SL-DML: Signal Level Deep Metric Learning for Multimodal One-Shot Action Recognition
Raphael Memmesheimer,
Nick Theisen,
Dietrich Paulus

Auto-TLDR; One-Shot Action Recognition using Metric Learning
Similar papers
Vision-Based Multi-Modal Framework for Action Recognition
Djamila Romaissa Beddiar, Mourad Oussalah, Brahim Nini

Auto-TLDR; Multi-modal Framework for Human Activity Recognition Using RGB, Depth and Skeleton Data
Abstract Slides Poster Similar
Vertex Feature Encoding and Hierarchical Temporal Modeling in a Spatio-Temporal Graph Convolutional Network for Action Recognition
Konstantinos Papadopoulos, Enjie Ghorbel, Djamila Aouada, Bjorn Ottersten

Auto-TLDR; Spatio-Temporal Graph Convolutional Network for Skeleton-Based Action Recognition
Abstract Slides Poster Similar
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
JT-MGCN: Joint-Temporal Motion Graph Convolutional Network for Skeleton-Based Action Recognition

Auto-TLDR; Joint-temporal Motion Graph Convolutional Networks for Action Recognition
Temporal Attention-Augmented Graph Convolutional Network for Efficient Skeleton-Based Human Action Recognition
Negar Heidari, Alexandros Iosifidis

Auto-TLDR; Temporal Attention Module for Efficient Graph Convolutional Network-based Action Recognition
Abstract Slides Poster Similar
Attention-Driven Body Pose Encoding for Human Activity Recognition
Bappaditya Debnath, Swagat Kumar, Marry O'Brien, Ardhendu Behera

Auto-TLDR; Attention-based Body Pose Encoding for Human Activity Recognition
Abstract Slides Poster Similar
What and How? Jointly Forecasting Human Action and Pose
Yanjun Zhu, Yanxia Zhang, Qiong Liu, Andreas Girgensohn

Auto-TLDR; Forecasting Human Actions and Motion Trajectories with Joint Action Classification and Pose Regression
Abstract Slides Poster Similar
Channel-Wise Dense Connection Graph Convolutional Network for Skeleton-Based Action Recognition
Michael Lao Banteng, Zhiyong Wu

Auto-TLDR; Two-stream channel-wise dense connection GCN for human action recognition
Abstract Slides Poster Similar
Feature-Supervised Action Modality Transfer
Fida Mohammad Thoker, Cees Snoek

Auto-TLDR; Cross-Modal Action Recognition and Detection in Non-RGB Video Modalities by Learning from Large-Scale Labeled RGB Data
Abstract Slides Poster Similar
DeepPear: Deep Pose Estimation and Action Recognition
Wen-Jiin Tsai, You-Ying Jhuang

Auto-TLDR; Human Action Recognition Using RGB Video Using 3D Human Pose and Appearance Features
Abstract Slides Poster Similar
A Two-Stream Recurrent Network for Skeleton-Based Human Interaction Recognition
Qianhui Men, Edmond S. L. Ho, Shum Hubert P. H., Howard Leung

Auto-TLDR; Two-Stream Recurrent Neural Network for Human-Human Interaction Recognition
Abstract Slides Poster Similar
Recurrent Graph Convolutional Networks for Skeleton-Based Action Recognition
Guangming Zhu, Lu Yang, Liang Zhang, Peiyi Shen, Juan Song

Auto-TLDR; Recurrent Graph Convolutional Network for Human Action Recognition
Abstract Slides Poster Similar
A Multi-Task Neural Network for Action Recognition with 3D Key-Points
Rongxiao Tang, Wang Luyang, Zhenhua Guo

Auto-TLDR; Multi-task Neural Network for Action Recognition and 3D Human Pose Estimation
Abstract Slides Poster Similar
Temporal Extension Module for Skeleton-Based Action Recognition

Auto-TLDR; Extended Temporal Graph for Action Recognition with Kinetics-Skeleton
Abstract Slides Poster Similar
Nonlinear Ranking Loss on Riemannian Potato Embedding
Byung Hyung Kim, Yoonje Suh, Honggu Lee, Sungho Jo

Auto-TLDR; Riemannian Potato for Rank-based Metric Learning
Abstract Slides Poster Similar
A Prototype-Based Generalized Zero-Shot Learning Framework for Hand Gesture Recognition
Jinting Wu, Yujia Zhang, Xiao-Guang Zhao

