Improved Time-Series Clustering with UMAP Dimension Reduction Method
Clément Pealat,
Vincent Cheutet,
Guillaume Bouleux

Auto-TLDR; Time Series Clustering with UMAP as a Pre-processing Step
Similar papers
N2D: (Not Too) Deep Clustering Via Clustering the Local Manifold of an Autoencoded Embedding
Ryan Mcconville, Raul Santos-Rodriguez, Robert Piechocki, Ian Craddock

Auto-TLDR; Local Manifold Learning for Deep Clustering on Autoencoded Embeddings
An Invariance-Guided Stability Criterion for Time Series Clustering Validation
Florent Forest, Alex Mourer, Mustapha Lebbah, Hanane Azzag, Jérôme Lacaille

Auto-TLDR; An invariance-guided method for clustering model selection in time series data
Abstract Slides Poster Similar
Detecting Rare Cell Populations in Flow Cytometry Data Using UMAP
Lisa Weijler, Markus Diem, Michael Reiter

Auto-TLDR; Unsupervised Manifold Approximation and Projection for Small Cell Population Detection in Flow cytometry Data
Abstract Slides Poster Similar
Probabilistic Word Embeddings in Kinematic Space
Adarsh Jamadandi, Rishabh Tigadoli, Ramesh Ashok Tabib, Uma Mudenagudi

Auto-TLDR; Kinematic Space for Hierarchical Representation Learning
Abstract Slides Poster Similar
Q-SNE: Visualizing Data Using Q-Gaussian Distributed Stochastic Neighbor Embedding
Motoshi Abe, Junichi Miyao, Takio Kurita

Auto-TLDR; Q-Gaussian distributed stochastic neighbor embedding for 2-dimensional mapping and classification
Abstract Slides Poster Similar
Graph Approximations to Geodesics on Metric Graphs
Robin Vandaele, Yvan Saeys, Tijl De Bie

Auto-TLDR; Topological Pattern Recognition of Metric Graphs Using Proximity Graphs
Abstract Slides Poster Similar
Encoding Brain Networks through Geodesic Clustering of Functional Connectivity for Multiple Sclerosis Classification
Muhammad Abubakar Yamin, Valsasina Paola, Michael Dayan, Sebastiano Vascon, Tessadori Jacopo, Filippi Massimo, Vittorio Murino, A Rocca Maria, Diego Sona

Auto-TLDR; Geodesic Clustering of Connectivity Matrices for Multiple Sclerosis Classification
Abstract Slides Poster Similar
A Multi-Task Multi-View Based Multi-Objective Clustering Algorithm

Auto-TLDR; MTMV-MO: Multi-task multi-view multi-objective optimization for multi-task clustering
Abstract Slides Poster Similar
One Step Clustering Based on A-Contrario Framework for Detection of Alterations in Historical Violins
Alireza Rezaei, Sylvie Le Hégarat-Mascle, Emanuel Aldea, Piercarlo Dondi, Marco Malagodi

Auto-TLDR; A-Contrario Clustering for the Detection of Altered Violins using UVIFL Images
Abstract Slides Poster Similar
Automatic Estimation of Self-Reported Pain by Interpretable Representations of Motion Dynamics
Benjamin Szczapa, Mohammed Daoudi, Stefano Berretti, Pietro Pala, Zakia Hammal, Alberto Del Bimbo

Auto-TLDR; Automatic Pain Intensity Measurement from Facial Points Using Gram Matrices
Abstract Slides Poster Similar
A Framework for Local Outlier Detection from Spatio-Temporal Trajectory Datasets
Xumin Cai, Berkay Aydin, Anli Ji, Rafal Angryk

Auto-TLDR; Local Outlier Detection Using Spatial and Temporal Features of Trajectory Segment Using Time-Based partition strategy
Sketch-Based Community Detection Via Representative Node Sampling
Mahlagha Sedghi, Andre Beckus, George Atia

Auto-TLDR; Sketch-based Clustering of Community Detection Using a Small Sketch
Abstract Slides Poster Similar
Uniform and Non-Uniform Sampling Methods for Sub-Linear Time K-Means Clustering

Auto-TLDR; Sub-linear Time Clustering with Constant Approximation Ratio for K-Means Problem
Abstract Slides Poster Similar
Deep Convolutional Embedding for Digitized Painting Clustering
Giovanna Castellano, Gennaro Vessio

