captioning
Abstract Slides Poster Similar
Extracting Action Hierarchies from Action Labels and their Use in Deep Action Recognition
Konstadinos Bacharidis, Antonis Argyros

Auto-TLDR; Exploiting the Information Content of Language Label Associations for Human Action Recognition
Abstract Slides Poster Similar
Hierarchical Multimodal Attention for Deep Video Summarization
Melissa Sanabria, Frederic Precioso, Thomas Menguy

Auto-TLDR; Automatic Summarization of Professional Soccer Matches Using Event-Stream Data and Multi- Instance Learning
Abstract Slides Poster Similar