Automatic Estimation of Self-Reported Pain by Interpretable Representations of Motion Dynamics
Benjamin Szczapa,
Mohammed Daoudi,
Stefano Berretti,
Pietro Pala,
Zakia Hammal,
Alberto Del Bimbo

Auto-TLDR; Automatic Pain Intensity Measurement from Facial Points Using Gram Matrices
Similar papers
Quantified Facial Temporal-Expressiveness Dynamics for Affect Analysis
Md Taufeeq Uddin, Shaun Canavan

Auto-TLDR; quantified facial Temporal-expressiveness Dynamics for quantified affect analysis
Sequential Non-Rigid Factorisation for Head Pose Estimation
Stefania Cristina, Kenneth Patrick Camilleri

Auto-TLDR; Sequential Shape-and-Motion Factorisation for Head Pose Estimation in Eye-Gaze Tracking
Abstract Slides Poster Similar
Interpretable Emotion Classification Using Temporal Convolutional Models
Manasi Bharat Gund, Abhiram Ravi Bharadwaj, Ifeoma Nwogu

Auto-TLDR; Understanding the Dynamics of Facial Emotion Expression with Spatiotemporal Representations
Abstract Slides Poster Similar
Self-Supervised Learning of Dynamic Representations for Static Images
Siyang Song, Enrique Sanchez, Linlin Shen, Michel Valstar

Auto-TLDR; Facial Action Unit Intensity Estimation and Affect Estimation from Still Images with Multiple Temporal Scale
Abstract Slides Poster Similar
Two-Stream Temporal Convolutional Network for Dynamic Facial Attractiveness Prediction
Nina Weng, Jiahao Wang, Annan Li, Yunhong Wang

Auto-TLDR; 2S-TCN: A Two-Stream Temporal Convolutional Network for Dynamic Facial Attractiveness Prediction
Abstract Slides Poster Similar
HP2IFS: Head Pose Estimation Exploiting Partitioned Iterated Function Systems
Carmen Bisogni, Michele Nappi, Chiara Pero, Stefano Ricciardi

Auto-TLDR; PIFS based head pose estimation using fractal coding theory and Partitioned Iterated Function Systems
Abstract Slides Poster Similar
Automatic Annotation of Corpora for Emotion Recognition through Facial Expressions Analysis
Alex Mircoli, Claudia Diamantini, Domenico Potena, Emanuele Storti

Auto-TLDR; Automatic annotation of video subtitles on the basis of facial expressions using machine learning algorithms
Abstract Slides Poster Similar
Inner Eye Canthus Localization for Human Body Temperature Screening
Claudio Ferrari, Lorenzo Berlincioni, Marco Bertini, Alberto Del Bimbo

Auto-TLDR; Automatic Localization of the Inner Eye Canthus in Thermal Face Images using 3D Morphable Face Model
Abstract Slides Poster Similar
Attribute-Based Quality Assessment for Demographic Estimation in Face Videos
Fabiola Becerra-Riera, Annette Morales-González, Heydi Mendez-Vazquez, Jean-Luc Dugelay

Auto-TLDR; Facial Demographic Estimation in Video Scenarios Using Quality Assessment
Improved Time-Series Clustering with UMAP Dimension Reduction Method
Clément Pealat, Vincent Cheutet, Guillaume Bouleux

Auto-TLDR; Time Series Clustering with UMAP as a Pre-processing Step
Abstract Slides Poster Similar
Hybrid Approach for 3D Head Reconstruction: Using Neural Networks and Visual Geometry
Oussema Bouafif, Bogdan Khomutenko, Mohammed Daoudi

Auto-TLDR; Recovering 3D Head Geometry from a Single Image using Deep Learning and Geometric Techniques
Abstract Slides Poster Similar
3D Facial Matching by Spiral Convolutional Metric Learning and a Biometric Fusion-Net of Demographic Properties
Soha Sadat Mahdi, Nele Nauwelaers, Philip Joris, Giorgos Bouritsas, Imperial London, Sergiy Bokhnyak, Susan Walsh, Mark Shriver, Michael Bronstein, Peter Claes

Auto-TLDR; Multi-biometric Fusion for Biometric Verification using 3D Facial Mesures
Nonlinear Ranking Loss on Riemannian Potato Embedding
Byung Hyung Kim, Yoonje Suh, Honggu Lee, Sungho Jo