Auto-TLDR; Generalized Zero-Shot Learning for Hand Gesture Recognition
Abstract Slides Poster Similar
Space-Time Domain Tensor Neural Networks: An Application on Human Pose Classification
Konstantinos Makantasis, Athanasios Voulodimos, Anastasios Doulamis, Nikolaos Doulamis, Nikolaos Bakalos

Auto-TLDR; Tensor-Based Neural Network for Spatiotemporal Pose Classifiaction using Three-Dimensional Skeleton Data
Abstract Slides Poster Similar
Pose-Based Body Language Recognition for Emotion and Psychiatric Symptom Interpretation
Zhengyuan Yang, Amanda Kay, Yuncheng Li, Wendi Cross, Jiebo Luo

Auto-TLDR; Body Language Based Emotion Recognition for Psychiatric Symptoms Prediction
Abstract Slides Poster Similar
Developing Motion Code Embedding for Action Recognition in Videos
Maxat Alibayev, David Andrea Paulius, Yu Sun

Auto-TLDR; Motion Embedding via Motion Codes for Action Recognition
Abstract Slides Poster Similar
Single View Learning in Action Recognition
Gaurvi Goyal, Nicoletta Noceti, Francesca Odone

Auto-TLDR; Cross-View Action Recognition Using Domain Adaptation for Knowledge Transfer
Abstract Slides Poster Similar
Attention-Oriented Action Recognition for Real-Time Human-Robot Interaction
Ziyang Song, Ziyi Yin, Zejian Yuan, Chong Zhang, Wanchao Chi, Yonggen Ling, Shenghao Zhang

Auto-TLDR; Attention-Oriented Multi-Level Network for Action Recognition in Interaction Scenes
Abstract Slides Poster Similar
Anticipating Activity from Multimodal Signals
Tiziana Rotondo, Giovanni Maria Farinella, Davide Giacalone, Sebastiano Mauro Strano, Valeria Tomaselli, Sebastiano Battiato

Auto-TLDR; Exploiting Multimodal Signal Embedding Space for Multi-Action Prediction
Abstract Slides Poster Similar
Subspace Clustering for Action Recognition with Covariance Representations and Temporal Pruning
Giancarlo Paoletti, Jacopo Cavazza, Cigdem Beyan, Alessio Del Bue

Auto-TLDR; Unsupervised Learning for Human Action Recognition from Skeletal Data
Self-Supervised Joint Encoding of Motion and Appearance for First Person Action Recognition
Mirco Planamente, Andrea Bottino, Barbara Caputo

Auto-TLDR; A Single Stream Architecture for Egocentric Action Recognition from the First-Person Point of View
Abstract Slides Poster Similar
Learning Embeddings for Image Clustering: An Empirical Study of Triplet Loss Approaches
Kalun Ho, Janis Keuper, Franz-Josef Pfreundt, Margret Keuper

Auto-TLDR; Clustering Objectives for K-means and Correlation Clustering Using Triplet Loss
Abstract Slides Poster Similar
Generalized Local Attention Pooling for Deep Metric Learning
Carlos Roig Mari, David Varas, Issey Masuda, Juan Carlos Riveiro, Elisenda Bou-Balust

Auto-TLDR; Generalized Local Attention Pooling for Deep Metric Learning
Abstract Slides Poster Similar
Learning Group Activities from Skeletons without Individual Action Labels
Fabio Zappardino, Tiberio Uricchio, Lorenzo Seidenari, Alberto Del Bimbo

Auto-TLDR; Lean Pose Only for Group Activity Recognition
Building Computationally Efficient and Well-Generalizing Person Re-Identification Models with Metric Learning
Vladislav Sovrasov, Dmitry Sidnev

Auto-TLDR; Cross-Domain Generalization in Person Re-identification using Omni-Scale Network
RGB-Infrared Person Re-Identification Via Image Modality Conversion
Huangpeng Dai, Qing Xie, Yanchun Ma, Yongjian Liu, Shengwu Xiong

