A Local Descriptor with Physiological Characteristic for Finger Vein Recognition
Liping Zhang,
Weijun Li,
Ning Xin

Auto-TLDR; Finger vein-specific local feature descriptors based physiological characteristic of finger vein patterns
Similar papers
Finger Vein Recognition and Intra-Subject Similarity Evaluation of Finger Veins Using the CNN Triplet Loss
Georg Wimmer, Bernhard Prommegger, Andreas Uhl

Auto-TLDR; Finger vein recognition using CNNs and hard triplet online selection
Abstract Slides Poster Similar
Rotation Detection in Finger Vein Biometrics Using CNNs
Bernhard Prommegger, Georg Wimmer, Andreas Uhl

Auto-TLDR; A CNN based rotation detector for finger vein recognition
Abstract Slides Poster Similar
Can You Really Trust the Sensor's PRNU? How Image Content Might Impact the Finger Vein Sensor Identification Performance
Dominik Söllinger, Luca Debiasi, Andreas Uhl

Auto-TLDR; Finger vein imagery can cause the PRNU estimate to be biased by image content
Abstract Slides Poster Similar
Joint Learning Multiple Curvature Descriptor for 3D Palmprint Recognition
Lunke Fei, Bob Zhang, Jie Wen, Chunwei Tian, Peng Liu, Shuping Zhao

Auto-TLDR; Joint Feature Learning for 3D palmprint recognition using curvature data vectors
Abstract Slides Poster Similar
Face Anti-Spoofing Based on Dynamic Color Texture Analysis Using Local Directional Number Pattern
Junwei Zhou, Ke Shu, Peng Liu, Jianwen Xiang, Shengwu Xiong

Auto-TLDR; LDN-TOP Representation followed by ProCRC Classification for Face Anti-Spoofing
Abstract Slides Poster Similar
A Distinct Discriminant Canonical Correlation Analysis Network Based Deep Information Quality Representation for Image Classification
Lei Gao, Zheng Guo, Ling Guan Ling Guan

Auto-TLDR; DDCCANet: Deep Information Quality Representation for Image Classification
Abstract Slides Poster Similar
Gaussian Convolution Angles: Invariant Vein and Texture Descriptors for Butterfly Species Identification
Xin Chen, Bin Wang, Yongsheng Gao

Auto-TLDR; Gaussian convolution angle for butterfly species classification
Abstract Slides Poster Similar
Local Grouped Invariant Order Pattern for Grayscale-Inversion and Rotation Invariant Texture Classification
Yankai Huang, Tiecheng Song, Shuang Li, Yuanjing Han

Auto-TLDR; Local grouped invariant order pattern for grayscale-inversion and rotation invariant texture classification
Abstract Slides Poster Similar
Color Texture Description Based on Holistic and Hierarchical Order-Encoding Patterns
Tiecheng Song, Jie Feng, Yuanlin Wang, Chenqiang Gao

Auto-TLDR; Holistic and Hierarchical Order-Encoding Patterns for Color Texture Classification
Abstract Slides Poster Similar
Super-Resolution Guided Pore Detection for Fingerprint Recognition
Syeda Nyma Ferdous, Ali Dabouei, Jeremy Dawson, Nasser M. Nasarabadi

Auto-TLDR; Super-Resolution Generative Adversarial Network for Fingerprint Recognition Using Pore Features
Abstract Slides Poster Similar
First and Second-Order Sorted Local Binary Pattern Features for Grayscale-Inversion and Rotation Invariant Texture Classification
Tiecheng Song, Yuanjing Han, Jie Feng, Yuanlin Wang, Chenqiang Gao

Auto-TLDR; First- and Secondorder Sorted Local Binary Pattern for texture classification under inverse grayscale changes and image rotation
Abstract Slides Poster Similar
Face Anti-Spoofing Using Spatial Pyramid Pooling
Lei Shi, Zhuo Zhou, Zhenhua Guo

Auto-TLDR; Spatial Pyramid Pooling for Face Anti-Spoofing
Abstract Slides Poster Similar
Writer Identification Using Deep Neural Networks: Impact of Patch Size and Number of Patches
Akshay Punjabi, José Ramón Prieto Fontcuberta, Enrique Vidal