Auto-TLDR; Riemannian Potato for Rank-based Metric Learning
Abstract Slides Poster Similar
Encoding Brain Networks through Geodesic Clustering of Functional Connectivity for Multiple Sclerosis Classification
Muhammad Abubakar Yamin, Valsasina Paola, Michael Dayan, Sebastiano Vascon, Tessadori Jacopo, Filippi Massimo, Vittorio Murino, A Rocca Maria, Diego Sona

Auto-TLDR; Geodesic Clustering of Connectivity Matrices for Multiple Sclerosis Classification
Abstract Slides Poster Similar
Learning Non-Rigid Surface Reconstruction from Spatio-Temporal Image Patches
Matteo Pedone, Abdelrahman Mostafa, Janne Heikkilä

Auto-TLDR; Dense Spatio-Temporal Depth Maps of Deformable Objects from Video Sequences
Abstract Slides Poster Similar
Identity-Aware Facial Expression Recognition in Compressed Video
Xiaofeng Liu, Linghao Jin, Xu Han, Jun Lu, Jonghye Woo, Jane You

Auto-TLDR; Exploring Facial Expression Representation in Compressed Video with Mutual Information Minimization
Audio-Video Detection of the Active Speaker in Meetings
Francisco Madrigal, Frederic Lerasle, Lionel Pibre, Isabelle Ferrané

Auto-TLDR; Active Speaker Detection with Visual and Contextual Information from Meeting Context
Abstract Slides Poster Similar
Learning Dictionaries of Kinematic Primitives for Action Classification
Alessia Vignolo, Nicoletta Noceti, Alessandra Sciutti, Francesca Odone, Giulio Sandini

Auto-TLDR; Action Understanding using Visual Motion Primitives
Abstract Slides Poster Similar
SAT-Net: Self-Attention and Temporal Fusion for Facial Action Unit Detection
Zhihua Li, Zheng Zhang, Lijun Yin

Auto-TLDR; Temporal Fusion and Self-Attention Network for Facial Action Unit Detection
Abstract Slides Poster Similar
Learning Visual Voice Activity Detection with an Automatically Annotated Dataset
Stéphane Lathuiliere, Pablo Mesejo, Radu Horaud

Auto-TLDR; Deep Visual Voice Activity Detection with Optical Flow
Responsive Social Smile: A Machine-Learning Based Multimodal Behavior Assessment Framework towards Early Stage Autism Screening
Yueran Pan, Kunjing Cai, Ming Cheng, Xiaobing Zou, Ming Li

Auto-TLDR; Responsive Social Smile: A Machine Learningbased Assessment Framework for Early ASD Screening
Learning Connectivity with Graph Convolutional Networks

Auto-TLDR; Learning Graph Convolutional Networks Using Topological Properties of Graphs
Abstract Slides Poster Similar
Rank-Based Ordinal Classification

Auto-TLDR; Ordinal Classification with Order
Abstract Slides Poster Similar
Transformer Networks for Trajectory Forecasting
Francesco Giuliari, Hasan Irtiza, Marco Cristani, Fabio Galasso

Auto-TLDR; TransformerNetworks for Trajectory Prediction of People Interactions
Abstract Slides Poster Similar
Using Meta Labels for the Training of Weighting Models in a Sample-Specific Late Fusion Classification Architecture
Peter Bellmann, Patrick Thiam, Friedhelm Schwenker

Auto-TLDR; A Late Fusion Architecture for Multiple Classifier Systems
Abstract Slides Poster Similar
Siamese-Structure Deep Neural Network Recognizing Changes in Facial Expression According to the Degree of Smiling
Kazuaki Kondo, Taichi Nakamura, Yuichi Nakamura, Shin'Ichi Satoh

Auto-TLDR; A Siamese-Structure Deep Neural Network for Happiness Recognition
Abstract Slides Poster Similar
A Hybrid Metric Based on Persistent Homology and Its Application to Signal Classification
Austin Lawson, Yu-Min Chung, William Cruse

Auto-TLDR; Topological Data Analysis with Persistence Curves
Recognizing American Sign Language Nonmanual Signal Grammar Errors in Continuous Videos
Elahe Vahdani, Longlong Jing, Ying-Li Tian, Matt Huenerfauth

Auto-TLDR; ASL-HW-RGBD: Recognizing Grammatical Errors in Continuous Sign Language
Abstract Slides Poster Similar
Real-Time Driver Drowsiness Detection Using Facial Action Units
Malaika Vijay, Nandagopal Netrakanti Vinayak, Maanvi Nunna, Subramanyam Natarajan

