Multi-Modal Identification of State-Sponsored Propaganda on Social Media

Auto-TLDR; A balanced dataset for detecting state-sponsored Internet propaganda
Similar papers
Assessing the Severity of Health States Based on Social Media Posts
Shweta Yadav, Joy Prakash Sain, Amit Sheth, Asif Ekbal, Sriparna Saha, Pushpak Bhattacharyya

Auto-TLDR; A Multiview Learning Framework for Assessment of Health State in Online Health Communities
Abstract Slides Poster Similar
Information Graphic Summarization Using a Collection of Multimodal Deep Neural Networks
Edward Kim, Connor Onweller, Kathleen F. Mccoy

Auto-TLDR; A multimodal deep learning framework that can generate summarization text supporting the main idea of an information graphic for presentation to blind or visually impaired
Enriching Video Captions with Contextual Text
Philipp Rimle, Pelin Dogan, Markus Gross

Auto-TLDR; Contextualized Video Captioning Using Contextual Text
Abstract Slides Poster Similar
A Novel Disaster Image Data-Set and Characteristics Analysis Using Attention Model
Fahim Faisal Niloy, Arif ., Abu Bakar Siddik Nayem, Anis Sarker, Ovi Paul, M Ashraful Amin, Amin Ahsan Ali, Moinul Islam Zaber, Akmmahbubur Rahman

Auto-TLDR; Attentive Attention Model for Disaster Classification
Abstract Slides Poster Similar
Documents Counterfeit Detection through a Deep Learning Approach
Darwin Danilo Saire Pilco, Salvatore Tabbone

Auto-TLDR; End-to-End Learning for Counterfeit Documents Detection using Deep Neural Network
Abstract Slides Poster Similar
Segmenting Messy Text: Detecting Boundaries in Text Derived from Historical Newspaper Images

Auto-TLDR; Text Segmentation of Marriage Announcements Using Deep Learning-based Models
Abstract Slides Poster Similar
Dual Path Multi-Modal High-Order Features for Textual Content Based Visual Question Answering
Yanan Li, Yuetan Lin, Hongrui Zhao, Donghui Wang

Auto-TLDR; TextVQA: An End-to-End Visual Question Answering Model for Text-Based VQA
MEG: Multi-Evidence GNN for Multimodal Semantic Forensics
Ekraam Sabir, Ayush Jaiswal, Wael Abdalmageed, Prem Natarajan

Auto-TLDR; Scalable Image Repurposing Detection with Graph Neural Network Based Model
Abstract Slides Poster Similar
KoreALBERT: Pretraining a Lite BERT Model for Korean Language Understanding
Hyunjae Lee, Jaewoong Yun, Bongkyu Hwang, Seongho Joe, Seungjai Min, Youngjune Gwon

Auto-TLDR; KoreALBERT: A monolingual ALBERT model for Korean language understanding
Abstract Slides Poster Similar
PIN: A Novel Parallel Interactive Network for Spoken Language Understanding
Peilin Zhou, Zhiqi Huang, Fenglin Liu, Yuexian Zou

Auto-TLDR; Parallel Interactive Network for Spoken Language Understanding
Abstract Slides Poster Similar
Zero-Shot Text Classification with Semantically Extended Graph Convolutional Network
Tengfei Liu, Yongli Hu, Junbin Gao, Yanfeng Sun, Baocai Yin

Auto-TLDR; Semantically Extended Graph Convolutional Network for Zero-shot Text Classification
Abstract Slides Poster Similar
Cross-Lingual Text Image Recognition Via Multi-Task Sequence to Sequence Learning
Zhuo Chen, Fei Yin, Xu-Yao Zhang, Qing Yang, Cheng-Lin Liu

Auto-TLDR; Cross-Lingual Text Image Recognition with Multi-task Learning
Abstract Slides Poster Similar
Video Episode Boundary Detection with Joint Episode-Topic Model
Shunyao Wang, Ye Tian, Ruidong Wang, Yang Du, Han Yan, Ruilin Yang, Jian Ma

Auto-TLDR; Unsupervised Video Episode Boundary Detection for Bullet Screen Comment Video
Abstract Slides Poster Similar
A Novel Attention-Based Aggregation Function to Combine Vision and Language
Matteo Stefanini, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara

Auto-TLDR; Fully-Attentive Reduction for Vision and Language
Abstract Slides Poster Similar
Text Synopsis Generation for Egocentric Videos
Aidean Sharghi, Niels Lobo, Mubarak Shah