Auto-TLDR; Writer Recognition Using Deep Neural Networks for Handwritten Text Images
Abstract Slides Poster Similar
Local Binary Quaternion Rotation Pattern for Colour Texture Retrieval
Hela Jebali, Noel Richard, Mohamed Naouai
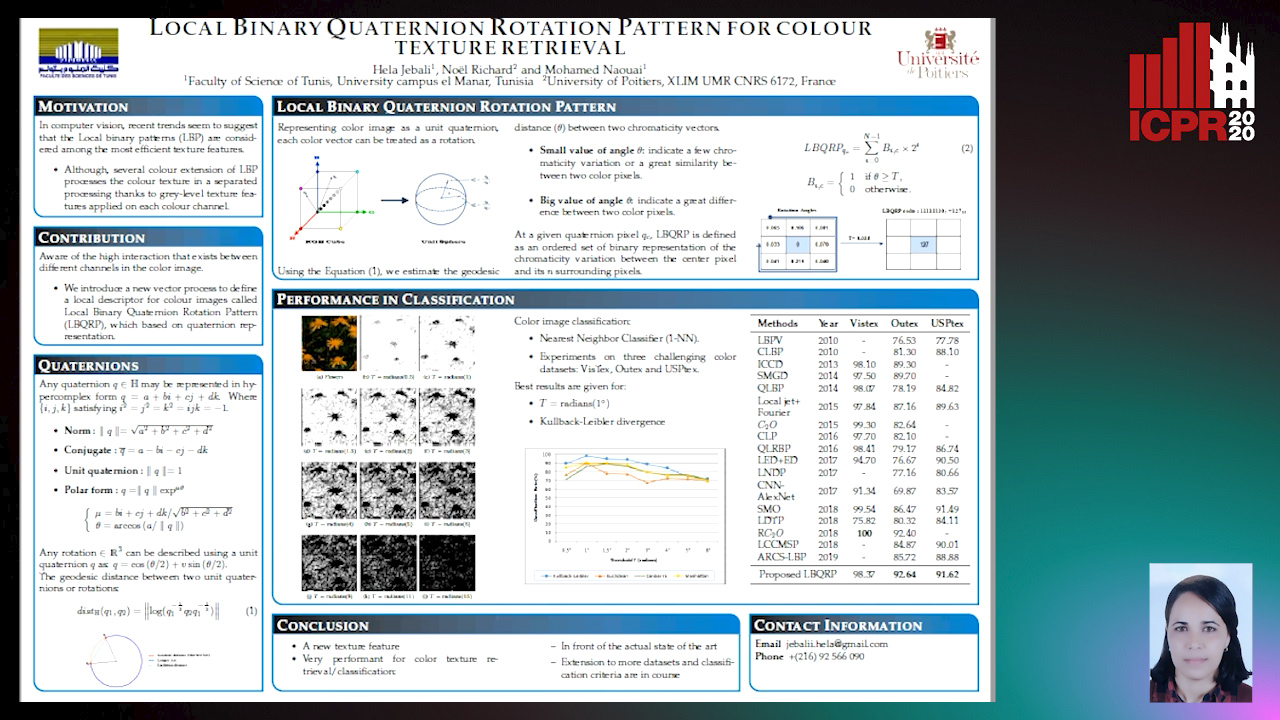
Auto-TLDR; Local Binary Quaternion Rotation Pattern for Color Texture Classification
Merged 1D-2D Deep Convolutional Neural Networks for Nerve Detection in Ultrasound Images
Mohammad Alkhatib, Adel Hafiane, Pierre Vieyres

Auto-TLDR; A Deep Neural Network for Deep Neural Networks to Detect Median Nerve in Ultrasound-Guided Regional Anesthesia
Abstract Slides Poster Similar
Appliance Identification Using a Histogram Post-Processing of 2D Local Binary Patterns for Smart Grid Applications
Yassine Himeur, Abdullah Alsalemi, Faycal Bensaali, Abbes Amira

Auto-TLDR; LBP-BEVM based Local Binary Patterns for Appliances Identification in the Smart Grid
Fingerprints, Forever Young?
Roman Kessler, Olaf Henniger, Christoph Busch

Auto-TLDR; Mated Similarity Scores for Fingerprint Recognition: A Hierarchical Linear Model
Abstract Slides Poster Similar
Local Attention and Global Representation Collaborating for Fine-Grained Classification
He Zhang, Yunming Bai, Hui Zhang, Jing Liu, Xingguang Li, Zhaofeng He

Auto-TLDR; Weighted Region Network for Cosmetic Contact Lenses Detection
Abstract Slides Poster Similar
Quality-Based Representation for Unconstrained Face Recognition
Nelson Méndez-Llanes, Katy Castillo-Rosado, Heydi Mendez-Vazquez, Massimo Tistarelli

