Kernel-based Graph Convolutional Networks

Auto-TLDR; Spatial Graph Convolutional Networks in Recurrent Kernel Hilbert Space
Similar papers
Learning Connectivity with Graph Convolutional Networks

Auto-TLDR; Learning Graph Convolutional Networks Using Topological Properties of Graphs
Abstract Slides Poster Similar
Vertex Feature Encoding and Hierarchical Temporal Modeling in a Spatio-Temporal Graph Convolutional Network for Action Recognition
Konstantinos Papadopoulos, Enjie Ghorbel, Djamila Aouada, Bjorn Ottersten

Auto-TLDR; Spatio-Temporal Graph Convolutional Network for Skeleton-Based Action Recognition
Abstract Slides Poster Similar
Temporal Attention-Augmented Graph Convolutional Network for Efficient Skeleton-Based Human Action Recognition
Negar Heidari, Alexandros Iosifidis

Auto-TLDR; Temporal Attention Module for Efficient Graph Convolutional Network-based Action Recognition
Abstract Slides Poster Similar
Channel-Wise Dense Connection Graph Convolutional Network for Skeleton-Based Action Recognition
Michael Lao Banteng, Zhiyong Wu

Auto-TLDR; Two-stream channel-wise dense connection GCN for human action recognition
Abstract Slides Poster Similar
Revisiting Graph Neural Networks: Graph Filtering Perspective
Hoang Nguyen-Thai, Takanori Maehara, Tsuyoshi Murata

Auto-TLDR; Two-Layers Graph Convolutional Network with Graph Filters Neural Network
Abstract Slides Poster Similar
Recurrent Graph Convolutional Networks for Skeleton-Based Action Recognition
Guangming Zhu, Lu Yang, Liang Zhang, Peiyi Shen, Juan Song

Auto-TLDR; Recurrent Graph Convolutional Network for Human Action Recognition
Abstract Slides Poster Similar
On the Global Self-attention Mechanism for Graph Convolutional Networks

Auto-TLDR; Global Self-Attention Mechanism for Graph Convolutional Networks
Graph Convolutional Neural Networks for Power Line Outage Identification

Auto-TLDR; Graph Convolutional Networks for Power Line Outage Identification
Region and Relations Based Multi Attention Network for Graph Classification
Manasvi Aggarwal, M. Narasimha Murty

Auto-TLDR; R2POOL: A Graph Pooling Layer for Non-euclidean Structures
Abstract Slides Poster Similar
Subspace Clustering for Action Recognition with Covariance Representations and Temporal Pruning
Giancarlo Paoletti, Jacopo Cavazza, Cigdem Beyan, Alessio Del Bue

Auto-TLDR; Unsupervised Learning for Human Action Recognition from Skeletal Data
A Two-Stream Recurrent Network for Skeleton-Based Human Interaction Recognition
Qianhui Men, Edmond S. L. Ho, Shum Hubert P. H., Howard Leung

Auto-TLDR; Two-Stream Recurrent Neural Network for Human-Human Interaction Recognition
Abstract Slides Poster Similar
Temporal Extension Module for Skeleton-Based Action Recognition

Auto-TLDR; Extended Temporal Graph for Action Recognition with Kinetics-Skeleton
Abstract Slides Poster Similar
JT-MGCN: Joint-Temporal Motion Graph Convolutional Network for Skeleton-Based Action Recognition

Auto-TLDR; Joint-temporal Motion Graph Convolutional Networks for Action Recognition
Edge-Aware Graph Attention Network for Ratio of Edge-User Estimation in Mobile Networks
Jiehui Deng, Sheng Wan, Xiang Wang, Enmei Tu, Xiaolin Huang, Jie Yang, Chen Gong

Auto-TLDR; EAGAT: Edge-Aware Graph Attention Network for Automatic REU Estimation in Mobile Networks
Abstract Slides Poster Similar
DeepPear: Deep Pose Estimation and Action Recognition
Wen-Jiin Tsai, You-Ying Jhuang

