A Distinct Discriminant Canonical Correlation Analysis Network Based Deep Information Quality Representation for Image Classification
Lei Gao,
Zheng Guo,
Ling Guan Ling Guan

Auto-TLDR; DDCCANet: Deep Information Quality Representation for Image Classification
Similar papers
Embedding Shared Low-Rank and Feature Correlation for Multi-View Data Analysis
Zhan Wang, Lizhi Wang, Hua Huang

Auto-TLDR; embedding shared low-rank and feature correlation for multi-view data analysis
Abstract Slides Poster Similar
Feature Extraction by Joint Robust Discriminant Analysis and Inter-Class Sparsity

Auto-TLDR; Robust Discriminant Analysis with Feature Selection and Inter-class Sparsity (RDA_FSIS)
Joint Learning Multiple Curvature Descriptor for 3D Palmprint Recognition
Lunke Fei, Bob Zhang, Jie Wen, Chunwei Tian, Peng Liu, Shuping Zhao

Auto-TLDR; Joint Feature Learning for 3D palmprint recognition using curvature data vectors
Abstract Slides Poster Similar
Low Rank Representation on Product Grassmann Manifolds for Multi-viewSubspace Clustering
Jipeng Guo, Yanfeng Sun, Junbin Gao, Yongli Hu, Baocai Yin

Auto-TLDR; Low Rank Representation on Product Grassmann Manifold for Multi-View Data Clustering
Abstract Slides Poster Similar
Feature Extraction and Selection Via Robust Discriminant Analysis and Class Sparsity

Auto-TLDR; Hybrid Linear Discriminant Embedding for supervised multi-class classification
Abstract Slides Poster Similar
Local Grouped Invariant Order Pattern for Grayscale-Inversion and Rotation Invariant Texture Classification
Yankai Huang, Tiecheng Song, Shuang Li, Yuanjing Han

Auto-TLDR; Local grouped invariant order pattern for grayscale-inversion and rotation invariant texture classification
Abstract Slides Poster Similar
Local Binary Quaternion Rotation Pattern for Colour Texture Retrieval
Hela Jebali, Noel Richard, Mohamed Naouai
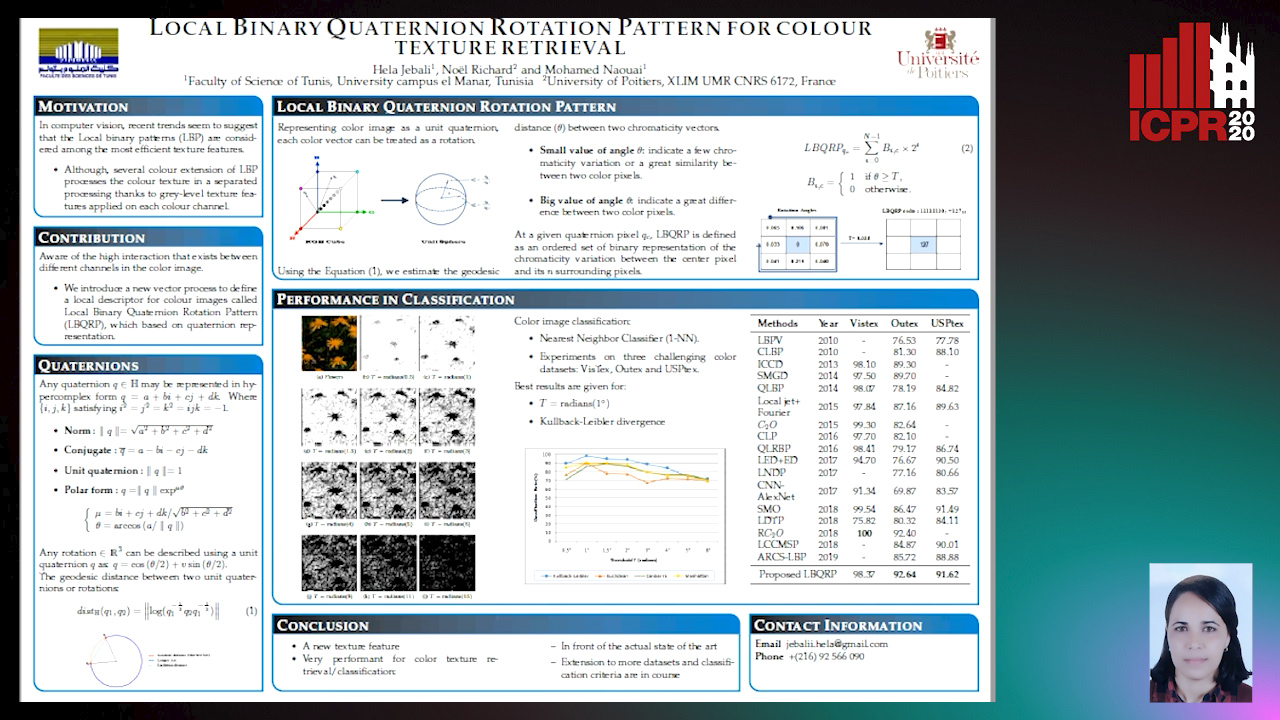
Auto-TLDR; Local Binary Quaternion Rotation Pattern for Color Texture Classification
Soft Label and Discriminant Embedding Estimation for Semi-Supervised Classification
Fadi Dornaika, Abdullah Baradaaji, Youssof El Traboulsi