Auto-TLDR; activation map for face recognition in unconstrained environments
Automatic Tuberculosis Detection Using Chest X-Ray Analysis with Position Enhanced Structural Information
Hermann Jepdjio Nkouanga, Szilard Vajda

Auto-TLDR; Automatic Chest X-ray Screening for Tuberculosis in Rural Population using Localized Region on Interest
Abstract Slides Poster Similar
Visual Saliency Oriented Vehicle Scale Estimation
Qixin Chen, Tie Liu, Jiali Ding, Zejian Yuan, Yuanyuan Shang

Auto-TLDR; Regularized Intensity Matching for Vehicle Scale Estimation with salient object detection
Abstract Slides Poster Similar
3D Dental Biometrics: Automatic Pose-Invariant Dental Arch Extraction and Matching

Auto-TLDR; Automatic Dental Arch Extraction and Matching for 3D Dental Identification using Laser-Scanned Plasters
Abstract Slides Poster Similar
Cancelable Biometrics Vault: A Secure Key-Binding Biometric Cryptosystem Based on Chaffing and Winnowing
Osama Ouda, Karthik Nandakumar, Arun Ross

Auto-TLDR; Cancelable Biometrics Vault for Key-binding Biometric Cryptosystem Framework
Abstract Slides Poster Similar
Feature Extraction by Joint Robust Discriminant Analysis and Inter-Class Sparsity

Auto-TLDR; Robust Discriminant Analysis with Feature Selection and Inter-class Sparsity (RDA_FSIS)
Detection of Makeup Presentation Attacks Based on Deep Face Representations
Christian Rathgeb, Pawel Drozdowski, Christoph Busch

Auto-TLDR; An Attack Detection Scheme for Face Recognition Using Makeup Presentation Attacks
Abstract Slides Poster Similar
Attentive Hybrid Feature Based a Two-Step Fusion for Facial Expression Recognition
Jun Weng, Yang Yang, Zichang Tan, Zhen Lei

Auto-TLDR; Attentive Hybrid Architecture for Facial Expression Recognition
Abstract Slides Poster Similar
Cross-spectrum Face Recognition Using Subspace Projection Hashing
Hanrui Wang, Xingbo Dong, Jin Zhe, Jean-Luc Dugelay, Massimo Tistarelli

Auto-TLDR; Subspace Projection Hashing for Cross-Spectrum Face Recognition
Abstract Slides Poster Similar
Documents Counterfeit Detection through a Deep Learning Approach
Darwin Danilo Saire Pilco, Salvatore Tabbone

Auto-TLDR; End-to-End Learning for Counterfeit Documents Detection using Deep Neural Network
Abstract Slides Poster Similar
Rotation Invariant Aerial Image Retrieval with Group Convolutional Metric Learning
Hyunseung Chung, Woo-Jeoung Nam, Seong-Whan Lee

Auto-TLDR; Robust Remote Sensing Image Retrieval Using Group Convolution with Attention Mechanism and Metric Learning
Abstract Slides Poster Similar
Level Three Synthetic Fingerprint Generation
Andre Wyzykowski, Mauricio Pamplona Segundo, Rubisley Lemes

Auto-TLDR; Synthesis of High-Resolution Fingerprints with Pore Detection Using CycleGAN
Abstract Slides Poster Similar
Learning Metric Features for Writer-Independent Signature Verification Using Dual Triplet Loss
Auto-TLDR; A dual triplet loss based method for offline writer-independent signature verification
Exploring Seismocardiogram Biometrics with Wavelet Transform
Po-Ya Hsu, Po-Han Hsu, Hsin-Li Liu

Auto-TLDR; Seismocardiogram Biometric Matching Using Wavelet Transform and Deep Learning Models
Abstract Slides Poster Similar
Learning Disentangled Representations for Identity Preserving Surveillance Face Camouflage
Jingzhi Li, Lutong Han, Hua Zhang, Xiaoguang Han, Jingguo Ge, Xiaochu Cao

Auto-TLDR; Individual Face Privacy under Surveillance Scenario with Multi-task Loss Function
How Unique Is a Face: An Investigative Study
Michal Balazia, S L Happy, Francois Bremond, Antitza Dantcheva