Auto-TLDR; A Deep Convolutional Embedding Model for Clustering Artworks
Abstract Slides Poster Similar
A Hybrid Metric Based on Persistent Homology and Its Application to Signal Classification
Austin Lawson, Yu-Min Chung, William Cruse

Auto-TLDR; Topological Data Analysis with Persistence Curves
3D Facial Matching by Spiral Convolutional Metric Learning and a Biometric Fusion-Net of Demographic Properties
Soha Sadat Mahdi, Nele Nauwelaers, Philip Joris, Giorgos Bouritsas, Imperial London, Sergiy Bokhnyak, Susan Walsh, Mark Shriver, Michael Bronstein, Peter Claes

Auto-TLDR; Multi-biometric Fusion for Biometric Verification using 3D Facial Mesures
Nonlinear Ranking Loss on Riemannian Potato Embedding
Byung Hyung Kim, Yoonje Suh, Honggu Lee, Sungho Jo

Auto-TLDR; Riemannian Potato for Rank-based Metric Learning
Abstract Slides Poster Similar
Stochastic Runge-Kutta Methods and Adaptive SGD-G2 Stochastic Gradient Descent

Auto-TLDR; Adaptive Stochastic Runge Kutta for the Minimization of the Loss Function
Abstract Slides Poster Similar
ClusterFace: Joint Clustering and Classification for Set-Based Face Recognition
Samadhi Poornima Kumarasinghe Wickrama Arachchilage, Ebroul Izquierdo

Auto-TLDR; Joint Clustering and Classification for Face Recognition in the Wild
Abstract Slides Poster Similar
Classification and Feature Selection Using a Primal-Dual Method and Projections on Structured Constraints
Michel Barlaud, Antonin Chambolle, Jean_Baptiste Caillau

Auto-TLDR; A Constrained Primal-dual Method for Structured Feature Selection on High Dimensional Data
Abstract Slides Poster Similar
Dimensionality Reduction for Data Visualization and Linear Classification, and the Trade-Off between Robustness and Classification Accuracy
Martin Becker, Jens Lippel, Thomas Zielke

Auto-TLDR; Robustness Assessment of Deep Autoencoder for Data Visualization using Scatter Plots
Abstract Slides Poster Similar
Graph Spectral Feature Learning for Mixed Data of Categorical and Numerical Type
Saswata Sahoo, Souradip Chakraborty

Auto-TLDR; Feature Learning in Mixed Type of Variable by an undirected graph
Abstract Slides Poster Similar
Aggregating Dependent Gaussian Experts in Local Approximation

Auto-TLDR; A novel approach for aggregating the Gaussian experts by detecting strong violations of conditional independence
Abstract Slides Poster Similar
Temporal Pattern Detection in Time-Varying Graphical Models
Federico Tomasi, Veronica Tozzo, Annalisa Barla

Auto-TLDR; A dynamical network inference model that leverages on kernels to consider general temporal patterns
Abstract Slides Poster Similar
Comparison of Stacking-Based Classifier Ensembles Using Euclidean and Riemannian Geometries
Vitaliy Tayanov, Adam Krzyzak, Ching Y Suen

Auto-TLDR; Classifier Stacking in Riemannian Geometries using Cascades of Random Forest and Extra Trees
Abstract Slides Poster Similar
A Spectral Clustering on Grassmann Manifold Via Double Low Rank Constraint
Xinglin Piao, Yongli Hu, Junbin Gao, Yanfeng Sun, Xin Yang, Baocai Yin

Auto-TLDR; Double Low Rank Representation for High-Dimensional Data Clustering on Grassmann Manifold
Partial Monotone Dependence
Denis Khryashchev, Huy Vo, Robert Haralick

Auto-TLDR; Partially Monotone Autoregressive Correlation for Time Series Forecasting
Low Rank Representation on Product Grassmann Manifolds for Multi-viewSubspace Clustering
Jipeng Guo, Yanfeng Sun, Junbin Gao, Yongli Hu, Baocai Yin

Auto-TLDR; Low Rank Representation on Product Grassmann Manifold for Multi-View Data Clustering
Abstract Slides Poster Similar
Wasserstein k-Means with Sparse Simplex Projection
Takumi Fukunaga, Hiroyuki Kasai