Auto-TLDR; Semi-supervised Semi-Supervised Learning for Linear Feature Extraction and Label Propagation
Abstract Slides Poster Similar
Subspace Clustering Via Joint Unsupervised Feature Selection
Wenhua Dong, Xiaojun Wu, Hui Li, Zhenhua Feng, Josef Kittler

Auto-TLDR; Unsupervised Feature Selection for Subspace Clustering
Cross-spectrum Face Recognition Using Subspace Projection Hashing
Hanrui Wang, Xingbo Dong, Jin Zhe, Jean-Luc Dugelay, Massimo Tistarelli

Auto-TLDR; Subspace Projection Hashing for Cross-Spectrum Face Recognition
Abstract Slides Poster Similar
Face Anti-Spoofing Using Spatial Pyramid Pooling
Lei Shi, Zhuo Zhou, Zhenhua Guo

Auto-TLDR; Spatial Pyramid Pooling for Face Anti-Spoofing
Abstract Slides Poster Similar
Appliance Identification Using a Histogram Post-Processing of 2D Local Binary Patterns for Smart Grid Applications
Yassine Himeur, Abdullah Alsalemi, Faycal Bensaali, Abbes Amira

Auto-TLDR; LBP-BEVM based Local Binary Patterns for Appliances Identification in the Smart Grid
A Local Descriptor with Physiological Characteristic for Finger Vein Recognition
Liping Zhang, Weijun Li, Ning Xin

Auto-TLDR; Finger vein-specific local feature descriptors based physiological characteristic of finger vein patterns
Abstract Slides Poster Similar
Face Anti-Spoofing Based on Dynamic Color Texture Analysis Using Local Directional Number Pattern
Junwei Zhou, Ke Shu, Peng Liu, Jianwen Xiang, Shengwu Xiong

Auto-TLDR; LDN-TOP Representation followed by ProCRC Classification for Face Anti-Spoofing
Abstract Slides Poster Similar
Two-Level Attention-Based Fusion Learning for RGB-D Face Recognition
Hardik Uppal, Alireza Sepas-Moghaddam, Michael Greenspan, Ali Etemad

Auto-TLDR; Fused RGB-D Facial Recognition using Attention-Aware Feature Fusion
Abstract Slides Poster Similar
Color Texture Description Based on Holistic and Hierarchical Order-Encoding Patterns
Tiecheng Song, Jie Feng, Yuanlin Wang, Chenqiang Gao

Auto-TLDR; Holistic and Hierarchical Order-Encoding Patterns for Color Texture Classification
Abstract Slides Poster Similar
RGB-Infrared Person Re-Identification Via Image Modality Conversion
Huangpeng Dai, Qing Xie, Yanchun Ma, Yongjian Liu, Shengwu Xiong

Auto-TLDR; CE2L: A Novel Network for Cross-Modality Re-identification with Feature Alignment
Abstract Slides Poster Similar
Quality-Based Representation for Unconstrained Face Recognition
Nelson Méndez-Llanes, Katy Castillo-Rosado, Heydi Mendez-Vazquez, Massimo Tistarelli

Auto-TLDR; activation map for face recognition in unconstrained environments
Attention Pyramid Module for Scene Recognition
Zhinan Qiao, Xiaohui Yuan, Chengyuan Zhuang, Abolfazl Meyarian