Auto-TLDR; Egocentric Video Summarization Using Multi-task Learning for End-to-End Learning
Text Recognition - Real World Data and Where to Find Them
Klára Janoušková, Lluis Gomez, Dimosthenis Karatzas, Jiri Matas

Auto-TLDR; Exploiting Weakly Annotated Images for Text Extraction
Abstract Slides Poster Similar
Video Face Manipulation Detection through Ensemble of CNNs
Nicolo Bonettini, Edoardo Daniele Cannas, Sara Mandelli, Luca Bondi, Paolo Bestagini, Stefano Tubaro

Auto-TLDR; Face Manipulation Detection in Video Sequences Using Convolutional Neural Networks
Malware Detection by Exploiting Deep Learning over Binary Programs
Panpan Qi, Zhaoqi Zhang, Wei Wang, Chang Yao

Auto-TLDR; End-to-End Malware Detection without Feature Engineering
Abstract Slides Poster Similar
Context Matters: Self-Attention for Sign Language Recognition
Fares Ben Slimane, Mohamed Bouguessa

Auto-TLDR; Attentional Network for Continuous Sign Language Recognition
Abstract Slides Poster Similar
MAGNet: Multi-Region Attention-Assisted Grounding of Natural Language Queries at Phrase Level
Amar Shrestha, Krittaphat Pugdeethosapol, Haowen Fang, Qinru Qiu

Auto-TLDR; MAGNet: A Multi-Region Attention-Aware Grounding Network for Free-form Textual Queries
Abstract Slides Poster Similar
Multimodal Side-Tuning for Document Classification
Stefano Zingaro, Giuseppe Lisanti, Maurizio Gabbrielli

Auto-TLDR; Side-tuning for Multimodal Document Classification
Abstract Slides Poster Similar
Transformer Reasoning Network for Image-Text Matching and Retrieval
Nicola Messina, Fabrizio Falchi, Andrea Esuli, Giuseppe Amato

Auto-TLDR; A Transformer Encoder Reasoning Network for Image-Text Matching in Large-Scale Information Retrieval
Abstract Slides Poster Similar
PICK: Processing Key Information Extraction from Documents Using Improved Graph Learning-Convolutional Networks
Wenwen Yu, Ning Lu, Xianbiao Qi, Ping Gong, Rong Xiao

Auto-TLDR; PICK: A Graph Learning Framework for Key Information Extraction from Documents
Abstract Slides Poster Similar
Mood Detection Analyzing Lyrics and Audio Signal Based on Deep Learning Architectures
Konstantinos Pyrovolakis, Paraskevi Tzouveli, Giorgos Stamou

Auto-TLDR; Automated Music Mood Detection using Music Information Retrieval
Abstract Slides Poster Similar
Attention Pyramid Module for Scene Recognition
Zhinan Qiao, Xiaohui Yuan, Chengyuan Zhuang, Abolfazl Meyarian

Auto-TLDR; Attention Pyramid Module for Multi-Scale Scene Recognition
Abstract Slides Poster Similar
Evaluation of BERT and ALBERT Sentence Embedding Performance on Downstream NLP Tasks
Hyunjin Choi, Judong Kim, Seongho Joe, Youngjune Gwon

Auto-TLDR; Sentence Embedding Models for BERT and ALBERT: A Comparison and Evaluation
Abstract Slides Poster Similar
Fine-Tuning Convolutional Neural Networks: A Comprehensive Guide and Benchmark Analysis for Glaucoma Screening
Amed Mvoulana, Rostom Kachouri, Mohamed Akil

Auto-TLDR; Fine-tuning Convolutional Neural Networks for Glaucoma Screening
Abstract Slides Poster Similar
The Color Out of Space: Learning Self-Supervised Representations for Earth Observation Imagery
Stefano Vincenzi, Angelo Porrello, Pietro Buzzega, Marco Cipriano, Pietro Fronte, Roberto Cuccu, Carla Ippoliti, Annamaria Conte, Simone Calderara

Auto-TLDR; Satellite Image Representation Learning for Remote Sensing
Abstract Slides Poster Similar
GCNs-Based Context-Aware Short Text Similarity Model

Auto-TLDR; Context-Aware Graph Convolutional Network for Text Similarity
Abstract Slides Poster Similar
Adversarial Training for Aspect-Based Sentiment Analysis with BERT
Akbar Karimi, Andrea Prati, Leonardo Rossi