Auto-TLDR; SSPW $k$-means: Sparse Simplex Projection-based Wasserstein $ k$-Means Algorithm
Abstract Slides Poster Similar
Location Prediction in Real Homes of Older Adults based on K-Means in Low-Resolution Depth Videos
Simon Simonsson, Flávia Dias Casagrande, Evi Zouganeli

Auto-TLDR; Semi-supervised Learning for Location Recognition and Prediction in Smart Homes using Depth Video Cameras
Abstract Slides Poster Similar
PIF: Anomaly detection via preference embedding
Filippo Leveni, Luca Magri, Giacomo Boracchi, Cesare Alippi

Auto-TLDR; PIF: Anomaly Detection with Preference Embedding for Structured Patterns
Abstract Slides Poster Similar
On Learning Random Forests for Random Forest Clustering
Manuele Bicego, Francisco Escolano

Auto-TLDR; Learning Random Forests for Clustering
Abstract Slides Poster Similar
Local Binary Quaternion Rotation Pattern for Colour Texture Retrieval
Hela Jebali, Noel Richard, Mohamed Naouai
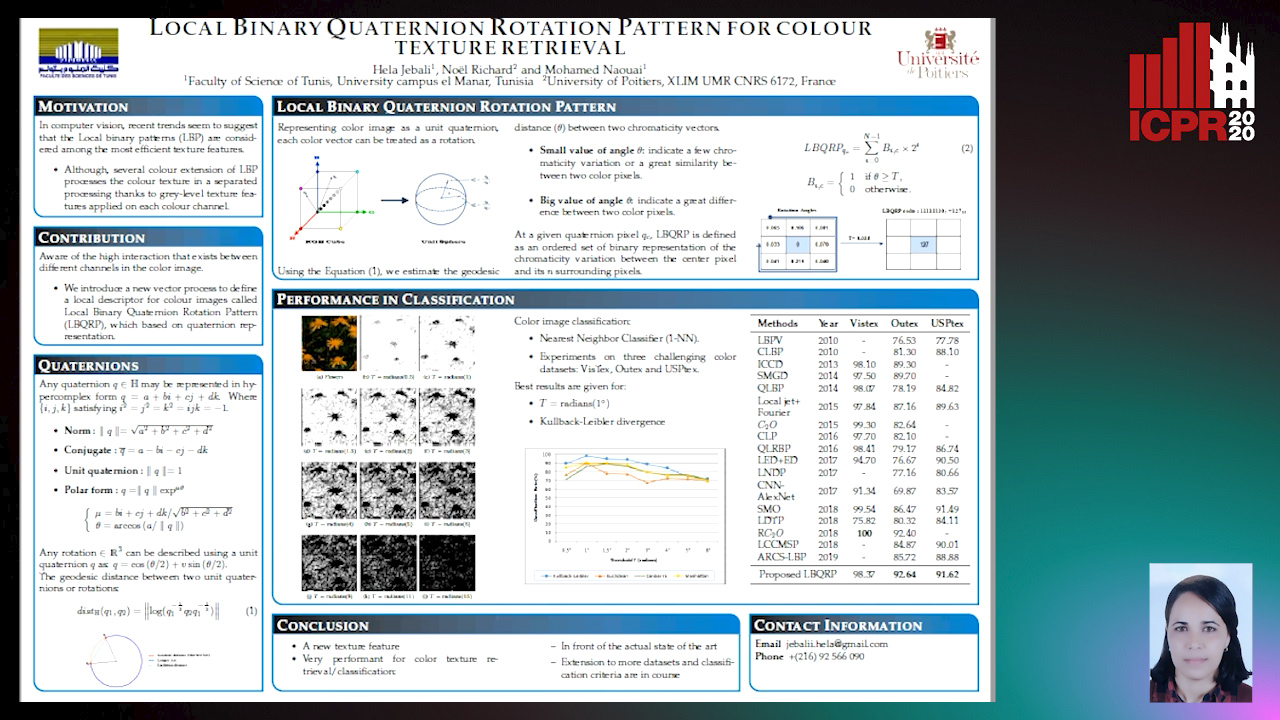
Auto-TLDR; Local Binary Quaternion Rotation Pattern for Color Texture Classification
SSDL: Self-Supervised Domain Learning for Improved Face Recognition
Samadhi Poornima Kumarasinghe Wickrama Arachchilage, Ebroul Izquierdo