Auto-TLDR; Human Action Recognition Using RGB Video Using 3D Human Pose and Appearance Features
Abstract Slides Poster Similar
Space-Time Domain Tensor Neural Networks: An Application on Human Pose Classification
Konstantinos Makantasis, Athanasios Voulodimos, Anastasios Doulamis, Nikolaos Doulamis, Nikolaos Bakalos

Auto-TLDR; Tensor-Based Neural Network for Spatiotemporal Pose Classifiaction using Three-Dimensional Skeleton Data
Abstract Slides Poster Similar
Label Incorporated Graph Neural Networks for Text Classification
Yuan Xin, Linli Xu, Junliang Guo, Jiquan Li, Xin Sheng, Yuanyuan Zhou

Auto-TLDR; Graph Neural Networks for Semi-supervised Text Classification
Abstract Slides Poster Similar
Constructing Geographic and Long-term Temporal Graph for Traffic Forecasting
Yiwen Sun, Yulu Wang, Kun Fu, Zheng Wang, Changshui Zhang, Jieping Ye

Auto-TLDR; GLT-GCRNN: Geographic and Long-term Temporal Graph Convolutional Recurrent Neural Network for Traffic Forecasting
Abstract Slides Poster Similar
A General Model for Learning Node and Graph Representations Jointly

Auto-TLDR; Joint Community Detection/Dynamic Routing for Graph Classification
Abstract Slides Poster Similar
Classification of Intestinal Gland Cell-Graphs Using Graph Neural Networks
Linda Studer, Jannis Wallau, Heather Dawson, Inti Zlobec, Andreas Fischer

Auto-TLDR; Graph Neural Networks for Classification of Dysplastic Gland Glands using Graph Neural Networks
Abstract Slides Poster Similar
AOAM: Automatic Optimization of Adjacency Matrix for Graph Convolutional Network
Yuhang Zhang, Hongshuai Ren, Jiexia Ye, Xitong Gao, Yang Wang, Kejiang Ye, Cheng-Zhong Xu

Auto-TLDR; Adjacency Matrix for Graph Convolutional Network in Non-Euclidean Space
Abstract Slides Poster Similar
GCNs-Based Context-Aware Short Text Similarity Model

Auto-TLDR; Context-Aware Graph Convolutional Network for Text Similarity
Abstract Slides Poster Similar
A Grid-Based Representation for Human Action Recognition
Soufiane Lamghari, Guillaume-Alexandre Bilodeau, Nicolas Saunier

Auto-TLDR; GRAR: Grid-based Representation for Action Recognition in Videos
Abstract Slides Poster Similar
Learning Recurrent High-Order Statistics for Skeleton-Based Hand Gesture Recognition
Xuan Son Nguyen, Luc Brun, Olivier Lezoray, Sébastien Bougleux
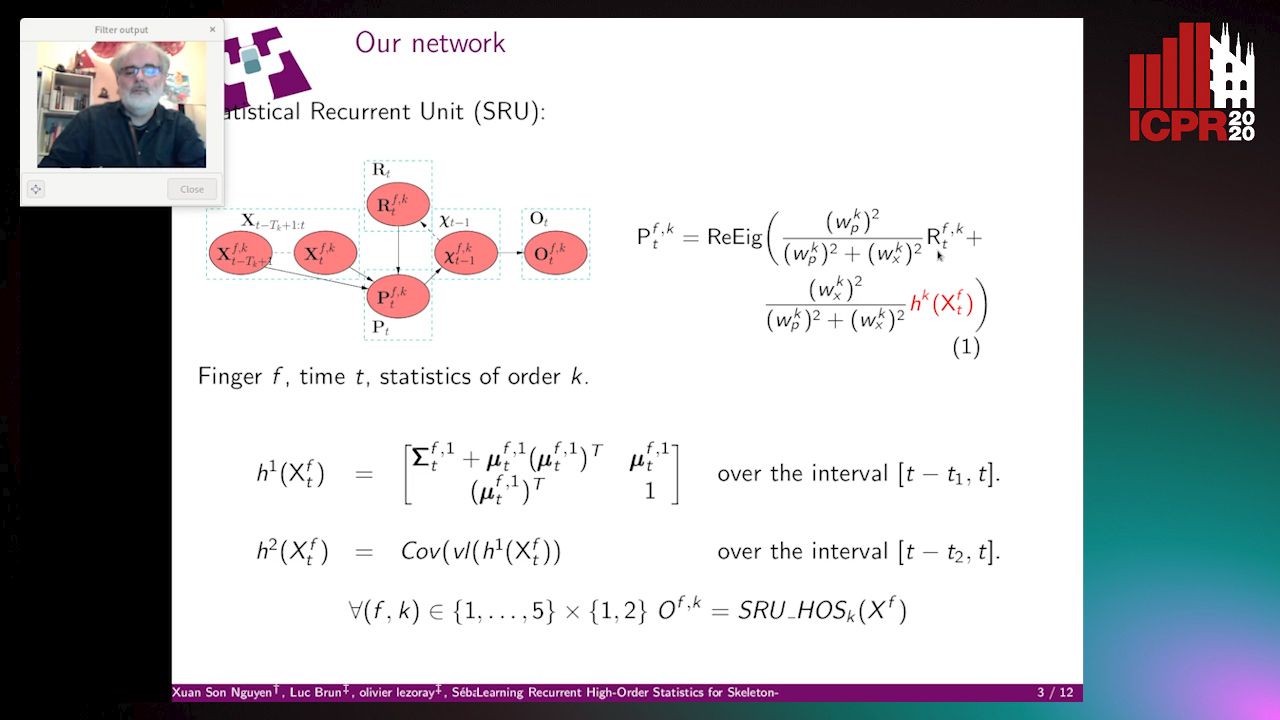
Auto-TLDR; Exploiting High-Order Statistics in Recurrent Neural Networks for Hand Gesture Recog-nition
Learnable Higher-Order Representation for Action Recognition