Auto-TLDR; Uniqueness of Face Recognition: Exploring the Impact of Factors such as image resolution, feature representation, database size, age and gender
Abstract Slides Poster Similar
Gait Recognition Using Multi-Scale Partial Representation Transformation with Capsules
Alireza Sepas-Moghaddam, Saeed Ghorbani, Nikolaus F. Troje, Ali Etemad
Auto-TLDR; Learning to Transfer Multi-scale Partial Gait Representations using Capsule Networks for Gait Recognition
Abstract Slides Poster Similar
3D Facial Matching by Spiral Convolutional Metric Learning and a Biometric Fusion-Net of Demographic Properties
Soha Sadat Mahdi, Nele Nauwelaers, Philip Joris, Giorgos Bouritsas, Imperial London, Sergiy Bokhnyak, Susan Walsh, Mark Shriver, Michael Bronstein, Peter Claes

Auto-TLDR; Multi-biometric Fusion for Biometric Verification using 3D Facial Mesures
Generalized Iris Presentation Attack Detection Algorithm under Cross-Database Settings
Mehak Gupta, Vishal Singh, Akshay Agarwal, Mayank Vatsa, Richa Singh

Auto-TLDR; MVNet: A Deep Learning-based PAD Network for Iris Recognition against Presentation Attacks
Abstract Slides Poster Similar
Rethinking ReID:Multi-Feature Fusion Person Re-Identification Based on Orientation Constraints
Mingjing Ai, Guozhi Shan, Bo Liu, Tianyang Liu

Auto-TLDR; Person Re-identification with Orientation Constrained Network
Abstract Slides Poster Similar
Part-Based Collaborative Spatio-Temporal Feature Learning for Cloth-Changing Gait Recognition
Lingxiang Yao, Worapan Kusakunniran, Qiang Wu, Jian Zhang, Jingsong Xu

Auto-TLDR; Part-based Spatio-Temporal Feature Learning for Gait Recognition
Abstract Slides Poster Similar
Magnifying Spontaneous Facial Micro Expressions for Improved Recognition
Pratikshya Sharma, Sonya Coleman, Pratheepan Yogarajah, Laurence Taggart, Pradeepa Samarasinghe

Auto-TLDR; Eulerian Video Magnification for Micro Expression Recognition
Abstract Slides Poster Similar
SoftmaxOut Transformation-Permutation Network for Facial Template Protection
Hakyoung Lee, Cheng Yaw Low, Andrew Teoh

Auto-TLDR; SoftmaxOut Transformation-Permutation Network for C cancellable Biometrics
Abstract Slides Poster Similar
Multi-Scale Keypoint Matching

Auto-TLDR; Multi-Scale Keypoint Matching Using Multi-Scale Information
Abstract Slides Poster Similar
Wireless Localisation in WiFi Using Novel Deep Architectures
Peizheng Li, Han Cui, Aftab Khan, Usman Raza, Robert Piechocki, Angela Doufexi, Tim Farnham

Auto-TLDR; Deep Neural Network for Indoor Localisation of WiFi Devices in Indoor Environments
Abstract Slides Poster Similar
RobusterNet: Improving Copy-Move Forgery Detection with Volterra-Based Convolutions
Efthimia Kafali, Nicholas Vretos, Theodoros Semertzidis, Petros Daras
Auto-TLDR; Convolutional Neural Networks with Nonlinear Inception for Copy-Move Forgery Detection
Joint Compressive Autoencoders for Full-Image-To-Image Hiding
Xiyao Liu, Ziping Ma, Xingbei Guo, Jialu Hou, Lei Wang, Gerald Schaefer, Hui Fang

Auto-TLDR; J-CAE: Joint Compressive Autoencoder for Image Hiding
Abstract Slides Poster Similar
Two-Level Attention-Based Fusion Learning for RGB-D Face Recognition
Hardik Uppal, Alireza Sepas-Moghaddam, Michael Greenspan, Ali Etemad

Auto-TLDR; Fused RGB-D Facial Recognition using Attention-Aware Feature Fusion
Abstract Slides Poster Similar
Creating Classifier Ensembles through Meta-Heuristic Algorithms for Aerial Scene Classification
Álvaro Roberto Ferreira Jr., Gustavo Gustavo Henrique De Rosa, Joao Paulo Papa, Gustavo Carneiro, Fabio Augusto Faria

Auto-TLDR; Univariate Marginal Distribution Algorithm for Aerial Scene Classification Using Meta-Heuristic Optimization
Abstract Slides Poster Similar
Visual Localization for Autonomous Driving: Mapping the Accurate Location in the City Maze
Dongfang Liu, Yiming Cui, Xiaolei Guo, Wei Ding, Baijian Yang, Yingjie Chen

Auto-TLDR; Feature Voting for Robust Visual Localization in Urban Settings
Abstract Slides Poster Similar