Auto-TLDR; Attention Pyramid Module for Multi-Scale Scene Recognition
Abstract Slides Poster Similar
Supervised Domain Adaptation Using Graph Embedding
Lukas Hedegaard, Omar Ali Sheikh-Omar, Alexandros Iosifidis

Auto-TLDR; Domain Adaptation from the Perspective of Multi-view Graph Embedding and Dimensionality Reduction
Abstract Slides Poster Similar
Norm Loss: An Efficient yet Effective Regularization Method for Deep Neural Networks
Theodoros Georgiou, Sebastian Schmitt, Thomas Baeck, Wei Chen, Michael Lew

Auto-TLDR; Weight Soft-Regularization with Oblique Manifold for Convolutional Neural Network Training
Abstract Slides Poster Similar
Rotation Invariant Aerial Image Retrieval with Group Convolutional Metric Learning
Hyunseung Chung, Woo-Jeoung Nam, Seong-Whan Lee

Auto-TLDR; Robust Remote Sensing Image Retrieval Using Group Convolution with Attention Mechanism and Metric Learning
Abstract Slides Poster Similar
Pose-Robust Face Recognition by Deep Meta Capsule Network-Based Equivariant Embedding
Fangyu Wu, Jeremy Simon Smith, Wenjin Lu, Bailing Zhang

Auto-TLDR; Deep Meta Capsule Network-based Equivariant Embedding Model for Pose-Robust Face Recognition
Super-Resolution Guided Pore Detection for Fingerprint Recognition
Syeda Nyma Ferdous, Ali Dabouei, Jeremy Dawson, Nasser M. Nasarabadi

Auto-TLDR; Super-Resolution Generative Adversarial Network for Fingerprint Recognition Using Pore Features
Abstract Slides Poster Similar
Supervised Feature Embedding for Classification by Learning Rank-Based Neighborhoods
Ghazaal Sheikhi, Hakan Altincay

Auto-TLDR; Supervised Feature Embedding with Representation Learning of Rank-based Neighborhoods
More Correlations Better Performance: Fully Associative Networks for Multi-Label Image Classification

Auto-TLDR; Fully Associative Network for Fully Exploiting Correlation Information in Multi-Label Classification
Abstract Slides Poster Similar
Image Representation Learning by Transformation Regression
Xifeng Guo, Jiyuan Liu, Sihang Zhou, En Zhu, Shihao Dong

Auto-TLDR; Self-supervised Image Representation Learning using Continuous Parameter Prediction
Abstract Slides Poster Similar
ClusterFace: Joint Clustering and Classification for Set-Based Face Recognition
Samadhi Poornima Kumarasinghe Wickrama Arachchilage, Ebroul Izquierdo

Auto-TLDR; Joint Clustering and Classification for Face Recognition in the Wild
Abstract Slides Poster Similar
Attentive Hybrid Feature Based a Two-Step Fusion for Facial Expression Recognition
Jun Weng, Yang Yang, Zichang Tan, Zhen Lei

Auto-TLDR; Attentive Hybrid Architecture for Facial Expression Recognition
Abstract Slides Poster Similar
Subspace Clustering for Action Recognition with Covariance Representations and Temporal Pruning
Giancarlo Paoletti, Jacopo Cavazza, Cigdem Beyan, Alessio Del Bue

Auto-TLDR; Unsupervised Learning for Human Action Recognition from Skeletal Data
Exploiting Knowledge Embedded Soft Labels for Image Recognition
Lixian Yuan, Riquan Chen, Hefeng Wu, Tianshui Chen, Wentao Wang, Pei Chen

Auto-TLDR; A Soft Label Vector for Image Recognition
Abstract Slides Poster Similar
Self-Paced Bottom-Up Clustering Network with Side Information for Person Re-Identification
Mingkun Li, Chun-Guang Li, Ruo-Pei Guo, Jun Guo

Auto-TLDR; Self-Paced Bottom-up Clustering Network with Side Information for Unsupervised Person Re-identification
Abstract Slides Poster Similar
Improved Deep Classwise Hashing with Centers Similarity Learning for Image Retrieval

Auto-TLDR; Deep Classwise Hashing for Image Retrieval Using Center Similarity Learning
Abstract Slides Poster Similar
Space-Time Domain Tensor Neural Networks: An Application on Human Pose Classification
Konstantinos Makantasis, Athanasios Voulodimos, Anastasios Doulamis, Nikolaos Doulamis, Nikolaos Bakalos