Auto-TLDR; Real-Time Detection of Driver Drowsiness using Facial Action Units using Extreme Gradient Boosting
Abstract Slides Poster Similar
AttendAffectNet: Self-Attention Based Networks for Predicting Affective Responses from Movies
Thi Phuong Thao Ha, Bt Balamurali, Herremans Dorien, Roig Gemma

Auto-TLDR; AttendAffectNet: A Self-Attention Based Network for Emotion Prediction from Movies
Abstract Slides Poster Similar
A New Geodesic-Based Feature for Characterization of 3D Shapes: Application to Soft Tissue Organ Temporal Deformations
Karim Makki, Amine Bohi, Augustin Ogier, Marc-Emmanuel Bellemare

Auto-TLDR; Spatio-Temporal Feature Descriptors for 3D Shape Characterization from Point Clouds
Abstract Slides Poster Similar
Inferring Functional Properties from Fluid Dynamics Features
Andrea Schillaci, Maurizio Quadrio, Carlotta Pipolo, Marcello Restelli, Giacomo Boracchi

Auto-TLDR; Exploiting Convective Properties of Computational Fluid Dynamics for Medical Diagnosis
Abstract Slides Poster Similar
Video Face Manipulation Detection through Ensemble of CNNs
Nicolo Bonettini, Edoardo Daniele Cannas, Sara Mandelli, Luca Bondi, Paolo Bestagini, Stefano Tubaro

Auto-TLDR; Face Manipulation Detection in Video Sequences Using Convolutional Neural Networks
Learning Recurrent High-Order Statistics for Skeleton-Based Hand Gesture Recognition
Xuan Son Nguyen, Luc Brun, Olivier Lezoray, Sébastien Bougleux
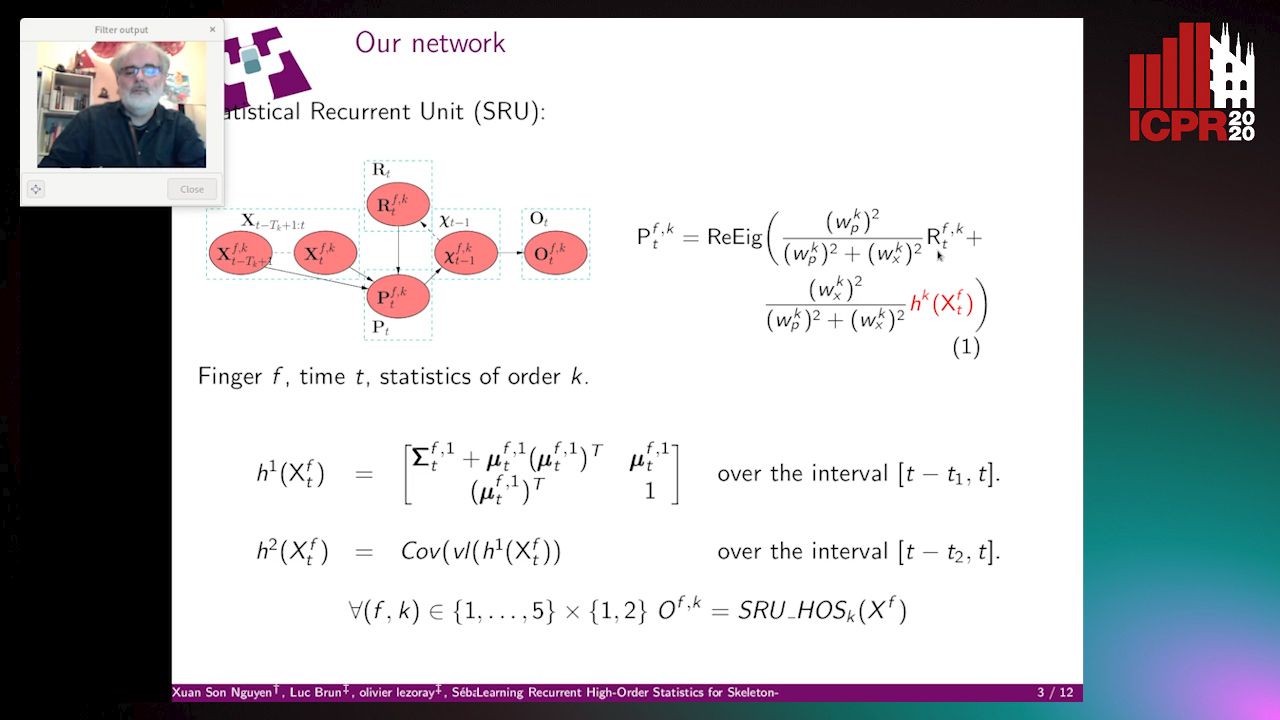
Auto-TLDR; Exploiting High-Order Statistics in Recurrent Neural Networks for Hand Gesture Recog-nition
Detecting Manipulated Facial Videos: A Time Series Solution
Zhang Zhewei, Ma Can, Gao Meilin, Ding Bowen