Auto-TLDR; CE2L: A Novel Network for Cross-Modality Re-identification with Feature Alignment
Abstract Slides Poster Similar
Learning Recurrent High-Order Statistics for Skeleton-Based Hand Gesture Recognition
Xuan Son Nguyen, Luc Brun, Olivier Lezoray, Sébastien Bougleux
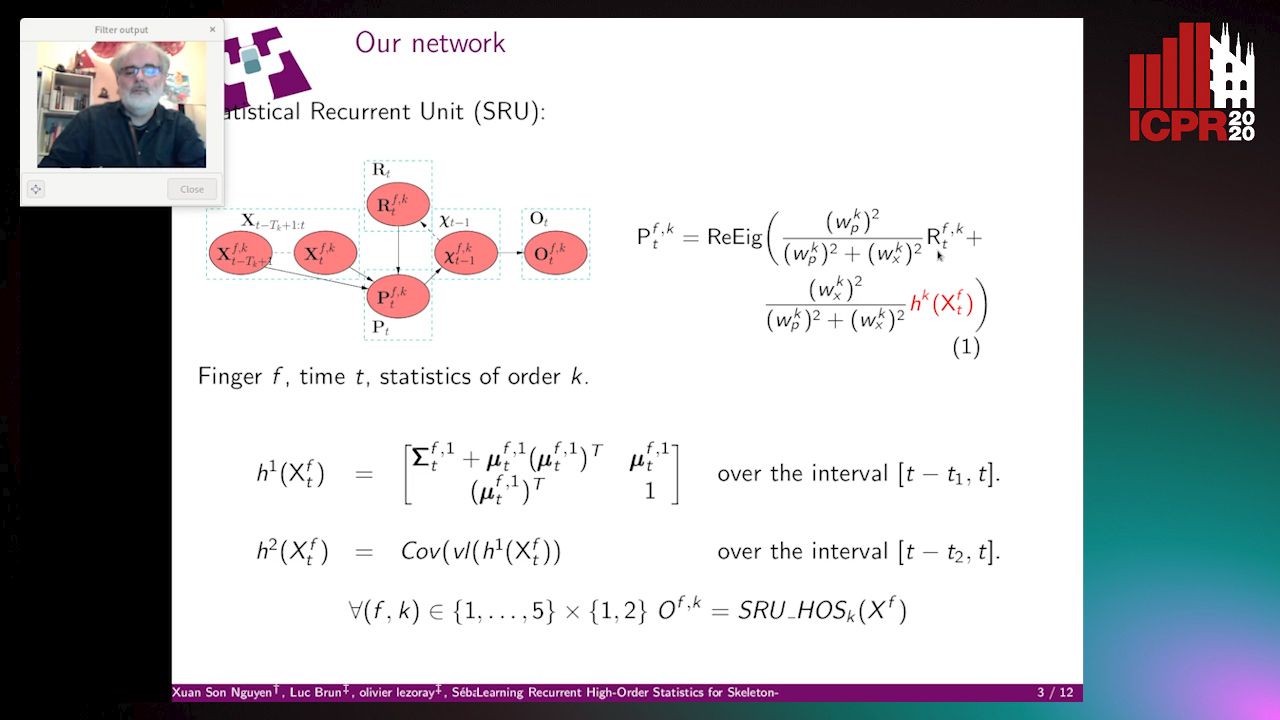
Auto-TLDR; Exploiting High-Order Statistics in Recurrent Neural Networks for Hand Gesture Recog-nition
Multi-Level Deep Learning Vehicle Re-Identification Using Ranked-Based Loss Functions
Eleni Kamenou, Jesus Martinez-Del-Rincon, Paul Miller, Patricia Devlin - Hill

Auto-TLDR; Multi-Level Re-identification Network for Vehicle Re-Identification
Abstract Slides Poster Similar
Semantics to Space(S2S): Embedding Semantics into Spatial Space for Zero-Shot Verb-Object Query Inferencing

Auto-TLDR; Semantics-to-Space: Deep Zero-Shot Learning for Verb-Object Interaction with Vectors
Abstract Slides Poster Similar
Not 3D Re-ID: Simple Single Stream 2D Convolution for Robust Video Re-Identification

Auto-TLDR; ResNet50-IBN for Video-based Person Re-Identification using Single Stream 2D Convolution Network
Abstract Slides Poster Similar
Temporally Coherent Embeddings for Self-Supervised Video Representation Learning
Joshua Knights, Ben Harwood, Daniel Ward, Anthony Vanderkop, Olivia Mackenzie-Ross, Peyman Moghadam