Auto-TLDR; Adversarial Training of BERT for Aspect-Based Sentiment Analysis
Abstract Slides Poster Similar
Multi-Modal Contextual Graph Neural Network for Text Visual Question Answering
Yaoyuan Liang, Xin Wang, Xuguang Duan, Wenwu Zhu

Auto-TLDR; Multi-modal Contextual Graph Neural Network for Text Visual Question Answering
Abstract Slides Poster Similar
Recognizing American Sign Language Nonmanual Signal Grammar Errors in Continuous Videos
Elahe Vahdani, Longlong Jing, Ying-Li Tian, Matt Huenerfauth

Auto-TLDR; ASL-HW-RGBD: Recognizing Grammatical Errors in Continuous Sign Language
Abstract Slides Poster Similar
Cross-Media Hash Retrieval Using Multi-head Attention Network
Zhixin Li, Feng Ling, Chuansheng Xu, Canlong Zhang, Huifang Ma

Auto-TLDR; Unsupervised Cross-Media Hash Retrieval Using Multi-Head Attention Network
Abstract Slides Poster Similar
Privacy Attributes-Aware Message Passing Neural Network for Visual Privacy Attributes Classification
Hanbin Hong, Wentao Bao, Yuan Hong, Yu Kong

Auto-TLDR; Privacy Attributes-Aware Message Passing Neural Network for Visual Privacy Attribute Classification
Abstract Slides Poster Similar
End-To-End Multi-Task Learning for Lung Nodule Segmentation and Diagnosis
Wei Chen, Qiuli Wang, Dan Yang, Xiaohong Zhang, Chen Liu, Yucong Li

Auto-TLDR; A novel multi-task framework for lung nodule diagnosis based on deep learning and medical features
Context Visual Information-Based Deliberation Network for Video Captioning
Min Lu, Xueyong Li, Caihua Liu

Auto-TLDR; Context visual information-based deliberation network for video captioning
Abstract Slides Poster Similar
An Experimental Evaluation of Recent Face Recognition Losses for Deepfake Detection
Yu-Cheng Liu, Chia-Ming Chang, I-Hsuan Chen, Yu Ju Ku, Jun-Cheng Chen

Auto-TLDR; Deepfake Classification and Detection using Loss Functions for Face Recognition
Abstract Slides Poster Similar
Inception Based Deep Learning Architecture for Tuberculosis Screening of Chest X-Rays
Dipayan Das, K.C. Santosh, Umapada Pal

Auto-TLDR; End to End CNN-based Chest X-ray Screening for Tuberculosis positive patients in the severely resource constrained regions of the world
Abstract Slides Poster Similar
End-To-End Deep Learning Methods for Automated Damage Detection in Extreme Events at Various Scales
Yongsheng Bai, Alper Yilmaz, Halil Sezen

Auto-TLDR; Robust Mask R-CNN for Crack Detection in Extreme Events
Abstract Slides Poster Similar
Label or Message: A Large-Scale Experimental Survey of Texts and Objects Co-Occurrence
Koki Takeshita, Juntaro Shioyama, Seiichi Uchida

Auto-TLDR; Large-scale Survey of Co-occurrence between Objects and Scene Text with a State-of-the-art Scene Text detector and Recognizer
Continuous Sign Language Recognition with Iterative Spatiotemporal Fine-Tuning
Kenessary Koishybay, Medet Mukushev, Anara Sandygulova

Auto-TLDR; A Deep Neural Network for Continuous Sign Language Recognition with Iterative Gloss Recognition
Abstract Slides Poster Similar
Learning Neural Textual Representations for Citation Recommendation
Thanh Binh Kieu, Inigo Jauregi Unanue, Son Bao Pham, Xuan-Hieu Phan, M. Piccardi

Auto-TLDR; Sentence-BERT cascaded with Siamese and triplet networks for citation recommendation
Abstract Slides Poster Similar
Hierarchical Multimodal Attention for Deep Video Summarization
Melissa Sanabria, Frederic Precioso, Thomas Menguy

Auto-TLDR; Automatic Summarization of Professional Soccer Matches Using Event-Stream Data and Multi- Instance Learning
Abstract Slides Poster Similar
A Versatile Crack Inspection Portable System Based on Classifier Ensemble and Controlled Illumination
Milind Gajanan Padalkar, Carlos Beltran-Gonzalez, Matteo Bustreo, Alessio Del Bue, Vittorio Murino