Auto-TLDR; Face-Alignment Based Bi-LSTM for Fake Video Detection
Abstract Slides Poster Similar
Total Estimation from RGB Video: On-Line Camera Self-Calibration, Non-Rigid Shape and Motion

Auto-TLDR; Joint Auto-Calibration, Pose and 3D Reconstruction of a Non-rigid Object from an uncalibrated RGB Image Sequence
Abstract Slides Poster Similar
Multi-Attribute Regression Network for Face Reconstruction

Auto-TLDR; A Multi-Attribute Regression Network for Face Reconstruction
Abstract Slides Poster Similar
Magnifying Spontaneous Facial Micro Expressions for Improved Recognition
Pratikshya Sharma, Sonya Coleman, Pratheepan Yogarajah, Laurence Taggart, Pradeepa Samarasinghe

Auto-TLDR; Eulerian Video Magnification for Micro Expression Recognition
Abstract Slides Poster Similar
A Quantitative Evaluation Framework of Video De-Identification Methods
Sathya Bursic, Alessandro D'Amelio, Marco Granato, Giuliano Grossi, Raffaella Lanzarotti

Auto-TLDR; Face de-identification using photo-reality and facial expressions
Abstract Slides Poster Similar
Comparison of Stacking-Based Classifier Ensembles Using Euclidean and Riemannian Geometries
Vitaliy Tayanov, Adam Krzyzak, Ching Y Suen

Auto-TLDR; Classifier Stacking in Riemannian Geometries using Cascades of Random Forest and Extra Trees
Abstract Slides Poster Similar
A Spectral Clustering on Grassmann Manifold Via Double Low Rank Constraint
Xinglin Piao, Yongli Hu, Junbin Gao, Yanfeng Sun, Xin Yang, Baocai Yin

Auto-TLDR; Double Low Rank Representation for High-Dimensional Data Clustering on Grassmann Manifold
Weight Estimation from an RGB-D Camera in Top-View Configuration
Marco Mameli, Marina Paolanti, Nicola Conci, Filippo Tessaro, Emanuele Frontoni, Primo Zingaretti

Auto-TLDR; Top-View Weight Estimation using Deep Neural Networks
Abstract Slides Poster Similar
Video-Based Facial Expression Recognition Using Graph Convolutional Networks
Daizong Liu, Hongting Zhang, Pan Zhou

Auto-TLDR; Graph Convolutional Network for Video-based Facial Expression Recognition
Abstract Slides Poster Similar
Subspace Clustering for Action Recognition with Covariance Representations and Temporal Pruning
Giancarlo Paoletti, Jacopo Cavazza, Cigdem Beyan, Alessio Del Bue

Auto-TLDR; Unsupervised Learning for Human Action Recognition from Skeletal Data
Depth Videos for the Classification of Micro-Expressions
Ankith Jain Rakesh Kumar, Bir Bhanu, Christopher Casey, Sierra Cheung, Aaron Seitz

Auto-TLDR; RGB-D Dataset for the Classification of Facial Micro-expressions
Abstract Slides Poster Similar
Motion Segmentation with Pairwise Matches and Unknown Number of Motions
Federica Arrigoni, Tomas Pajdla, Luca Magri

Auto-TLDR; Motion Segmentation using Multi-Modelfitting andpermutation synchronization
Abstract Slides Poster Similar
Kernel-based Graph Convolutional Networks

Auto-TLDR; Spatial Graph Convolutional Networks in Recurrent Kernel Hilbert Space
Abstract Slides Poster Similar
Deep Multi-Task Learning for Facial Expression Recognition and Synthesis Based on Selective Feature Sharing
Rui Zhao, Tianshan Liu, Jun Xiao, P. K. Daniel Lun, Kin-Man Lam

Auto-TLDR; Multi-task Learning for Facial Expression Recognition and Synthesis
Abstract Slides Poster Similar