Auto-TLDR; Learningable Higher-Order Operations for Spatiotemporal Dynamics in Video Recognition
MFI: Multi-Range Feature Interchange for Video Action Recognition
Sikai Bai, Qi Wang, Xuelong Li

Auto-TLDR; Multi-range Feature Interchange Network for Action Recognition in Videos
Abstract Slides Poster Similar
TreeRNN: Topology-Preserving Deep Graph Embedding and Learning
Yecheng Lyu, Ming Li, Xinming Huang, Ulkuhan Guler, Patrick Schaumont, Ziming Zhang

Auto-TLDR; TreeRNN: Recurrent Neural Network for General Graph Classification
Abstract Slides Poster Similar
Attention-Driven Body Pose Encoding for Human Activity Recognition
Bappaditya Debnath, Swagat Kumar, Marry O'Brien, Ardhendu Behera

Auto-TLDR; Attention-based Body Pose Encoding for Human Activity Recognition
Abstract Slides Poster Similar
More Correlations Better Performance: Fully Associative Networks for Multi-Label Image Classification

Auto-TLDR; Fully Associative Network for Fully Exploiting Correlation Information in Multi-Label Classification
Abstract Slides Poster Similar
Signature Features with the Visibility Transformation
Yue Wu, Hao Ni, Terry Lyons, Robin Hudson

Auto-TLDR; The Visibility Transformation for Pattern Recognition
Abstract Slides Poster Similar
Directional Graph Networks with Hard Weight Assignments
Miguel Dominguez, Raymond Ptucha

Auto-TLDR; Hard Directional Graph Networks for Point Cloud Analysis
Abstract Slides Poster Similar
Graph-Based Interpolation of Feature Vectors for Accurate Few-Shot Classification
Yuqing Hu, Vincent Gripon, Stéphane Pateux

Auto-TLDR; Transductive Learning for Few-Shot Classification using Graph Neural Networks
Abstract Slides Poster Similar
Multi-Graph Convolutional Network for Relationship-Driven Stock Movement Prediction
Jiexia Ye, Juanjuan Zhao, Kejiang Ye, Cheng-Zhong Xu

Auto-TLDR; Multi-GCGRU: A Deep Learning Framework for Stock Price Prediction with Cross Effect
Abstract Slides Poster Similar
What Nodes Vote To? Graph Classification without Readout Phase
Yuxing Tian, Zheng Liu, Weiding Liu, Zeyu Zhang, Yanwen Qu