Auto-TLDR; Self-supervised Domain Learning for Face Recognition in unconstrained environments
Abstract Slides Poster Similar
Penalized K-Means Algorithms for Finding the Number of Clusters
Behzad Kamgar-Parsi, Behrooz Kamgar-Parsi

Auto-TLDR; Exploring the coefficient of additive penalty in k-means for ideal clusters
Abstract Slides Poster Similar
3CS Algorithm for Efficient Gaussian Process Model Retrieval
Fabian Berns, Kjeld Schmidt, Ingolf Bracht, Christian Beecks

Auto-TLDR; Efficient retrieval of Gaussian Process Models for large-scale data using divide-&-conquer-based approach
Abstract Slides Poster Similar
Soft Label and Discriminant Embedding Estimation for Semi-Supervised Classification
Fadi Dornaika, Abdullah Baradaaji, Youssof El Traboulsi

Auto-TLDR; Semi-supervised Semi-Supervised Learning for Linear Feature Extraction and Label Propagation
Abstract Slides Poster Similar
Learning Embeddings for Image Clustering: An Empirical Study of Triplet Loss Approaches
Kalun Ho, Janis Keuper, Franz-Josef Pfreundt, Margret Keuper

Auto-TLDR; Clustering Objectives for K-means and Correlation Clustering Using Triplet Loss
Abstract Slides Poster Similar
Evaluation of Anomaly Detection Algorithms for the Real-World Applications
Marija Ivanovska, Domen Tabernik, Danijel Skocaj, Janez Pers

Auto-TLDR; Evaluating Anomaly Detection Algorithms for Practical Applications
Abstract Slides Poster Similar
A Novel Random Forest Dissimilarity Measure for Multi-View Learning
Hongliu Cao, Simon Bernard, Robert Sabourin, Laurent Heutte

Auto-TLDR; Multi-view Learning with Random Forest Relation Measure and Instance Hardness
Abstract Slides Poster Similar
Motion Segmentation with Pairwise Matches and Unknown Number of Motions
Federica Arrigoni, Tomas Pajdla, Luca Magri

Auto-TLDR; Motion Segmentation using Multi-Modelfitting andpermutation synchronization
Abstract Slides Poster Similar
Dependently Coupled Principal Component Analysis for Bivariate Inversion Problems
Navdeep Dahiya, Yifei Fan, Samuel Bignardi, Tony Yezzi, Romeil Sandhu

Auto-TLDR; Asymmetric Principal Component Analysis between Paired Data in an Asymmetric manner
Abstract Slides Poster Similar
Detecting Manipulated Facial Videos: A Time Series Solution
Zhang Zhewei, Ma Can, Gao Meilin, Ding Bowen

Auto-TLDR; Face-Alignment Based Bi-LSTM for Fake Video Detection
Abstract Slides Poster Similar
Interactive Style Space of Deep Features and Style Innovation

Auto-TLDR; Interactive Style Space of Convolutional Neural Network Features
Abstract Slides Poster Similar
Seasonal Inhomogeneous Nonconsecutive Arrival Process Search and Evaluation
Kimberly Holmgren, Paul Gibby, Joseph Zipkin

Auto-TLDR; SINAPSE: Fitting a Sparse Time Series Model to Seasonal Data
Abstract Slides Poster Similar
Mean Decision Rules Method with Smart Sampling for Fast Large-Scale Binary SVM Classification
Alexandra Makarova, Mikhail Kurbakov, Valentina Sulimova

Auto-TLDR; Improving Mean Decision Rule for Large-Scale Binary SVM Problems
Abstract Slides Poster Similar
Subspace Clustering for Action Recognition with Covariance Representations and Temporal Pruning
Giancarlo Paoletti, Jacopo Cavazza, Cigdem Beyan, Alessio Del Bue

Auto-TLDR; Unsupervised Learning for Human Action Recognition from Skeletal Data
Efficient Sentence Embedding Via Semantic Subspace Analysis
Bin Wang, Fenxiao Chen, Yun Cheng Wang, C.-C. Jay Kuo

Auto-TLDR; S3E: Semantic Subspace Sentence Embedding
Abstract Slides Poster Similar