Auto-TLDR; Tensor-Based Neural Network for Spatiotemporal Pose Classifiaction using Three-Dimensional Skeleton Data
Abstract Slides Poster Similar
Multi-Scale Cascading Network with Compact Feature Learning for RGB-Infrared Person Re-Identification
Can Zhang, Hong Liu, Wei Guo, Mang Ye

Auto-TLDR; Multi-Scale Part-Aware Cascading for RGB-Infrared Person Re-identification
Abstract Slides Poster Similar
A CNN-RNN Framework for Image Annotation from Visual Cues and Social Network Metadata
Tobia Tesan, Pasquale Coscia, Lamberto Ballan

Auto-TLDR; Context-Based Image Annotation with Multiple Semantic Embeddings and Recurrent Neural Networks
Abstract Slides Poster Similar
Trainable Spectrally Initializable Matrix Transformations in Convolutional Neural Networks
Michele Alberti, Angela Botros, Schuetz Narayan, Rolf Ingold, Marcus Liwicki, Mathias Seuret

Auto-TLDR; Trainable and Spectrally Initializable Matrix Transformations for Neural Networks
Abstract Slides Poster Similar
Face Image Quality Assessment for Model and Human Perception
Ken Chen, Yichao Wu, Zhenmao Li, Yudong Wu, Ding Liang

Auto-TLDR; A labour-saving method for FIQA training with contradictory data from multiple sources
Abstract Slides Poster Similar
Free-Form Image Inpainting Via Contrastive Attention Network
Xin Ma, Xiaoqiang Zhou, Huaibo Huang, Zhenhua Chai, Xiaolin Wei, Ran He

Auto-TLDR; Self-supervised Siamese inference for image inpainting
Label Self-Adaption Hashing for Image Retrieval
Jianglin Lu, Zhihui Lai, Hailing Wang, Jie Zhou

Auto-TLDR; Label Self-Adaption Hashing for Large-Scale Image Retrieval
Abstract Slides Poster Similar
A Joint Representation Learning and Feature Modeling Approach for One-Class Recognition
Pramuditha Perera, Vishal Patel

Auto-TLDR; Combining Generative Features and One-Class Classification for Effective One-class Recognition
Abstract Slides Poster Similar
Exploring the Ability of CNNs to Generalise to Previously Unseen Scales Over Wide Scale Ranges

Auto-TLDR; A theoretical analysis of invariance and covariance properties of scale channel networks
Abstract Slides Poster Similar
Object Detection on Monocular Images with Two-Dimensional Canonical Correlation Analysis

Auto-TLDR; Multi-Task Object Detection from Monocular Images Using Multimodal RGB and Depth Data
Abstract Slides Poster Similar
DAIL: Dataset-Aware and Invariant Learning for Face Recognition
Gaoang Wang, Chen Lin, Tianqiang Liu, Mingwei He, Jiebo Luo

Auto-TLDR; DAIL: Dataset-Aware and Invariant Learning for Face Recognition
Abstract Slides Poster Similar
Multi-Level Deep Learning Vehicle Re-Identification Using Ranked-Based Loss Functions
Eleni Kamenou, Jesus Martinez-Del-Rincon, Paul Miller, Patricia Devlin - Hill

Auto-TLDR; Multi-Level Re-identification Network for Vehicle Re-Identification
Abstract Slides Poster Similar
Nonlinear Ranking Loss on Riemannian Potato Embedding
Byung Hyung Kim, Yoonje Suh, Honggu Lee, Sungho Jo

Auto-TLDR; Riemannian Potato for Rank-based Metric Learning
Abstract Slides Poster Similar
MANet: Multimodal Attention Network Based Point-View Fusion for 3D Shape Recognition
Yaxin Zhao, Jichao Jiao, Ning Li

Auto-TLDR; Fusion Network for 3D Shape Recognition based on Multimodal Attention Mechanism
Abstract Slides Poster Similar
Efficient Online Subclass Knowledge Distillation for Image Classification
Maria Tzelepi, Nikolaos Passalis, Anastasios Tefas

Auto-TLDR; OSKD: Online Subclass Knowledge Distillation
Abstract Slides Poster Similar