Auto-TLDR; node voting based graph classification with convolutional operator
Abstract Slides Poster Similar
Boundary-Aware Graph Convolution for Semantic Segmentation
Hanzhe Hu, Jinshi Cui, Jinshi Hongbin Zha

Auto-TLDR; Boundary-Aware Graph Convolution for Semantic Segmentation
Abstract Slides Poster Similar
Attention-Oriented Action Recognition for Real-Time Human-Robot Interaction
Ziyang Song, Ziyi Yin, Zejian Yuan, Chong Zhang, Wanchao Chi, Yonggen Ling, Shenghao Zhang

Auto-TLDR; Attention-Oriented Multi-Level Network for Action Recognition in Interaction Scenes
Abstract Slides Poster Similar
G-FAN: Graph-Based Feature Aggregation Network for Video Face Recognition
He Zhao, Yongjie Shi, Xin Tong, Jingsi Wen, Xianghua Ying, Jinshi Hongbin Zha

Auto-TLDR; Graph-based Feature Aggregation Network for Video Face Recognition
Abstract Slides Poster Similar
A Multi-Task Neural Network for Action Recognition with 3D Key-Points
Rongxiao Tang, Wang Luyang, Zhenhua Guo

Auto-TLDR; Multi-task Neural Network for Action Recognition and 3D Human Pose Estimation
Abstract Slides Poster Similar
SL-DML: Signal Level Deep Metric Learning for Multimodal One-Shot Action Recognition
Raphael Memmesheimer, Nick Theisen, Dietrich Paulus

Auto-TLDR; One-Shot Action Recognition using Metric Learning
GraphBGS: Background Subtraction Via Recovery of Graph Signals
Jhony Heriberto Giraldo Zuluaga, Thierry Bouwmans

Auto-TLDR; Graph BackGround Subtraction using Graph Signals
Abstract Slides Poster Similar
Vision-Based Multi-Modal Framework for Action Recognition
Djamila Romaissa Beddiar, Mourad Oussalah, Brahim Nini

Auto-TLDR; Multi-modal Framework for Human Activity Recognition Using RGB, Depth and Skeleton Data
Abstract Slides Poster Similar
Learning Group Activities from Skeletons without Individual Action Labels
Fabio Zappardino, Tiberio Uricchio, Lorenzo Seidenari, Alberto Del Bimbo

Auto-TLDR; Lean Pose Only for Group Activity Recognition
Soft Label and Discriminant Embedding Estimation for Semi-Supervised Classification
Fadi Dornaika, Abdullah Baradaaji, Youssof El Traboulsi

Auto-TLDR; Semi-supervised Semi-Supervised Learning for Linear Feature Extraction and Label Propagation
Abstract Slides Poster Similar
2D Deep Video Capsule Network with Temporal Shift for Action Recognition
Théo Voillemin, Hazem Wannous, Jean-Philippe Vandeborre

Auto-TLDR; Temporal Shift Module over Capsule Network for Action Recognition in Continuous Videos
Single View Learning in Action Recognition
Gaurvi Goyal, Nicoletta Noceti, Francesca Odone

Auto-TLDR; Cross-View Action Recognition Using Domain Adaptation for Knowledge Transfer
Abstract Slides Poster Similar
Siamese Graph Convolution Network for Face Sketch Recognition
Liang Fan, Xianfang Sun, Paul Rosin

Auto-TLDR; A novel Siamese graph convolution network for face sketch recognition
Abstract Slides Poster Similar
Trainable Spectrally Initializable Matrix Transformations in Convolutional Neural Networks
Michele Alberti, Angela Botros, Schuetz Narayan, Rolf Ingold, Marcus Liwicki, Mathias Seuret

Auto-TLDR; Trainable and Spectrally Initializable Matrix Transformations for Neural Networks
Abstract Slides Poster Similar
Context for Object Detection Via Lightweight Global and Mid-Level Representations
Mesut Erhan Unal, Adriana Kovashka

Auto-TLDR; Context-Based Object Detection with Semantic Similarity
Abstract Slides Poster Similar