Auto-TLDR; Lighting Conditions for Crack Detection in Ceramic Tile
Abstract Slides Poster Similar
Wireless Localisation in WiFi Using Novel Deep Architectures
Peizheng Li, Han Cui, Aftab Khan, Usman Raza, Robert Piechocki, Angela Doufexi, Tim Farnham

Auto-TLDR; Deep Neural Network for Indoor Localisation of WiFi Devices in Indoor Environments
Abstract Slides Poster Similar
Deep Multiple Instance Learning with Spatial Attention for ROP Case Classification, Instance Selection and Abnormality Localization
Xirong Li, Wencui Wan, Yang Zhou, Jianchun Zhao, Qijie Wei, Junbo Rong, Pengyi Zhou, Limin Xu, Lijuan Lang, Yuying Liu, Chengzhi Niu, Dayong Ding, Xuemin Jin

Auto-TLDR; MIL-SA: Deep Multiple Instance Learning for Automated Screening of Retinopathy of Prematurity
Deep Convolutional Embedding for Digitized Painting Clustering
Giovanna Castellano, Gennaro Vessio

Auto-TLDR; A Deep Convolutional Embedding Model for Clustering Artworks
Abstract Slides Poster Similar
RWMF: A Real-World Multimodal Foodlog Database
Pengfei Zhou, Cong Bai, Kaining Ying, Jie Xia, Lixin Huang
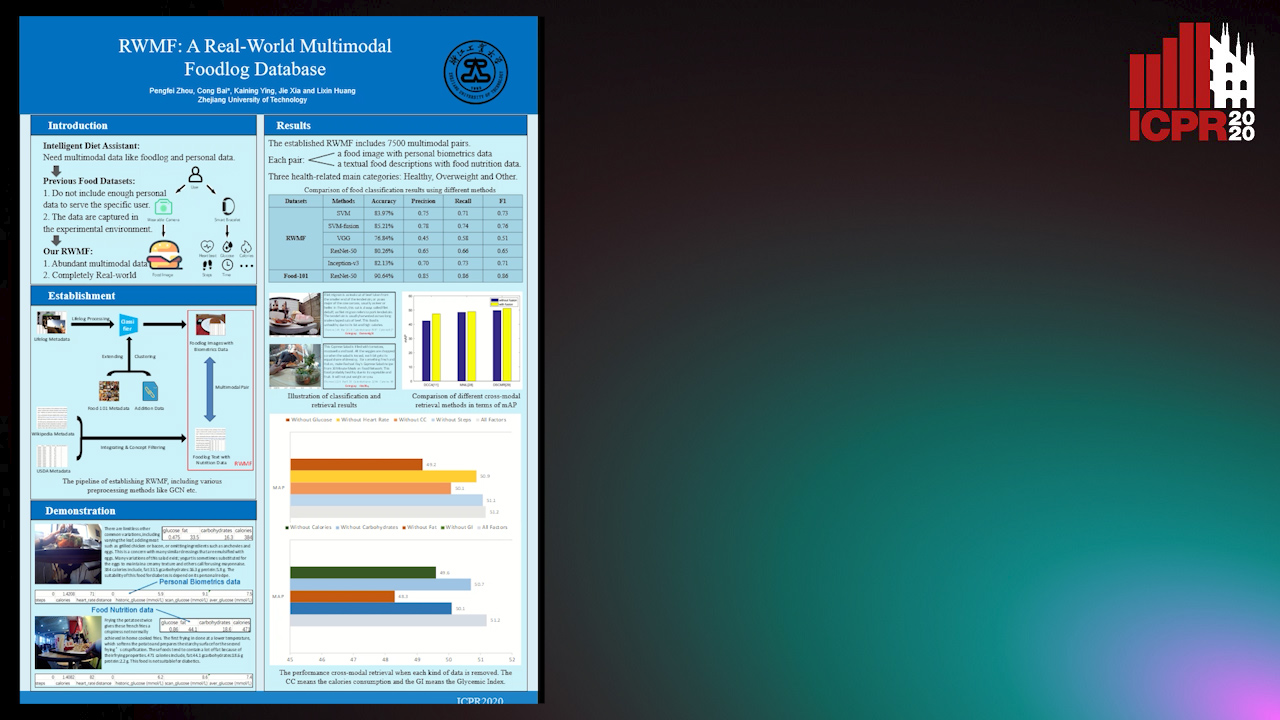
Auto-TLDR; Real-World Multimodal Foodlog: A Real-World Foodlog Database for Diet Assistant
Abstract Slides Poster Similar