Auto-TLDR; Temporally Coherent Embeddings for Self-supervised Video Representation Learning
Abstract Slides Poster Similar
Late Fusion of Bayesian and Convolutional Models for Action Recognition
Camille Maurice, Francisco Madrigal, Frederic Lerasle

Auto-TLDR; Fusion of Deep Neural Network and Bayesian-based Approach for Temporal Action Recognition
Abstract Slides Poster Similar
Loop-closure detection by LiDAR scan re-identification
Jukka Peltomäki, Xingyang Ni, Jussi Puura, Joni-Kristian Kamarainen, Heikki Juhani Huttunen

Auto-TLDR; Loop-Closing Detection from LiDAR Scans Using Convolutional Neural Networks
Abstract Slides Poster Similar
Progressive Learning Algorithm for Efficient Person Re-Identification
Zhen Li, Hanyang Shao, Liang Niu, Nian Xue

Auto-TLDR; Progressive Learning Algorithm for Large-Scale Person Re-Identification
Abstract Slides Poster Similar
Towards Practical Compressed Video Action Recognition: A Temporal Enhanced Multi-Stream Network
Bing Li, Longteng Kong, Dongming Zhang, Xiuguo Bao, Di Huang, Yunhong Wang

Auto-TLDR; TEMSN: Temporal Enhanced Multi-Stream Network for Compressed Video Action Recognition
Abstract Slides Poster Similar
Attention-Based Deep Metric Learning for Near-Duplicate Video Retrieval
Kuan-Hsun Wang, Chia Chun Cheng, Yi-Ling Chen, Yale Song, Shang-Hong Lai

Auto-TLDR; Attention-based Deep Metric Learning for Near-duplicate Video Retrieval
Deep Gait Relative Attribute Using a Signed Quadratic Contrastive Loss
Yuta Hayashi, Shehata Allam, Yasushi Makihara, Daigo Muramatsu, Yasushi Yagi

Auto-TLDR; Signal-Contrastive Loss for Gait Attributes Estimation
One-Shot Representational Learning for Joint Biometric and Device Authentication

Auto-TLDR; Joint Biometric and Device Recognition from a Single Biometric Image
Abstract Slides Poster Similar
Activity Recognition Using First-Person-View Cameras Based on Sparse Optical Flows
Peng-Yuan Kao, Yan-Jing Lei, Chia-Hao Chang, Chu-Song Chen, Ming-Sui Lee, Yi-Ping Hung

Auto-TLDR; 3D Convolutional Neural Network for Activity Recognition with FPV Videos
Abstract Slides Poster Similar
Top-DB-Net: Top DropBlock for Activation Enhancement in Person Re-Identification

Auto-TLDR; Top-DB-Net for Person Re-Identification using Top DropBlock
Abstract Slides Poster Similar
Deep Top-Rank Counter Metric for Person Re-Identification
Chen Chen, Hao Dou, Xiyuan Hu, Silong Peng

Auto-TLDR; Deep Top-Rank Counter Metric for Person Re-identification
Abstract Slides Poster Similar
Kernel-based Graph Convolutional Networks

Auto-TLDR; Spatial Graph Convolutional Networks in Recurrent Kernel Hilbert Space
Abstract Slides Poster Similar
3D Facial Matching by Spiral Convolutional Metric Learning and a Biometric Fusion-Net of Demographic Properties
Soha Sadat Mahdi, Nele Nauwelaers, Philip Joris, Giorgos Bouritsas, Imperial London, Sergiy Bokhnyak, Susan Walsh, Mark Shriver, Michael Bronstein, Peter Claes

Auto-TLDR; Multi-biometric Fusion for Biometric Verification using 3D Facial Mesures
Two-Level Attention-Based Fusion Learning for RGB-D Face Recognition
Hardik Uppal, Alireza Sepas-Moghaddam, Michael Greenspan, Ali Etemad

Auto-TLDR; Fused RGB-D Facial Recognition using Attention-Aware Feature Fusion
Abstract Slides Poster Similar
Modeling Long-Term Interactions to Enhance Action Recognition
Alejandro Cartas, Petia Radeva, Mariella Dimiccoli

Auto-TLDR; A Hierarchical Long Short-Term Memory Network for Action Recognition in Egocentric Videos
Abstract Slides Poster Similar